Identifier les cultures irriguées actives
Produits utilisés : ls8_st, ls8_sr, crop_mask, ERA5 Climate Data
Mots-clés données utilisées ; landsat 8, ensembles de données ; landsat 8, température de surface, données utilisées ; ERA5, ensembles de données ; ERA5, climat, température
Aperçu
L’une des mesures les plus connues de la santé des plantes est la température du couvert végétal. Dans des conditions de manque d’eau, on peut supposer que la transpiration diminue et que la température des plantes augmente par la suite. Cela peut souvent se produire pendant les périodes de stress hydrique dans les systèmes de culture en sec (pluie), mais peut être surmonté par l’application d’eau dans les systèmes de culture irrigués.
Sur le terrain, les températures de la canopée peuvent être mesurées à l’aide de radiomètres portables. Ce type de données est utilisé à petite échelle pour examiner la santé et le rendement des cultures dans diverses conditions. À plus grande échelle, une méthode alternative consiste à utiliser la température de surface détectée par des satellites tels que Landsat 8 pour calculer des mesures similaires. Dans ce carnet, nous utiliserons \(\Delta T\) pour faire la différence entre les terres arides et les terres irriguées, où \(\Delta T\) est :
\begin{equation} \Delta T = T_c - T_a \end{equation}
où
\(T_c\) est la température du couvert végétal des cultures
\(T_a\) est la température de l’air
Un \(\Delta T\) plus faible est associé à des taux de transpiration plus élevés, car le refroidissement par évaporation dû à la transpiration refroidit la canopée, tandis qu’un \(\Delta T\) plus élevé indique des taux de transpiration plus faibles et donc un stress hydrique.
Dans ce cas, nous utiliserons les mesures de la température de l’air modélisées par ERA5 pour approximer \(T_a\) et le produit de température de surface Landsat pour approximer \(T_c\).
Description
Dans ce notebook, nous calculons \(\Delta T\) et visualisons les zones irriguées.
Les mesures suivantes sont prises :
Charger les données de température de surface de Landsat 8
Charger les données ERA5 « Température de l’air à 2 mètres » pour la même zone d’intérêt
Calculer \(\Delta T\)
Visualiser \(\Delta T\)
Utiliser une analyse de cluster simple pour différencier les cultures irriguées et les cultures sèches.
Cartographier les cultures irriguées dans la zone d’intérêt.
Charger des paquets
[1]:
%matplotlib inline
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
import datacube
import numpy as np
import xarray as xr
import geopandas as gpd
import matplotlib.pyplot as plt
from odc.geo.xr import xr_reproject
from matplotlib.colors import ListedColormap
from deafrica_tools.load_era5 import load_era5
from deafrica_tools.datahandling import load_ard, mostcommon_crs
from deafrica_tools.plotting import rgb, display_map
from odc.geo.geom import Geometry
from deafrica_tools.bandindices import calculate_indices
from deafrica_tools.classification import sklearn_flatten, sklearn_unflatten
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from deafrica_tools.areaofinterest import define_area
Se connecter au datacube
[2]:
dc = datacube.Datacube(app="Landsat_ST")
Paramètres d’analyse
Cette analyse porte sur les terres cultivées au Soudan. La partie occidentale de la zone d’intérêt semble irriguée, car elle est desservie par des canaux à y regarder de plus près, et la végétation y est plus verte que les éléments du paysage environnant. La partie orientale de la zone est principalement consacrée à la culture en sec.
Sélectionnez l’emplacement
Pour définir la zone d’intérêt, deux méthodes sont disponibles :
En spécifiant la latitude, la longitude et la zone tampon. Cette méthode nécessite que vous saisissiez la latitude centrale, la longitude centrale et la valeur de la zone tampon en degrés carrés autour du point central que vous souhaitez analyser. Par exemple, « lat = 10,338 », « lon = -1,055 » et « buffer = 0,1 » sélectionneront une zone avec un rayon de 0,1 degré carré autour du point avec les coordonnées (10,338, -1,055).
Vous pouvez également fournir des valeurs de tampon distinctes pour la latitude et la longitude d’une zone rectangulaire. Par exemple, « lat = 10.338 », « lon = -1.055 » et « lat_buffer = 0.1 » et « lon_buffer = 0.08 » sélectionneront une zone rectangulaire s’étendant sur 0,1 degré au nord et au sud et 0,08 degré à l’est et à l’ouest à partir du point « (10.338, -1.055) ».
Pour des temps de chargement raisonnables, définissez la mémoire tampon sur « 0,1 » ou moins.
By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
Pour utiliser l’une de ces méthodes, vous pouvez décommenter la ligne de code concernée et commenter l’autre. Pour commenter une ligne, ajoutez le symbole "#" avant le code que vous souhaitez commenter. Par défaut, la première option qui définit l’emplacement à l’aide de la latitude, de la longitude et du tampon est utilisée.
[3]:
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=13.8489, lon=33.822, buffer=0.125)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
# aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# Set the range of dates for the analysis
time = ("2018-01-01", "2019-12-31")
time = ("2019-06", "2019-11")
measurements = ["surface_temperature"]
Afficher l’emplacement sélectionné
[4]:
display_map(lon_range, lat_range)
[4]:
Charger les données de température de surface de Landsat 8
[5]:
ds_land = load_ard(
dc=dc,
products=["ls8_st"],
x=lon_range,
y=lat_range,
time=time,
measurements=measurements,
skip_broken_datasets=True,
output_crs="EPSG:6933",
mask_filters=[("opening", 5), ("dilation", 5)], # improve cloud-mask
resolution=(-30, 30),
)
print(ds_land)
Using pixel quality parameters for USGS Collection 2
Finding datasets
ls8_st
Applying morphological filters to pq mask [('opening', 5), ('dilation', 5)]
Applying pixel quality/cloud mask
Re-scaling Landsat C2 data
Loading 24 time steps
<xarray.Dataset> Size: 80MB
Dimensions: (time: 24, y: 1034, x: 805)
Coordinates:
* time (time) datetime64[ns] 192B 2019-06-05T08:03:16.92750...
* y (y) float64 8kB 1.766e+06 1.766e+06 ... 1.735e+06
* x (x) float64 6kB 3.251e+06 3.251e+06 ... 3.275e+06
spatial_ref int32 4B 6933
Data variables:
surface_temperature (time, y, x) float32 80MB nan nan nan ... 324.5 324.4
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
Convertir en degrés Celsius et rééchantillonner en moyennes annuelles
[6]:
# convert from Kelvin to Celsius
celcius_kelvin_offset = 273.15
ds_land["surface_temperature"] = ds_land.surface_temperature - celcius_kelvin_offset
# Annual surface land temp
ds_land = ds_land.mean("time")
[7]:
# plot
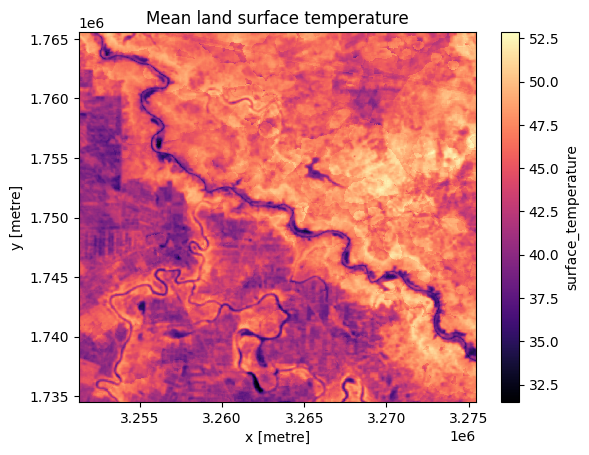
ds_land.surface_temperature.plot.imshow(cmap="magma")
plt.title("Mean land surface temperature");
Charger les données de température de l’air ERA5
Alors que Landsat 8 observera un emplacement donné une fois tous les quelques jours, ERA5 fournit des observations horaires. Ainsi, l’étape suivante calcule la température moyenne mensuelle de l’air à partir d’ERA5, en utilisant les arguments « resample » et « reduce_func ». La fonction load_era5 renvoie la température en Kelvin, elle doit donc être convertie en Celsius en utilisant le décalage.
Après avoir calculé cela, la dernière étape consiste à prendre la moyenne des moyennes mensuelles pour obtenir une température moyenne saisonnière de l’air, qui sera utilisée pour l’analyse.
[8]:
# load ERA5 air temperature at 2m height, resampled to monthly means
var = "air_temperature_at_2_metres"
ds_air = (
load_era5(var, lat_range, lon_range, time, resample="1MS", reduce_func=np.mean)[var]
- celcius_kelvin_offset
)
ds_air = ds_air.compute() # bring into memory
# rename dimensions to match landsat
ds_air = ds_air.rename({"lon": "x", "lat": "y"})
# Seasonal mean air temp
ds_air = ds_air.mean("time")
Opening ERA5 Zarr dataset...
Variable: air_temperature_at_2_metres
Mapped ERA5 name: 2m_temperature
Time: 2019-06-01 to 2019-11-01
Latitude: 13.7239 to 13.9739
Longitude: 33.697 to 33.947
Selecting time range...
Normalising longitude coordinates...
Selecting AOI...
Subset size: {'time': 3696, 'latitude': 2, 'longitude': 2}
Resampling to 1MS using <function mean at 0x7f16c819b9c0>...
ERA5 loading complete.
[9]:
# plot
ds_air.plot.imshow(cmap="viridis")
plt.title("Mean air surface temperature");
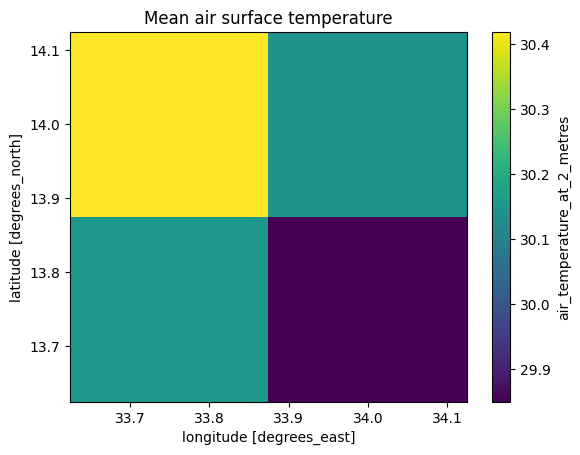
Les graphiques ci-dessus montrent que les données ont été chargées correctement. Notez que ERA5 a une résolution spatiale bien inférieure à celle de Landsat 8 (environ 31 km contre 30 m) mais a une résolution temporelle bien supérieure.
On s’attend également à ce que la température terrestre soit supérieure à la température de l’air à 2 mètres.
Notez que la température terrestre estimée par Landsat 8 peut sembler assez élevée ; ici, elle est indiquée à plus de 40 °C. Dans ce carnet, nous n’avons pas les moyens de valider l’ensemble de données, il est donc difficile de dire si les relevés sont exacts ou exagérés en raison d’une erreur d’instrumentation inhérente. Quoi qu’il en soit, cela est atténué par \(\Delta T\) qui examine la différence entre les températures au lieu des valeurs absolues.
Calculer \(\Delta T\)
Comme indiqué dans l’introduction, pour cet exercice, nous estimons \(\Delta T\) en utilisant les ensembles de données de température chargés au lieu des données in situ. Cela peut être décomposé selon les étapes suivantes :
Rééchantillonnez la température de l’air pour qu’elle corresponde à la résolution spatiale de Landsat. Cela se fait à l’aide de la fonction « xr_reproject ».
Calculer la différence (\(\Delta T\)) entre \(T_c\) (température du sol) et \(T_a\) (température de l’air)
[10]:
ds_air = xr_reproject(src=ds_air, how=ds_land.geobox, resampling="nearest")
Calculer \(\Delta T\):
[11]:
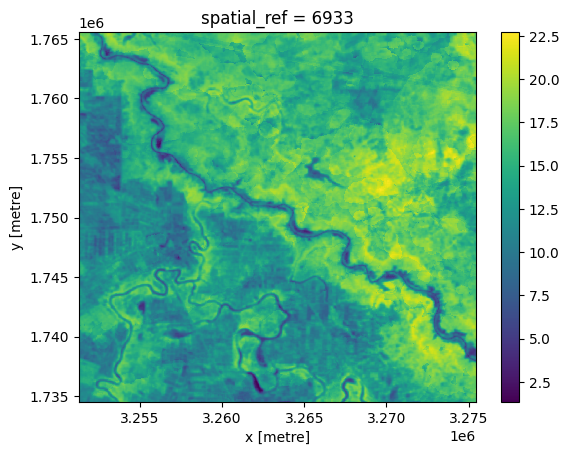
deltat = ds_land.surface_temperature - ds_air
[12]:
deltat.plot.imshow();
Charger les données de réflectance de surface Landsat-8 et calculer le NDVI
[13]:
ds_ndvi = load_ard(
dc=dc,
products=["ls8_sr"],
like=ds_land.geobox,
time=time,
skip_broken_datasets=True,
measurements=["red", "nir"],
)
ds_ndvi = calculate_indices(ds_ndvi, index="NDVI", satellite_mission="ls", drop=True)
Using pixel quality parameters for USGS Collection 2
Finding datasets
ls8_sr
Applying pixel quality/cloud mask
Re-scaling Landsat C2 data
Loading 24 time steps
Dropping bands ['red', 'nir']
[14]:
ds_ndvi = ds_ndvi.median("time").squeeze()
[15]:
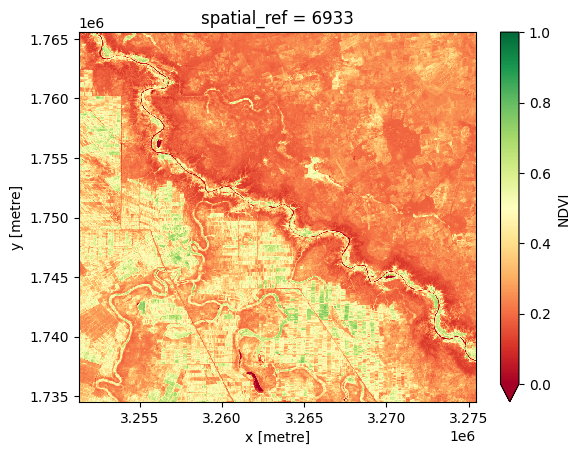
ds_ndvi.NDVI.plot.imshow(cmap="RdYlGn", vmin=0, vmax=1);
Utilisez le produit Cropland extent pour masquer les régions de culture
Nous pouvons utiliser \(\Delta T\) pour différencier les cultures irriguées et sèches, mais pour ce faire, nous devons limiter notre analyse aux terres cultivées et exclure d’autres caractéristiques du paysage. Nous pouvons le faire en utilisant le produit d’étendue des terres cultivées, que nous chargeons ci-dessous.
Charger le masque de recadrage
[16]:
cm = dc.load(
product="crop_mask", time="2019", measurements="filtered", like=ds_ndvi.geobox
).filtered.squeeze()
[17]:
deltat = deltat.where(cm==1)
ds_ndvi = ds_ndvi.where(cm==1)
[18]:
ds_ndvi.NDVI.plot.imshow(cmap="RdYlGn", vmin=0, vmax=1);
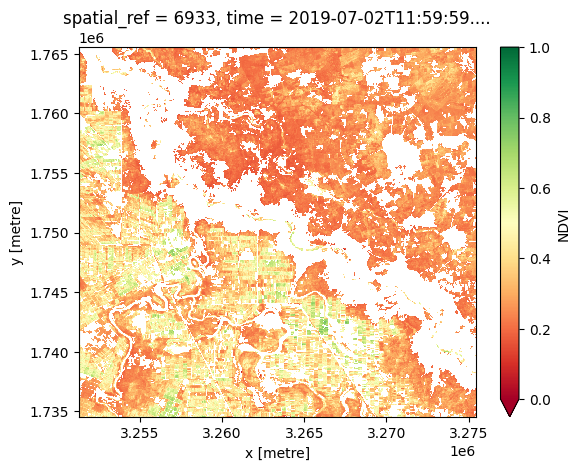
Identifier les groupes pour la classification
Nous avons deux variables (NDVI et \(\Delta T\)) que nous aimerions utiliser pour séparer les terres arides et les terres cultivées irriguées.
Nous pouvons utiliser une technique de clustering pour affecter les données à ces classes. Dans ce cas, nous utiliserons le clustering k-means pour identifier deux clusters (irrigué et pluvial).
Les deux variables ayant des unités très différentes, nous devrons les redimensionner avant d’exécuter l’analyse de cluster. Ceci est illustré dans la cellule ci-dessous.
[19]:
# flatten the two predictors into 1-D arrays
ndvi_flat = sklearn_flatten(ds_ndvi.NDVI)
deltat_flat = sklearn_flatten(deltat)
# combine the two arrays for passing into kmeans
X = np.stack((ndvi_flat, deltat_flat), axis=0).transpose()
# rescale variables for cluster analysis
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# perform kmeans cluster analysis, specifying we are looking for two clusters
kmeans = KMeans(n_clusters=2, random_state=0)
kmeans.fit(X_scaled)
y_kmeans = kmeans.predict(X_scaled)
# create a lookup table for the clusters so results are reproducible
idx = np.argsort(kmeans.cluster_centers_.sum(axis=1))
lut = np.zeros_like(idx)
lut[idx] = np.arange(2)
kmeans.labels_ = lut[kmeans.labels_]
Tracer les clusters
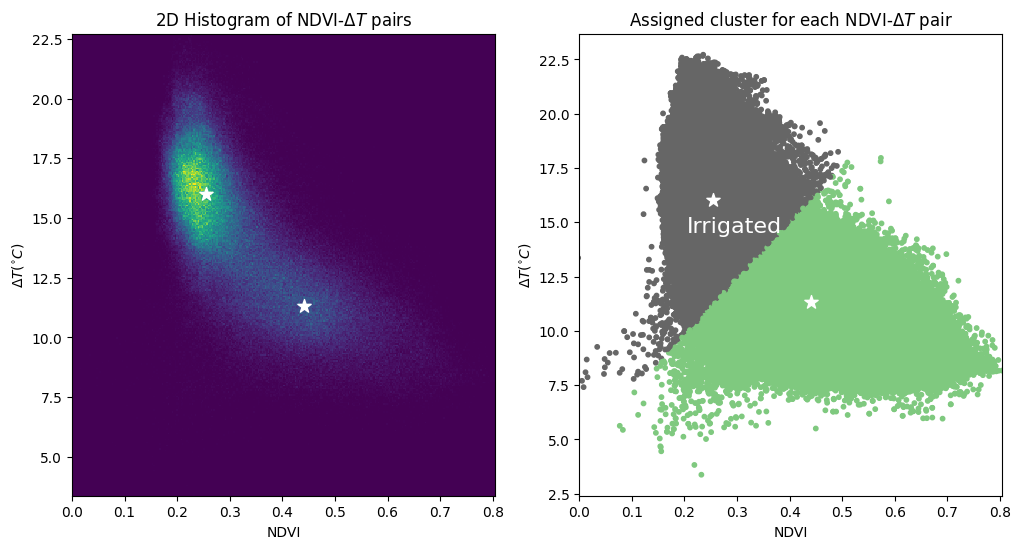
Le graphique ci-dessous montre l’histogramme 2D des paires NDVI-\(\Delta T\) (transmettant la densité des points), ainsi qu’un graphique de dispersion montrant à quel groupe chaque paire a été affectée. Les deux graphiques affichent le centre de chaque groupe.
La densité montre deux groupes distincts que l’algorithme k-means a identifiés dans les données. Nous supposons que le groupe en bas à droite (NDVI plus élevé et Delta T plus faible) est celui des terres cultivées irriguées.
[20]:
# Get locations of kmeans cluster centres
centers_scaled = kmeans.cluster_centers_
centers = scaler.inverse_transform(centers_scaled)
# Construct the figure
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6))
ax1.hist2d(X[:, 0], X[:, 1], bins=(300, 300), cmap="viridis")
ax1.scatter(centers[:, 0], centers[:, 1], c="white", s=100, marker="*")
ax1.set_xlim(0, ds_ndvi.NDVI.max())
ax1.set_xlabel("NDVI")
ax1.set_ylabel("$\Delta T (^{\circ} C)$")
ax1.set_title("2D Histogram of NDVI-$\Delta T$ pairs")
ax2.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=10, cmap="Accent")
ax2.scatter(centers[:, 0], centers[:, 1], c="white", s=100, marker="*")
ax2.set_xlim(0, ds_ndvi.NDVI.max())
ax2.set_xlabel("NDVI")
ax2.set_ylabel("$\Delta T (^{\circ} C)$")
ax2.text(
centers[1, 0] - 0.05, centers[1, 1] - 1.5, "Irrigated", fontsize=16, color="white"
)
ax2.set_title("Assigned cluster for each NDVI-$\Delta T$ pair")
plt.show()
Appliquer des clusters aux données spatiales
[21]:
# use kmeans to predict which cluster each observation belongs to
preds_flat = kmeans.predict(X_scaled)
# unflatten predictions to return it to spatial dimensions
preds = sklearn_unflatten(preds_flat, ds_ndvi)
# irrigated (c) where cropland is true and cluster = 0
c = xr.where((cm == 1) & (preds == 1), 2, cm)
Chargez le géomédian semestriel pour comparer la classification à une image en couleurs réelles.
[22]:
gm = dc.load(
product="gm_s2_semiannual",
like=cm.geobox,
time=time,
measurements=["red", "green", "blue"],
).squeeze()
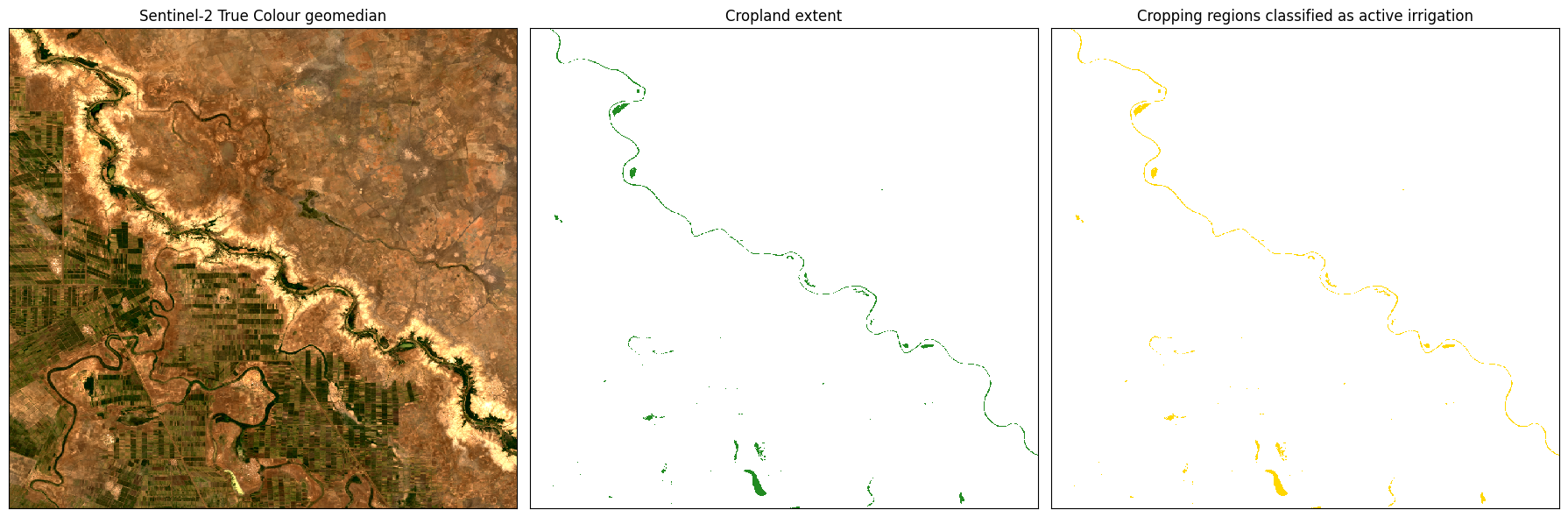
Résultat de l’intrigue
Ce qui suit produit un graphique à trois panneaux, montrant la géomédiane pour référence, puis l’étendue totale des terres cultivées et enfin, les zones classées comme irrigation active en jaune.
[23]:
colours = ["white", "forestgreen", "gold"]
fig, ax = plt.subplots(1, 3, figsize=(18, 6), sharey=True)
# Geomedian
rgb(gm, index=1, ax=ax[0])
ax[0].set_title("Sentinel-2 True Colour geomedian")
# Cropland extent
cm.plot(ax=ax[1], add_colorbar=False, cmap=ListedColormap(colours[0:2]))
ax[1].set_title("Cropland extent")
# Irrigated cropping
c.plot(ax=ax[2], add_colorbar=False, cmap=ListedColormap(colours))
ax[2].set_title("Cropping regions classified as active irrigation")
# Turn axis ticks and labels off on all axes
for axis in ax:
axis.set_xticks([])
axis.set_yticks([])
axis.set_xlabel("")
axis.set_ylabel("")
plt.tight_layout();
Limites
Cette méthode de calcul de \(\Delta T\) repose sur plusieurs hypothèses clés :
La température de l’air est raisonnablement estimée par ERA5
La température terrestre est raisonnablement estimée par la température de surface de Landsat 8
La différenciation par groupement des cultures irriguées et des cultures sèches repose sur la relation entre ces deux caractéristiques et ces variables. Cette approche peut s’avérer moins efficace dans certains scénarios, tels que :
Saisons humides où les cultures sèches connaissent de faibles niveaux de stress hydrique et une canopée très verte.
Les périodes froides où \(\Delta T\) peuvent ne pas être un bon indicateur du stress hydrique des cultures.
Comme toujours, les résultats doivent être interprétés avec contexte et soin.
Références
Jackson, Ray D., Kustas, William P. et Choudhury, Bhaskar J. 1988. « Un réexamen de l’indice de stress hydrique des cultures ». Irrig Sci 9:309-317
Informations Complémentaires
Licence Le code de ce notebook est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>`__.
Les données de Digital Earth Africa sont sous licence Creative Commons Attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack DE Africa <https://digitalearthafrica.slack.com/> ou sur le GIS Stack Exchange <https://gis.stackexchange.com/questions/ask?tags=open-data-cube> en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment `ici <https://gis.stackexchange.com/questions/tagged/open-data-
Si vous souhaitez signaler un problème avec ce notebook, vous pouvez en déposer un sur Github.
Version de Datacube compatible
[24]:
print(datacube.__version__)
1.9.13
Dernier test :
[25]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[25]:
'2026-04-30'