Phénologie de la végétation par radar avec Sentinel-1
Mots clés données utilisées ; sentinelle-1, données utilisées ; crop_mask, indice de bande ; RVI, phénologie, analyse ; séries chronologiques
Aperçu
La phénologie est l’étude des cycles de vie des plantes et des animaux dans le contexte des saisons. Elle peut être utile pour comprendre les tendances du cycle de vie des cultures et la manière dont les saisons de croissance sont affectées par les changements climatiques. Cependant, dans les régions nuageuses, les satellites optiques peuvent ne pas visualiser le cycle de végétation pendant les moments clés de la croissance (par exemple pendant le pic de la saison de croissance), ce qui conduit à des estimations inexactes des variables de phénologie de la végétation. Le satellite radar Sentinel-1 « voit » à travers les nuages et peut, en théorie, visualiser l’intégralité du cycle de vie des plantes. Ce carnet utilisera Sentinel-1 pour dériver des statistiques phénologiques clés. Vous pouvez comparer ces résultats avec les résultats du carnet de phénologie de la végétation Sentinel-2 <Phenology_optical.ipynb>`__ qui s’appuie sur des données optiques pour calculer la phénologie sur la même région que ce carnet
Description
Ce bloc-notes montre comment calculer les statistiques de phénologie de la végétation sur les régions de culture en utilisant la fonction DE Africa xr_phenology. Pour détecter les changements dans la vie végétale pour Sentinel-1, le script utilise l”indice de végétation radar
Les résultats de ce carnet peuvent être utilisés pour évaluer les différences spatio-temporelles dans les saisons de croissance des champs agricoles ou de la végétation indigène.
Ce cahier illustre les étapes suivantes :
Chargez les données Sentinel 1 pour une zone d’intérêt.
Masquer la région avec la carte de l’étendue des terres cultivées de l’Afrique de l’Est
Calculer l’indice de végétation radar.
Tracez des images en fausses couleurs de la région.
Calculer l’indice de végétation radar
Lissez la série temporelle de la végétation pour minimiser le bruit.
Calculer les statistiques phénologiques sur une simple série chronologique de végétation 1D
Calculer les statistiques de phénologie par pixel
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Charger des paquets
Chargez les principaux packages Python et les fonctions de support pour l’analyse.
[1]:
%matplotlib inline
import datetime as dt
from datetime import datetime
import os
import datacube
import geopandas as gpd
import matplotlib as mpl
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as AA
import numpy as np
import pandas as pd
from datacube.utils.aws import configure_s3_access
from odc.geo.geom import Geometry
from deafrica_tools.areaofinterest import define_area
from deafrica_tools.bandindices import dualpol_indices
from deafrica_tools.datahandling import load_ard
from deafrica_tools.plotting import display_map, rgb
from deafrica_tools.spatial import xr_rasterize
from deafrica_tools.temporal import xr_phenology
from mpl_toolkits.axes_grid1 import host_subplot
configure_s3_access(aws_unsigned=True, cloud_defaults=True)
Se connecter au datacube
Connectez-vous au datacube pour que nous puissions accéder aux données de DE Africa. Le paramètre « app » est un nom unique pour l’analyse qui est basé sur le nom du fichier du notebook.
[2]:
dc = datacube.Datacube(app="Radar_vegetation_phenology")
Paramètres d’analyse
La cellule suivante définit des paramètres importants pour l’analyse :
« lat » : la latitude centrale à analyser (par exemple « -10,6996 »).
« lon » : la longitude centrale à analyser (par exemple « 35,2708 »).
« buffer » : le nombre de degrés carrés à charger autour de la latitude et de la longitude centrales. Pour des temps de chargement raisonnables, définissez cette valeur sur « 0,1 » ou moins.
time_range: la plage d’années à analyser (par exemple('2019-01', '2020-12')).
Sélectionnez l’emplacement
Pour définir la zone d’intérêt, deux méthodes sont disponibles :
En spécifiant la latitude, la longitude et la zone tampon. Cette méthode nécessite que vous saisissiez la latitude centrale, la longitude centrale et la valeur de la zone tampon en degrés carrés autour du point central que vous souhaitez analyser. Par exemple, « lat = 10,338 », « lon = -1,055 » et « buffer = 0,1 » sélectionneront une zone avec un rayon de 0,1 degré carré autour du point avec les coordonnées (10,338, -1,055).
Vous pouvez également fournir des valeurs de tampon distinctes pour la latitude et la longitude d’une zone rectangulaire. Par exemple, « lat = 10.338 », « lon = -1.055 » et « lat_buffer = 0.1 » et « lon_buffer = 0.08 » sélectionneront une zone rectangulaire s’étendant sur 0,1 degré au nord et au sud et 0,08 degré à l’est et à l’ouest à partir du point « (10.338, -1.055) ».
Pour des temps de chargement raisonnables, définissez la mémoire tampon sur « 0,1 » ou moins.
By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
Pour utiliser l’une de ces méthodes, vous pouvez décommenter la ligne de code concernée et commenter l’autre. Pour commenter une ligne, ajoutez le symbole "#" avant le code que vous souhaitez commenter. Par défaut, la première option qui définit l’emplacement à l’aide de la latitude, de la longitude et du tampon est utilisée.
[3]:
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=8.7186, lon=40.8646, buffer=0.02)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
# aoi = define_area(vector_path='aoi.shp')
# Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# Set the range of dates for the analysis
time_range = ("2019-01-01", "2020-12-20")
#To use crop mask to filter result
use_crop_mask = False
Afficher l’emplacement sélectionné
La cellule suivante affichera la zone sélectionnée sur une carte interactive. N’hésitez pas à zoomer et dézoomer pour mieux comprendre la zone que vous allez analyser. En cliquant sur n’importe quel point de la carte, vous découvrirez les coordonnées de latitude et de longitude de ce point.
[4]:
display_map(x=lon_range, y=lat_range)
[4]:
Charger les données Sentinel-1
La première étape consiste à charger les données Sentinel-1 pour la zone d’intérêt et la plage de temps spécifiées. La fonction « load_ard » est utilisée ici pour charger des données qui ont été masquées à l’aide de filtres de qualité, les rendant ainsi prêtes à être analysées.
[5]:
# Create a reusable query
query = {
"y": lat_range,
"x": lon_range,
"time": time_range,
"measurements": ["vv", "vh"],
"resolution": (-20, 20),
"output_crs": "epsg:6933",
"group_by": "solar_day",
}
# Load available data from Sentinel-1
ds = load_ard(
dc=dc,
products=["s1_rtc"],
**query,
)
print(ds)
Using pixel quality parameters for Sentinel 1
Finding datasets
s1_rtc
Applying pixel quality/cloud mask
Loading 111 time steps
/opt/venv/lib/python3.12/site-packages/rasterio/warp.py:387: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix will be returned.
dest = _reproject(
<xarray.Dataset> Size: 44MB
Dimensions: (time: 111, y: 253, x: 194)
Coordinates:
* time (time) datetime64[ns] 888B 2019-01-01T03:01:22.069586 ... 20...
* y (y) float64 2kB 1.111e+06 1.111e+06 ... 1.106e+06 1.106e+06
* x (x) float64 2kB 3.941e+06 3.941e+06 ... 3.945e+06 3.945e+06
spatial_ref int32 4B 6933
Data variables:
vv (time, y, x) float32 22MB 0.105 0.1644 0.1272 ... 0.2308 0.1722
vh (time, y, x) float32 22MB 0.02471 0.02468 ... 0.03206 0.02134
Attributes:
crs: epsg:6933
grid_mapping: spatial_ref
Découpez les ensembles de données selon la forme de la zone d’intérêt
Un géopolygone représente les limites et non la forme réelle, car il est conçu pour représenter l’étendue de l’entité géographique cartographiée, plutôt que sa forme exacte. En d’autres termes, le géopolygone est utilisé pour définir la limite extérieure de la zone d’intérêt, plutôt que les entités et caractéristiques internes.
Il est important de découper les données selon la forme exacte de la zone d’intérêt, car cela permet de garantir que les données utilisées sont pertinentes pour la zone d’étude spécifique. Bien qu’un géopolygone fournisse des informations sur la limite de l’entité géographique représentée, il ne reflète pas nécessairement la forme ou l’étendue exacte de la zone d’intérêt.
[6]:
# Rasterise the area of interest polygon
aoi_raster = xr_rasterize(gdf=geopolygon_gdf, da=ds, crs=ds.crs)
# Mask the dataset to the rasterised area of interest
ds = ds.where(aoi_raster == 1)
Masquer la région avec la carte de l’étendue des terres cultivées de l’Afrique de l’Est
Chargez le masque de terres cultivées sur la région d’intérêt.
[7]:
if use_crop_mask:
cm = dc.load(
product="crop_mask",
time=("2019"),
measurements="filtered",
resampling="nearest",
like=ds.geobox,
).filtered.squeeze()
cm.where(cm < 255).plot.imshow(
add_colorbar=False, figsize=(6, 6)
) # we filter to <255 to omit missing data
plt.title("Cropland Extent");
Nous allons maintenant utiliser la carte des terres cultivées pour masquer les régions des données Sentinel-1 qui ne contiennent que des cultures.
[8]:
# Filter out the no-data pixels (255) and non-crop pixels (0) from the cropland map and
# mask the Sentinel-1 data.
if use_crop_mask:
ds = ds.where(cm == 1)
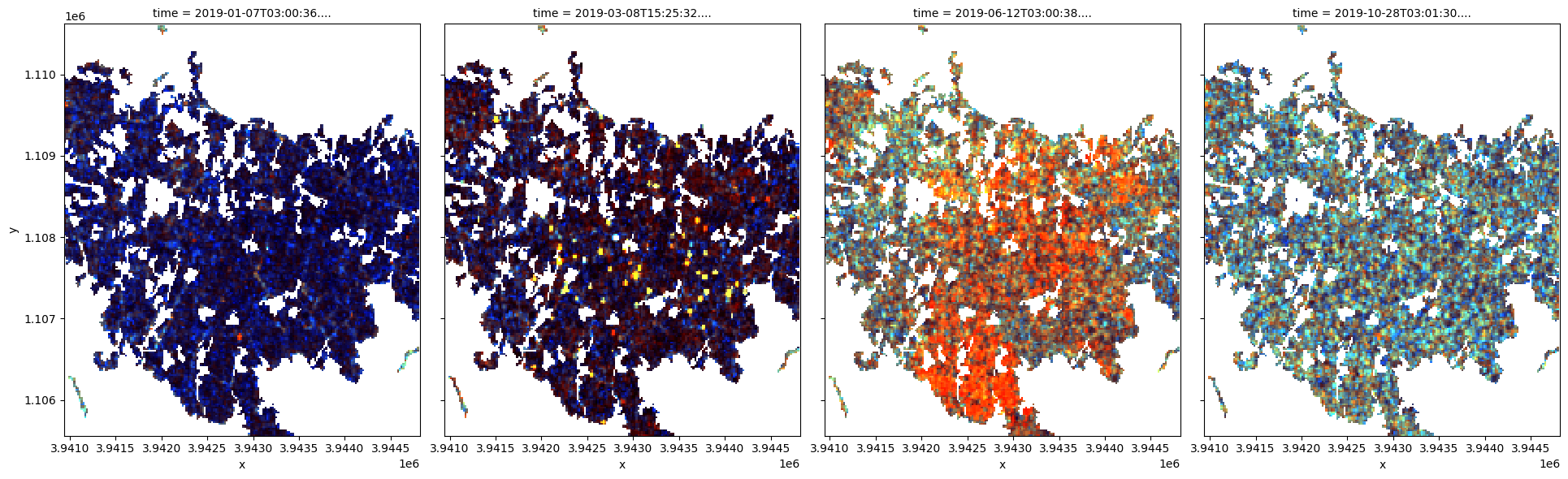
Tracés RVB en fausses couleurs
Il est maintenant possible de représenter graphiquement certaines images Sentinel-1 en fausses couleurs à l’aide de la fonction « rgb ». Notez que l’intensité de la rétrodiffusion des zones de culture change tout au long de l’année à mesure que les plantes des champs traversent leur cycle de croissance et de sénescence.
[9]:
# VH/VV will help create an RGB image
ds["vh/vv"] = ds.vh / ds.vv
# median values are used to scale the measurements so they have a similar range for visualization
med_s1 = ds[["vv", "vh", "vh/vv"]].median()
[10]:
# plotting an RGB image for selected timesteps
time_steps = [1, 10, 22, 45]
rgb(
ds[["vv", "vh", "vh/vv"]] / med_s1, # normalize image ranges
bands=["vv", "vh", "vh/vv"],
index=time_steps,
col_wrap=4,
);
Calculer l’indice de végétation radar
Cette étude mesure la présence de végétation via l”« indice de végétation radar (RVI) ».
La formule est
RVI = 4*VH/(VV+VH)
RVI est disponible via la fonction dualpol_indices, importée depuis deafrica_tools.bandindices.
[11]:
# Calculate the chosen vegetation proxy index and add it to the loaded data set
ds = dualpol_indices(ds, index="RVI")
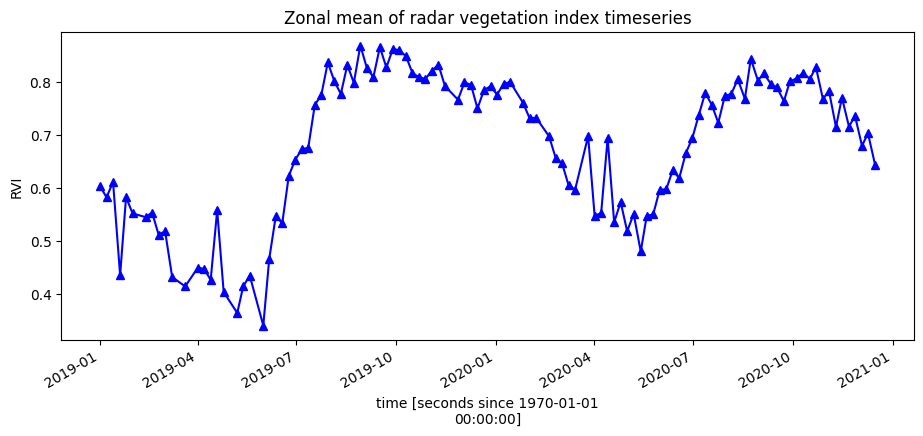
Tracer l’indice de végétation au fil du temps
Pour avoir une idée de l’évolution de la santé de la végétation au cours des années, nous pouvons tracer une série chronologique zonale sur la région d’intérêt. Nous allons d’abord réaliser un tracé simple de la moyenne zonale des données.
[12]:
ds.RVI.mean(["x", "y"]).plot.line("b-^", figsize=(11, 4))
plt.title("Zonal mean of radar vegetation index timeseries");
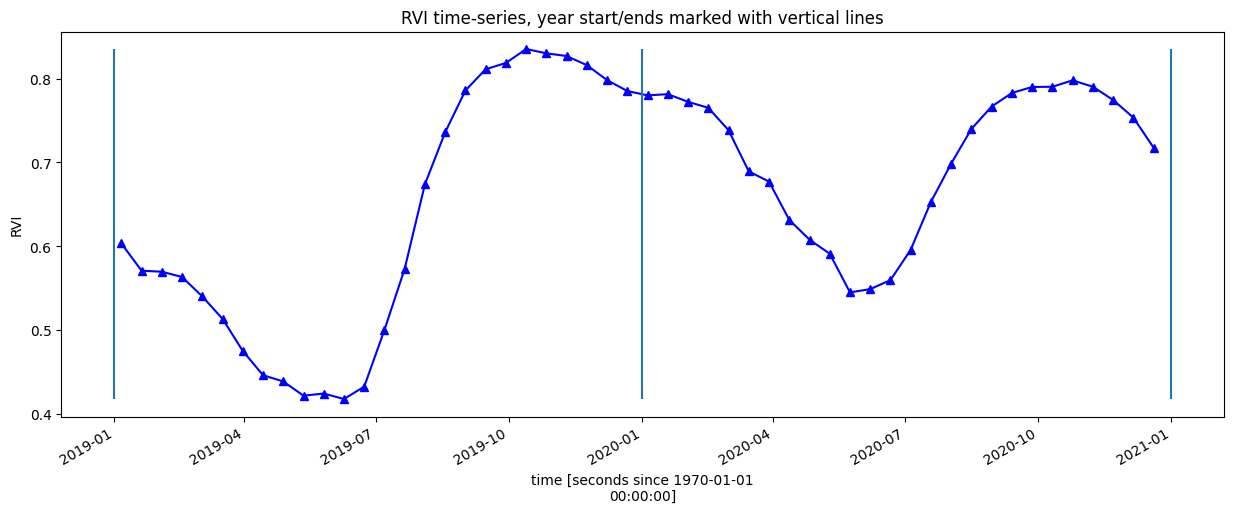
Lissage/interpolation de séries chronologiques de végétation
Ici, nous allons lisser et interpoler les données pour garantir que nous travaillons avec une série chronologique cohérente. Il s’agit d’une étape très importante du flux de travail et il existe de nombreuses façons de lisser, d’interpoler, de combler les lacunes, de supprimer les valeurs aberrantes ou d’ajuster les courbes des données pour garantir une série chronologique utilisable. Si vous n’utilisez pas l’exemple par défaut, vous devrez peut-être définir des méthodes supplémentaires à celles utilisées ici.
Pour ce faire, nous procédons en deux étapes :
Rééchantillonner les données par pas de temps bimensuels en utilisant la médiane bimensuelle
Calculer une moyenne mobile avec une fenêtre de 4 étapes
[13]:
resample_period = "2W"
window = 4
rvi_smooth = (
ds.RVI.resample(time=resample_period)
.median()
.rolling(time=window, min_periods=1)
.mean()
)
Tracer la série chronologique lissée et interpolée
[14]:
rvi_smooth_1D = rvi_smooth.mean(["x", "y"])
rvi_smooth_1D.plot.line("b-^", figsize=(15, 5))
_max = rvi_smooth_1D.max()
_min = rvi_smooth_1D.min()
plt.vlines(np.datetime64("2019-01-01"), ymin=_min, ymax=_max)
plt.vlines(np.datetime64("2020-01-01"), ymin=_min, ymax=_max)
plt.vlines(np.datetime64("2021-01-01"), ymin=_min, ymax=_max)
plt.title("RVI time-series, year start/ends marked with vertical lines")
plt.ylabel("RVI");
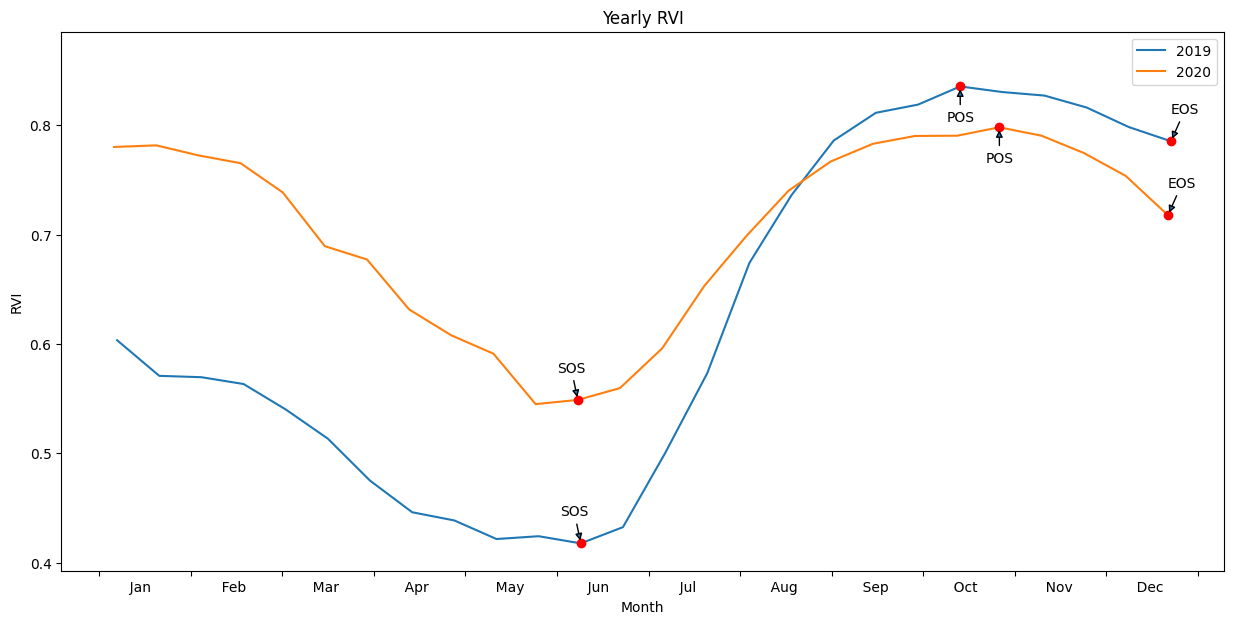
Calculer les statistiques phénologiques à l’aide de « xr_phenology »
La fonction DE Africa « xr_phenology » peut calculer un certain nombre de statistiques sur la phénologie de la surface terrestre qui décrivent ensemble les caractéristiques du cycle de vie d’une plante. La fonction peut calculer les statistiques suivantes soit sur une série temporelle zonale (comme celle ci-dessus), soit sur une base par pixel :
SOS = Date of start of season
POS = Date of peak of season
EOS = Date of end of season
vSOS = Value at start of season
vPOS = Value at peak of season
vEOS = Value at end of season
Trough = Minimum value of season
LOS = Length of season (Days)
AOS = Amplitude of season (in value units)
ROG = Rate of greening
ROS = Rate of senescence
Par défaut, la fonction renverra toutes les statistiques sous la forme d’un « xarray.Dataset », pour renvoyer uniquement un sous-ensemble de ces statistiques, transmettez une liste des statistiques souhaitées à la fonction, par exemple « stats=[“SOS”, “EOS”, “ROG”] ».
Consultez le script deafrica_tools.temporal pour plus d’informations sur chacun des paramètres de xr_phenology.
Statistiques de phénologie zonale
Pour nous aider à comprendre à quoi ces statistiques font référence, passons d’abord la série chronologique moyenne zonale plus simple (moyenne de tous les pixels de l’image) à la fonction et traçons les résultats sur les mêmes courbes que ci-dessus.
Tout d’abord, fournissez une liste de statistiques à calculer avec le paramètre « pheno_stats ».
method_sos : Si “first” alors vSOS est estimé comme la première pente positive du côté verdoyant de la courbe. Si “median”, alors vSOS est estimé comme la valeur médiane des pentes positives du côté verdoyant de la courbe.
method_eos : Si “last” alors vEOS est estimé comme la dernière pente négative du côté sénescent de la courbe. Si “median”, alors vEOS est estimé comme la valeur “médiane” des pentes négatives du côté sénescent de la courbe.
[15]:
pheno_stats = [
"SOS",
"vSOS",
"POS",
"vPOS",
"EOS",
"vEOS",
"Trough",
"LOS",
"AOS",
"ROG",
"ROS",
]
method_sos = "first"
method_eos = "last"
[16]:
# find all the years to assist with plotting
years = rvi_smooth_1D.groupby("time.year")
# store results in dict
pheno_results = {}
# loop through years and calculate phenology
for y, year in years:
# calculate stats
stats = xr_phenology(
year,
method_sos=method_sos,
method_eos=method_eos,
stats=pheno_stats,
verbose=False,
)
# add results to dict
pheno_results[str(y)] = stats
df_dict = {}
for key, value in pheno_results.items():
df_dict_1 = {}
for b in value.data_vars:
if value[b].dtype == np.dtype("<M8[ns]") or value[b].dtype == np.dtype("int16"):
result = pd.to_datetime(value[b].values)
else:
result = round(float(value[b].values), 3)
df_dict_1[b] = result
df_dict[key] = df_dict_1
df = (pd.DataFrame(df_dict)).T
df
[16]:
| SOS | vSOS | POS | vPOS | EOS | vEOS | Trough | LOS | AOS | ROG | ROS | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2019 | 2019-06-23 00:00:00 | 0.523 | 2019-10-13 00:00:00 | 0.813 | 2019-12-22 00:00:00 | 0.768 | 0.519 | 182.0 | 0.294 | 0.003 | -0.001 |
| 2020 | 2020-06-21 00:00:00 | 0.635 | 2020-10-25 00:00:00 | 0.775 | 2020-12-20 00:00:00 | 0.72 | 0.634 | 182.0 | 0.141 | 0.001 | -0.001 |
Tracez les résultats avec nos statistiques annotées sur le graphique
[17]:
# Figure to which the subplot will be added
fig = plt.figure(figsize=(15, 7))
# Create a subplot that can act as a host to parasitic axes
host = host_subplot(111, figure=fig, axes_class=AA.Axes)
# Function to use to edit the axes of the plot
def adjust_axes(ax):
# Set the location of the major and minor ticks.
ax.xaxis.set_major_locator(mpl.dates.MonthLocator())
ax.xaxis.set_minor_locator(mpl.dates.MonthLocator(bymonthday=16))
# Format the major and minor tick labels.
ax.xaxis.set_major_formatter(mpl.ticker.NullFormatter())
ax.xaxis.set_minor_formatter(mpl.dates.DateFormatter("%b"))
# Turn off unnecessary ticks.
ax.axis["bottom"].minor_ticks.set_visible(False)
ax.axis["top"].major_ticks.set_visible(False)
ax.axis["top"].minor_ticks.set_visible(False)
ax.axis["right"].major_ticks.set_visible(False)
ax.axis["right"].minor_ticks.set_visible(False)
# Find all the years to assist with plotting
years = rvi_smooth_1D.groupby("time.year")
# Counter to aid in plotting.
counter = 0
for y, year in years:
# Grab all the values we need for plotting.
eos = df.loc[str(y)].EOS
sos = df.loc[str(y)].SOS
pos = df.loc[str(y)].POS
veos = df.loc[str(y)].vEOS
vsos = df.loc[str(y)].vSOS
vpos = df.loc[str(y)].vPOS
if counter == 0:
ax = host
else:
# Create the secondary axis.
ax = host.twiny()
# Plot the data
year.plot(ax=ax, label=y)
# add start of season
ax.plot(sos, vsos, "or")
ax.annotate(
"SOS",
xy=(sos, vsos),
xytext=(-15, 20),
textcoords="offset points",
arrowprops=dict(arrowstyle="-|>"),
)
# add end of season
ax.plot(eos, veos, "or")
ax.annotate(
"EOS",
xy=(eos, veos),
xytext=(0, 20),
textcoords="offset points",
arrowprops=dict(arrowstyle="-|>"),
)
# add peak of season
ax.plot(pos, vpos, "or")
ax.annotate(
"POS",
xy=(pos, vpos),
xytext=(-10, -25),
textcoords="offset points",
arrowprops=dict(arrowstyle="-|>"),
)
# Set the x-axis limits
min_x = dt.date(y, 1, 1)
max_x = dt.date(y, 12, 31)
ax.set_xlim(min_x, max_x)
adjust_axes(ax)
counter += 1
host.legend(labelcolor="linecolor")
host.set_ylim([_min - 0.025, _max.values + 0.05])
plt.xlabel("Month")
plt.ylabel("RVI")
plt.title("Yearly RVI");
Statistiques de phénologie par pixel
Nous pouvons maintenant calculer les statistiques pour chaque pixel de notre série chronologique et tracer les résultats.
[18]:
# find all the years to assist with plotting
years = rvi_smooth.groupby("time.year")
# get list of years in ts to help with looping
years_int = [y[0] for y in years]
# store results in dict
pheno_results = {}
# loop through years and calculate phenology
for year in years_int:
# select year
da = dict(years)[year]
# calculate stats
stats = xr_phenology(
da,
method_sos=method_sos,
method_eos=method_eos,
stats=pheno_stats,
verbose=False,
)
# add results to dict
pheno_results[str(year)] = stats
Les statistiques phénologiques ont été calculées séparément pour chaque pixel de l’image. Représentons chacun d’eux pour voir les résultats.
Ci-dessous, choisissez une année parmi les résultats phénologiques à tracer.
[19]:
# Pick a year to plot
year_to_plot = "2019"
En haut du code de traçage, nous re-masquons les résultats de phénologie avec le masque de recadrage. En effet, xr_phenologypossède des méthodes pour gérer les pixels avec uniquement des NaN (comme les régions en dehors du masque de polygone), de sorte que les résultats peuvent avoir des résultats de phénologie pour les régions en dehors du masque. Nous devrons donc masquer à nouveau les données.
[20]:
# select the year to plot
phen = pheno_results[year_to_plot]
# Define a few items to aid in plotting.
start_date = dt.date(int(year_to_plot), 1, 1)
end_date = dt.date(int(year_to_plot), 10, 27)
date_list = pd.date_range(start_date, end_date, freq="MS")
bounds = [int(i.strftime("%Y%m%d")) for i in date_list]
@mpl.ticker.FuncFormatter
def float_to_date(x, pos):
tick_str = str(int(x))
year = tick_str[:4]
month = tick_str[4:6]
day = tick_str[6:]
return f"{year}-{month}-{day}"
# set up figure
fig, ax = plt.subplots(nrows=2,
ncols=5,
figsize=(18, 8),
sharex=True,
sharey=True)
# set colorbar size
cbar_size = 0.7
# set aspect ratios
for a in fig.axes:
a.set_aspect("equal")
# start of season
# Convert SOS values from np.date64 to float values for plotting
cax = phen.POS.dt.dayofyear.plot(
ax=ax[0, 0],
cmap="magma_r",
add_colorbar=True,
cbar_kwargs=dict(shrink=cbar_size, label=None),
)
ax[0, 0].set_title("Start of Season")
phen.vSOS.plot(ax=ax[0, 1],
cmap="YlGn",
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 1].set_title("RVI at SOS")
# peak of season
# # Convert POS values from np.date64 to float values for plotting
cax = phen.POS.dt.dayofyear.plot(
ax=ax[0, 2],
cmap="magma_r",
add_colorbar=True,
cbar_kwargs=dict(shrink=cbar_size, label=None),
)
ax[0, 2].set_title("Peak of Season")
phen.vPOS.plot(ax=ax[0, 3],
cmap="YlGn",
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 3].set_title("RVI at POS")
# end of season
# Convert EOS values from np.date64 to float values for plotting
cax = phen.EOS.dt.dayofyear.plot(
ax=ax[0, 4],
cmap="magma_r",
add_colorbar=True,
cbar_kwargs=dict(shrink=cbar_size, label=None),
)
ax[0, 4].set_title("End of Season")
phen.vEOS.plot(ax=ax[1, 0],
cmap="YlGn",
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 0].set_title("RVI at EOS")
# Length of Season
phen.LOS.plot(
ax=ax[1, 1],
cmap="magma_r",
vmax=300,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None),
)
ax[1, 1].set_title("Length of Season (Days)")
# Amplitude
phen.AOS.plot(ax=ax[1, 2],
cmap="YlGn",
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 2].set_title("Amplitude of Season")
# rate of growth
phen.ROG.plot(
ax=ax[1, 3],
cmap="coolwarm_r",
vmin=-0.02,
vmax=0.02,
cbar_kwargs=dict(shrink=cbar_size, label=None),
)
ax[1, 3].set_title("Rate of Growth")
# rate of Sensescence
phen.ROS.plot(
ax=ax[1, 4],
cmap="coolwarm_r",
vmin=-0.02,
vmax=0.02,
cbar_kwargs=dict(shrink=cbar_size, label=None),
)
ax[1, 4].set_title("Rate of Senescence")
plt.suptitle("Phenology for " + year_to_plot)
plt.tight_layout();
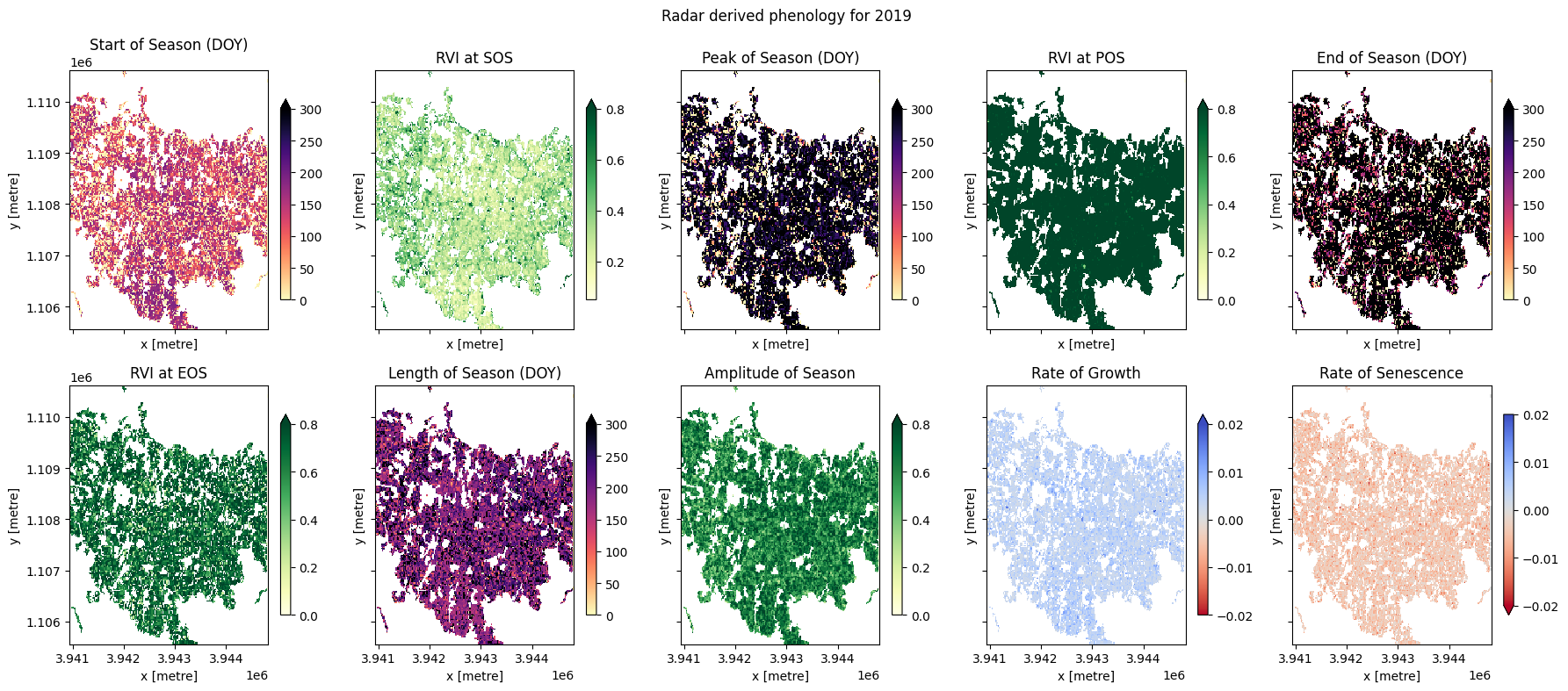
Conclusions
Dans l’exemple ci-dessus, nous pouvons voir que la plupart des champs suivent un calendrier de culture similaire et sont donc probablement constitués de la même espèce de culture. Nous pouvons également observer que certains champs n’ont pas suivi ce calendrier (par exemple, le graphique EOY montre que certains champs n’ont pas suivi ce calendrier, probablement parce qu’ils sont restés en jachère pendant l’année, ou parce qu’il y a eu deux pics au cours de l’année qui ont pu perturber les statistiques phénologiques). Les différences dans les taux de croissance et dans les valeurs de RVI à différents moments de la saison peuvent être attribuables à des différences de qualité du sol, d’intensité d’arrosage ou d’autres pratiques agricoles.
Les statistiques phénologiques sont un moyen efficace de résumer le cycle saisonnier de la vie d’une plante. Les graphiques par pixel de la phénologie peuvent nous aider à comprendre le calendrier de croissance et de perception de la végétation sur de grandes surfaces et sur diverses espèces végétales, car chaque pixel est traité comme une série indépendante d’observations. Cela pourrait être important, par exemple, si nous voulions évaluer comment les saisons de croissance évoluent à mesure que le climat se réchauffe.
Informations Complémentaires
Licence Le code de ce notebook est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>`__.
Les données de Digital Earth Africa sont sous licence Creative Commons Attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack DE Africa <https://digitalearthafrica.slack.com/> ou sur le GIS Stack Exchange <https://gis.stackexchange.com/questions/ask?tags=open-data-cube> en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment `ici <https://gis.stackexchange.com/questions/tagged/open-data-
Si vous souhaitez signaler un problème avec ce notebook, vous pouvez en déposer un sur Github.
Version de Datacube compatible
[21]:
print(datacube.__version__)
1.8.20
Dernier test :
[22]:
from datetime import datetime
datetime.today().strftime("%Y-%m-%d")
[22]:
'2025-01-16'