Apprentissage automatique avec Open Data Cube
Produits utilisés : gm_s2_annual
Exigences particulières : un fichier de formes de données étiquetées est nécessaire pour utiliser ce bloc-notes. Un exemple de jeu de données est fourni.
Prérequis : une compréhension de base des techniques d’apprentissage supervisé est requise.
Introduction à l’apprentissage statistique est une ressource utile pour commencer - elle peut être téléchargée gratuitement ici.
La documentation Scikit-learn fournit des informations sur les modèles disponibles et leurs paramètres.
Cet article <https://www.tandfonline.com/doi/full/10.1080/01431161.2018.1433343>__ fournit une bonne revue de l’apprentissage automatique dans le contexte de la télédétection.
Remarque ** : pour une exploration plus détaillée de l’apprentissage automatique sur l’ODC, consultez la série de blocs-notes : **Apprentissage automatique évolutif dans l’ODC dans le dossier « Real_world_examples/Scalable_machine_learning/ ».
Mots clés : données utilisées ; géomédiane sentinel-2, index:données utilisées ; MADs, urbain, couverture terrestre, méthodes de données ; apprentissage automatique, apprentissage automatique ; classification supervisée
Description
Ce bloc-notes présente un flux de travail potentiel utilisant des fonctions du script deafrica_tools.classification <https://docs.digitalearthafrica.org/en/latest/sandbox/notebooks/Tools/gen/deafrica_tools.classification.html>`__ pour implémenter un classificateur de couverture terrestre ``d'apprentissage supervisé dans le cadre ODC (Open Data Cube). Le bloc-notes utilise un fichier de formes par défaut de données de formation (fourni à des fins de démonstration uniquement) pour classer les zones urbaines à Kampala, en Ouganda
**Remarque ** : les utilisateurs qui disposent de leurs propres données d’entraînement peuvent importer directement leur propre fichier de formes en téléchargeant leur fichier de formes dans le Sandbox et en ajustant le paramètre « chemin ».
Le cahier montre comment :
Entraînez un modèle d’arbre de décision simple et ajustez les paramètres
Prédire les zones urbaines en utilisant le modèle formé sur de nouvelles données
Évaluer le résultat de la classification à l’aide de mesures quantitatives
Tracez les résultats et évaluez visuellement la classification
Exporter les résultats sous forme de géotiff
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Charger des paquets
Importez les packages Python utilisés pour l’analyse.
[1]:
%matplotlib inline
# Force GeoPandas to use Shapely instead of PyGEOS
# In a future release, GeoPandas will switch to using Shapely by default.
import os
os.environ['USE_PYGEOS'] = '0'
import datacube
import warnings
import pydotplus
import numpy as np
import geopandas as gpd
from io import StringIO
from joblib import dump
from pprint import pprint
import matplotlib.pyplot as plt
from IPython.display import Image
from odc.io.cgroups import get_cpu_quota
from sklearn import tree, model_selection
from sklearn.metrics import accuracy_score
from datacube.utils.cog import write_cog
from deafrica_tools.plotting import map_shapefile, rgb
from deafrica_tools.classification import predict_xr, collect_training_data
from deafrica_tools.bandindices import calculate_indices
[2]:
warnings.filterwarnings('ignore')
Se connecter au datacube
Connectez-vous au datacube pour que nous puissions accéder aux données de DE Africa.
[3]:
dc = datacube.Datacube(app='Machine_learning_with_ODC')
Paramètres d’analyse
« lat », « long » et « buffer » : l’emplacement central et le tampon de votre zone d’intérêt, cela définira la boîte à partir de laquelle nous extrayons les données satellite à classer lorsque nous faisons la prédiction.
path: le chemin d’accès au fichier de formes d’entrée. Un fichier de formes par défaut est fourni.field: Il s’agit du nom de la colonne dans votre table d’attributs de shapefile qui contient les étiquettes de classeproduct: Le nom du produit à extraire. Dans cet exemple, nous utilisons un composite géomédian Sentinel-2 de 2019,'ga_s2_gm'« time » : la plage de temps pour laquelle vous souhaitez extraire les données, généralement la même date à laquelle les étiquettes ont été créées.
zonal_stats: Il s’agit d’une option permettant de calculer la « moyenne », la « médiane », le « max » ou le « min » des valeurs de pixels dans chaque entité polygonale. La définir sur « Aucun » entraînera l’extraction de tous les pixels.« résolution » : la résolution spatiale, en mètres, pour rééchantillonner également les données satellite, par exemple si vous travaillez avec des données Landsat, cela doit être « (-10,10) »
Si vous exécutez le bloc-notes pour la première fois, conservez les paramètres par défaut ci-dessous. Cela permettra de démontrer le fonctionnement de l’analyse et de fournir des résultats significatifs.
Si vous décidez de modifier l’un des paramètres ci-dessous, ces modifications devront être reflétées dans la section « Prédiction ». Pour que la section de prédiction fonctionne, il faut charger les mêmes données que celles chargées dans les données d’entraînement. L’utilisateur doit mettre à jour la section de prédiction manuellement.
[4]:
lat, long = 0.3109, 32.5943 # Kampala, Uganda
buffer = 0.1
path = '../Supplementary_data/Machine_learning_with_ODC/kampala_urban_labels.shp'
field = 'class'
products = 'gm_s2_annual'
measurements = ['blue','green','red','nir','swir_1','swir_2', 'BCMAD', 'EMAD', 'SMAD']
time = ('2019')
zonal_stats = None #'median'
resolution = (-10, 10)
Détecter automatiquement le nombre de processeurs
[5]:
quota = get_cpu_quota()
ncpus = int(quota) if quota is not None else os.cpu_count() or 1
print('ncpus = '+str(ncpus))
ncpus = 4
Extraire les données d’entraînement à l’aide d’un shapefile
Les données d’apprentissage constituent la partie la plus importante de tout flux de travail d’apprentissage automatique. La qualité des données d’apprentissage a un impact plus important sur la classification que l’algorithme utilisé. Il est préférable d’utiliser des ensembles de données d’apprentissage volumineux et précis : l’augmentation de la taille de l’échantillon d’apprentissage se traduit par une précision de classification accrue (Huang, Davis et Townsend 2002).
Lors de la création de données d’apprentissage, veillez à capturer la « variabilité spectrale » de la classe et à utiliser des images de la période que vous souhaitez classer (plutôt que de vous fier aux composites de la carte de base). La meilleure façon de créer des données d’apprentissage est d’utiliser une plate-forme SIG.
Un autre problème courant avec les données d’entraînement est le « déséquilibre des classes ». Cela peut se produire lorsqu’une de vos classes est relativement rare et que, par conséquent, la classe rare comprendra une plus petite proportion de l’ensemble d’entraînement. Lorsque des données déséquilibrées sont utilisées, il est courant que la classification finale sous-estime les classes moins abondantes par rapport à leur proportion réelle.
**Remarque ** : les données de formation fournies par défaut sont uniquement à des fins de démonstration et ne doivent pas être utilisées pour une analyse du monde réel.
Tout d’abord, ouvrons nos données d’entrée et visualisons-les à l’aide de la fonction « map_shapefile ». Nous pouvons également vérifier le fichier de formes en le traçant et en l’inspectant. Remarque : les polygones sont très petits, vous devrez donc zoomer pour les voir.
[6]:
#open shapefile and ensure its in WGS84 coordinates
input_data = gpd.read_file(path).to_crs('epsg:4326')
#check the shapfile by plotting it
map_shapefile(input_data, attribute=field)
Définition des couches d’entités
Pour créer les couches d’entités souhaitées, nous transmettons des instructions à « collect_training_data » via le paramètre « feature_func ».
feature_func: une fonction permettant de générer des couches d’entités qui est appliquée aux données dans les limites de la géométrie d’entrée.feature_funcdoit accepter un objetdc_queryet renvoyer un seulxarray.Datasetouxarray.DataArraycontenant des coordonnées 2D (c’est-à-dire x, y - aucune dimension temporelle). p.ex.def feature_function(query): dc = datacube.Datacube(app='feature_layers') ds = dc.load(**query) ds = ds.mean('time') return ds
Ci-dessous, nous allons définir une fonction de couche d’entités. Nous allons charger toutes les couches du modèle annuel Sentinel-2 GeoMAD, puis calculer certains indices de bande.
[7]:
def feature_layers(query):
#connect to the datacube
dc = datacube.Datacube(app='feature_layers')
#load ls8 geomedian
ds = dc.load(product=products,
**query)
#calculate some band indices
ds = calculate_indices(ds,
index=['NDVI', 'BUI', 'MNDWI'],
drop=False,
satellite_mission='s2')
return ds
Pour former notre modèle, nous devons obtenir des données satellite qui correspondent aux emplacements des données d’entrée étiquetés.
La fonction « collect_training_data » prend notre fichier de formes, contenant les étiquettes de classe, et extrait les données d’entraînement du datacube sur l’emplacement spécifié par les géométries d’entrée. La fonction prétraitera également nos données d’entraînement en empilant les tableaux dans un format utile et en supprimant les valeurs « NaN » (not-a-number). Avant d’exécuter la fonction de données d’entraînement, nous devons d’abord configurer un dictionnaire avec les paramètres de requête satellite :
[8]:
#generate a datacube query object
query = {
'time': time,
'measurements': measurements,
'resolution': resolution,
'output_crs' : 'epsg:6933'
}
L’exécution de la cellule suivante peut prendre plusieurs minutes. Les étiquettes de classe seront contenues dans la première colonne du tableau de sortie. Si vous définissez « ncpus > 1 », cette fonction sera exécutée en parallèle sur le nombre de processus spécifié.
[9]:
#Collect the training data from the datacube
column_names, model_input = collect_training_data(
gdf=input_data,
dc_query=query,
ncpus=ncpus,
field=field,
zonal_stats=zonal_stats,
feature_func=feature_layers
)
Collecting training data in parallel mode
Percentage of possible fails after run 1 = 0.0 %
Removed 0 rows wth NaNs &/or Infs
Output shape: (5076, 13)
[10]:
print(column_names)
print('')
print(np.array_str(model_input, precision=2, suppress_small=True))
['class', 'blue', 'green', 'red', 'nir', 'swir_1', 'swir_2', 'BCMAD', 'EMAD', 'SMAD', 'NDVI', 'BUI', 'MNDWI']
[[ 1. 1047. 1326. ... 0.08 0. -0.24]
[ 1. 972. 1151. ... 0.01 0.16 -0.25]
[ 1. 818. 1036. ... 0.23 -0.14 -0.42]
...
[ 0. 371. 414. ... -0.1 -0.16 0.45]
[ 0. 374. 424. ... -0.09 -0.19 0.47]
[ 0. 379. 429. ... -0.08 -0.22 0.47]]
Afin de pouvoir évaluer la précision de notre classification, nous avons divisé nos données en données d’entraînement et de test. 80 % sont utilisés pour l’entraînement et 20 % sont réservés pour les tests. Lors de la division de nos données, nous stratifions les données d’entraînement en fonction des distributions d’appartenance aux classes. Cette méthode d’échantillonnage conduit à une distribution similaire de l’appartenance aux classes dans les données d’entraînement.
[11]:
# Split into training and testing data
model_train, model_test = model_selection.train_test_split(model_input,
stratify=model_input[:, 0],
train_size=0.8,
random_state=0)
print("Train shape:", model_train.shape)
print("Test shape:", model_test.shape)
Train shape: (4060, 13)
Test shape: (1016, 13)
Préparation du modèle
Cette section crée automatiquement une liste de noms de variables et de leurs indices respectifs pour chacune des variables de données de formation.
Remarque : pour utiliser un sous-ensemble personnalisé des bandes satellites chargées ci-dessus pour entraîner nos données, vous pouvez remplacer « column_names[1:] » par une liste de noms de bandes sélectionnés (par exemple, « [“red”, “green”, “blue”] »)
[12]:
# Select the variables we want to use to train our model
model_variables = column_names[1:]
# Extract relevant indices from the processed shapefile
model_col_indices = [column_names.index(var_name) for var_name in model_variables]
Un modèle d’arbre de décision est choisi car il s’agit de l’un des modèles d’apprentissage automatique supervisé les plus simples que nous pouvons mettre en œuvre.
Ses points forts sont son explicabilité et son faible coût de calcul.
Le réglage des paramètres peut être effectué dans l’initialisation du modèle ci-dessous en ajoutant ou en modifiant des variables dans les « classifier_params » ci-dessous - les détails sur la façon dont les différents paramètres affecteront le modèle sont « ici <https://scikit-learn.org/stable/modules/tree.html#tips-on-practical-use> ».
[13]:
classifier_params = {'criterion': 'gini',
'max_depth' : 10,
'splitter' : 'random',
'min_samples_split' : 100}
model = tree.DecisionTreeClassifier(**classifier_params, random_state=1)
Modèle de train
Le modèle est ajusté/formé à l’aide des données d’entraînement préparées. Le processus d’ajustement utilise l’approche de l’arbre de décision pour créer une représentation généralisée de la réalité basée sur les données d’entraînement. Ce modèle ajusté/formé peut ensuite être utilisé pour prédire à quelle classe appartiennent les nouvelles données.
[14]:
# Train model
model.fit(model_train[:, model_col_indices], model_train[:, 0])
[14]:
DecisionTreeClassifier(max_depth=10, min_samples_split=100, random_state=1,
splitter='random')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Sauvegarder éventuellement le modèle
L’exécution de cette cellule exportera le classificateur sous forme de fichier binaire .joblib. Cela permettra d’importer le modèle dans d’autres scripts si nous souhaitons utiliser le même modèle pour classer une région différente.
Pour importer un modèle enregistré, exécutez l’extrait de code suivant :
from joblib import load
ml_model = 'ml_model.joblib'
model = load(ml_model)
[15]:
dump(model, 'ml_model.joblib')
[15]:
['ml_model.joblib']
Évaluation du classificateur
Les cellules suivantes vous aideront à examiner le classificateur et à améliorer les résultats. Nous pouvons le faire en :
Déterminer notre précision globale,
Déterminer quelles caractéristiques (bandes dans les données d’entrée) sont les plus utiles pour la classification, et lesquelles ne le sont pas,
Tracer l’arbre de décision pour nous aider à comprendre quels seuils sont utilisés pour séparer les classes.
Précision globale
Nous pouvons utiliser l’échantillon de 20 % de données de test que nous avons partitionné précédemment pour tester la précision du modèle formé sur ces nouvelles données « invisibles ».
Une valeur de précision de 1,0 indique que le modèle a été capable de prédire correctement 100 % des classes dans les données de test.
[16]:
predictions = model.predict(model_test[:, model_col_indices])
str(round(accuracy_score(predictions, model_test[:, 0]), 2) *100) + ' %'
[16]:
'100.0 %'
Déterminer l’importance des fonctionnalités
Extraire les estimations du classificateur de l’importance relative de chaque bande/variable pour l’entraînement du classificateur. Utile pour sélectionner potentiellement un sous-ensemble de bandes/variables d’entrée pour l’entraînement/la classification du modèle (c’est-à-dire pour optimiser l’espace des caractéristiques). Les résultats seront présentés par ordre décroissant, les caractéristiques les plus importantes étant répertoriées en premier. L’importance est indiquée sous forme de fraction relative entre 0 et 1.
[17]:
# This shows the feature importance of the input features for predicting the class labels provided
order = np.argsort(model.feature_importances_)
plt.figure(figsize=(16,5))
plt.bar(x=np.array(model_variables)[order],
height=model.feature_importances_[order])
plt.gca().set_ylabel('Importance', labelpad=10)
plt.gca().set_xlabel('Variable', labelpad=10);
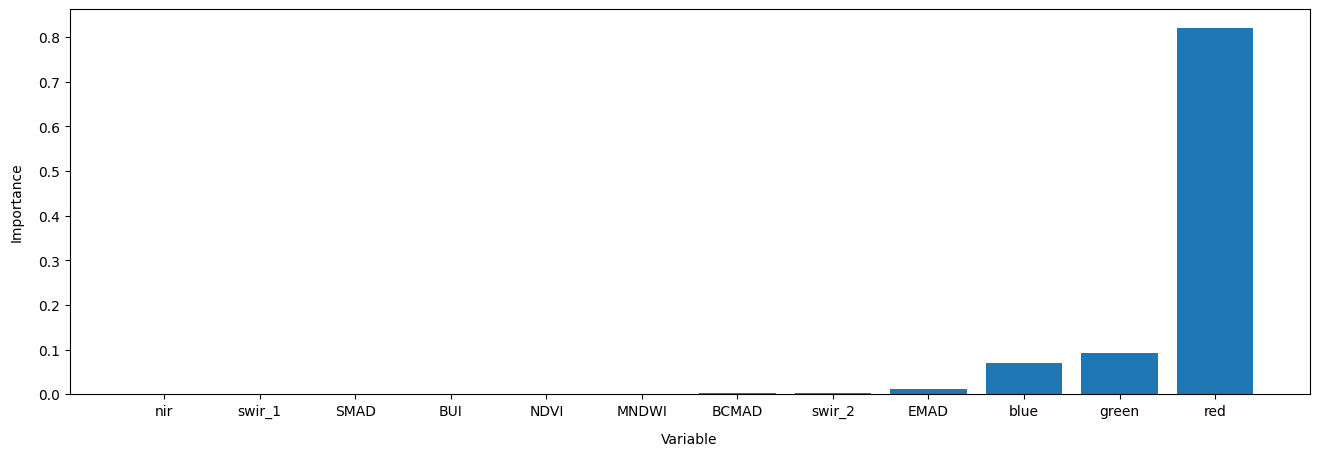
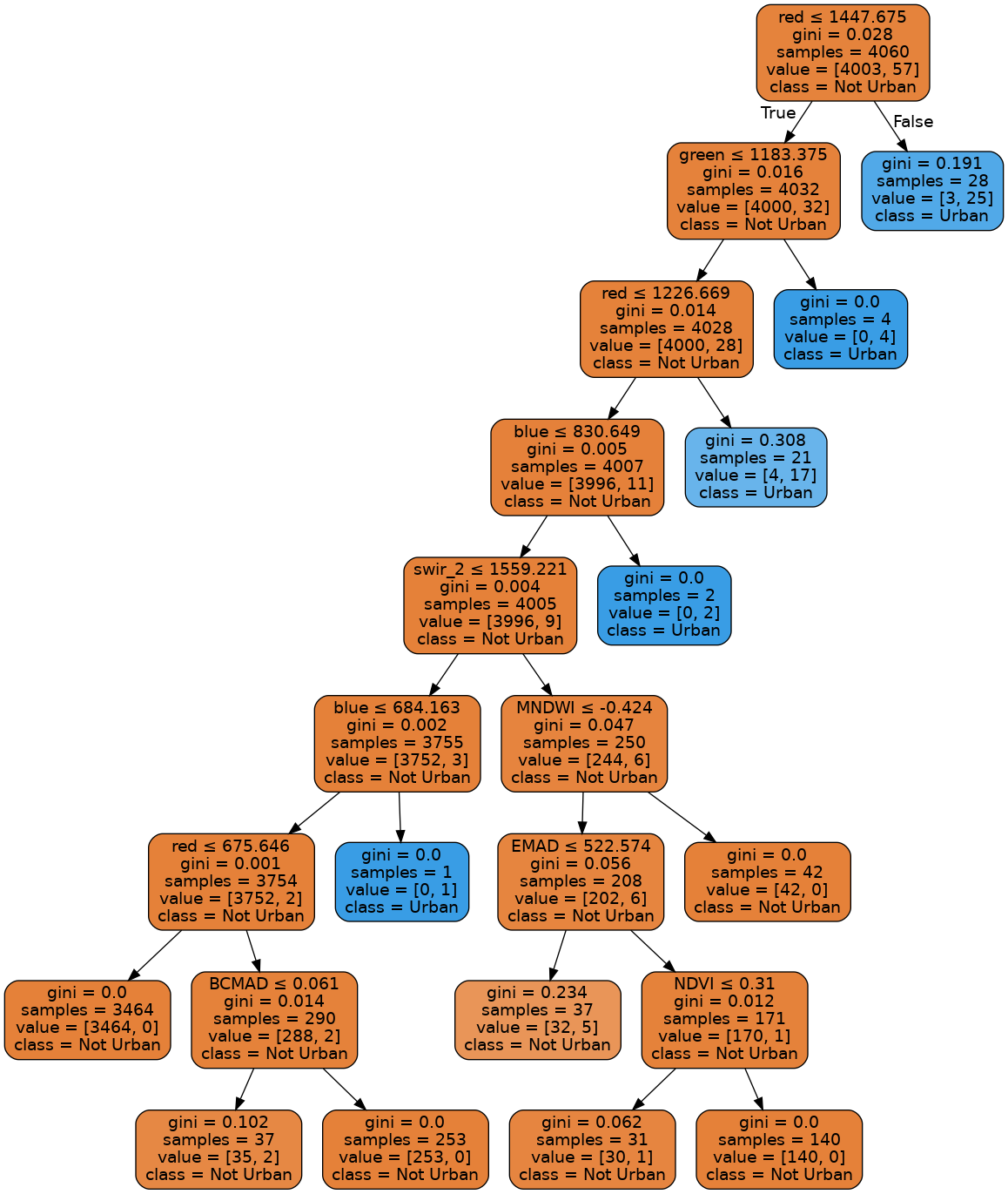
Tracer l’arbre de décision
Cette représentation de l’arbre de décision visualise le modèle formé. Ici, nous pouvons voir que le modèle décide quelle classe de couverture terrestre attribuer en fonction de la valeur des variables importantes dans le graphique ci-dessus.
La valeur gini (ou entropie) affichée dans l’arbre représente la diminution de l’impureté des nœuds. Cela peut également être interprété comme le degré d’hétérogénéité des étiquettes (de petites valeurs indiquant de meilleurs résultats). Cette mesure est utilisée par l’arbre de décision pour déterminer comment diviser les données en groupes plus petits.
Cette étape peut prendre beaucoup de temps si vous utilisez « feature_stats = None »
Si le graphique est petit, double-cliquez pour l’agrandir. Double-cliquez à nouveau pour revenir à la taille initiale.
[18]:
# Prepare a dictionary of class names
class_names = {1: 'Urban',
0: 'Not Urban'}
# Get list of unique classes in model
class_codes = np.unique(model_train[:, 0])
class_names_in_model = [class_names[k] for k in class_codes]
# Plot decision tree
dot_data = StringIO()
tree.export_graphviz(model,
out_file=dot_data,
feature_names=model_variables,
class_names=class_names_in_model,
filled=True,
rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph = Image(graph.create_png())
graph
[18]:
Prédiction
Maintenant que nous avons un modèle formé, nous pouvons charger de nouvelles données et utiliser la fonction « predict_xr » pour prédire les classes de couverture terrestre.
Le modèle formé peut techniquement être utilisé pour classer n’importe quel ensemble de données ou produit avec les mêmes bandes que les données utilisées à l’origine pour l’entraînement des données. Cependant, il est généralement fortement conseillé de classer les données du même produit sur lequel les données ont été initialement formées.
Si vous avez modifié l’un des paramètres de la section « Paramètres d’analyse » par rapport à ses valeurs par défaut, ces modifications devront être reflétées dans le code ci-dessous. Pour que la section de prédiction fonctionne, elle nécessite le chargement des mêmes données que celles chargées dans les données d’entraînement. L’utilisateur doit mettre à jour cette section manuellement.
[19]:
# Load the data based on query around the user supplied
# lat/long and buffer
q = {'x': (long-buffer, long+buffer),
'y': (lat+buffer, lat-buffer)}
query.update(q)
#calculate features
data = feature_layers(query)
data = data.where(data!=0, np.nan)
print(data)
<xarray.Dataset> Size: 414MB
Dimensions: (time: 1, y: 2552, x: 1931)
Coordinates:
* time (time) datetime64[ns] 8B 2019-07-02T11:59:59.999999
* y (y) float64 20kB 5.242e+04 5.24e+04 ... 2.692e+04 2.69e+04
* x (x) float64 15kB 3.135e+06 3.135e+06 ... 3.155e+06 3.155e+06
spatial_ref int32 4B 6933
Data variables:
blue (time, y, x) float64 39MB 744.0 697.0 591.0 ... 391.0 375.0
green (time, y, x) float64 39MB 1.081e+03 1.076e+03 ... 642.0 621.0
red (time, y, x) float64 39MB 1.626e+03 1.522e+03 ... 499.0 468.0
nir (time, y, x) float64 39MB 2.465e+03 2.709e+03 ... 3.252e+03
swir_1 (time, y, x) float64 39MB 2.944e+03 2.962e+03 ... 2.011e+03
swir_2 (time, y, x) float64 39MB 2.369e+03 2.252e+03 ... 1.109e+03
BCMAD (time, y, x) float32 20MB 0.05101 0.04906 ... 0.04856 0.05198
EMAD (time, y, x) float32 20MB 762.0 720.6 668.8 ... 749.7 782.8
SMAD (time, y, x) float32 20MB 0.00134 0.001616 ... 0.00118 0.001544
NDVI (time, y, x) float64 39MB 0.2051 0.2805 ... 0.7392 0.7484
BUI (time, y, x) float64 39MB -0.1165 -0.2359 ... -0.9923 -0.9842
MNDWI (time, y, x) float64 39MB -0.4629 -0.4671 ... -0.5109 -0.5281
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
[20]:
# Predict landcover using the trained model
predicted = predict_xr(model, data, clean=True)
predicting...
Traçage
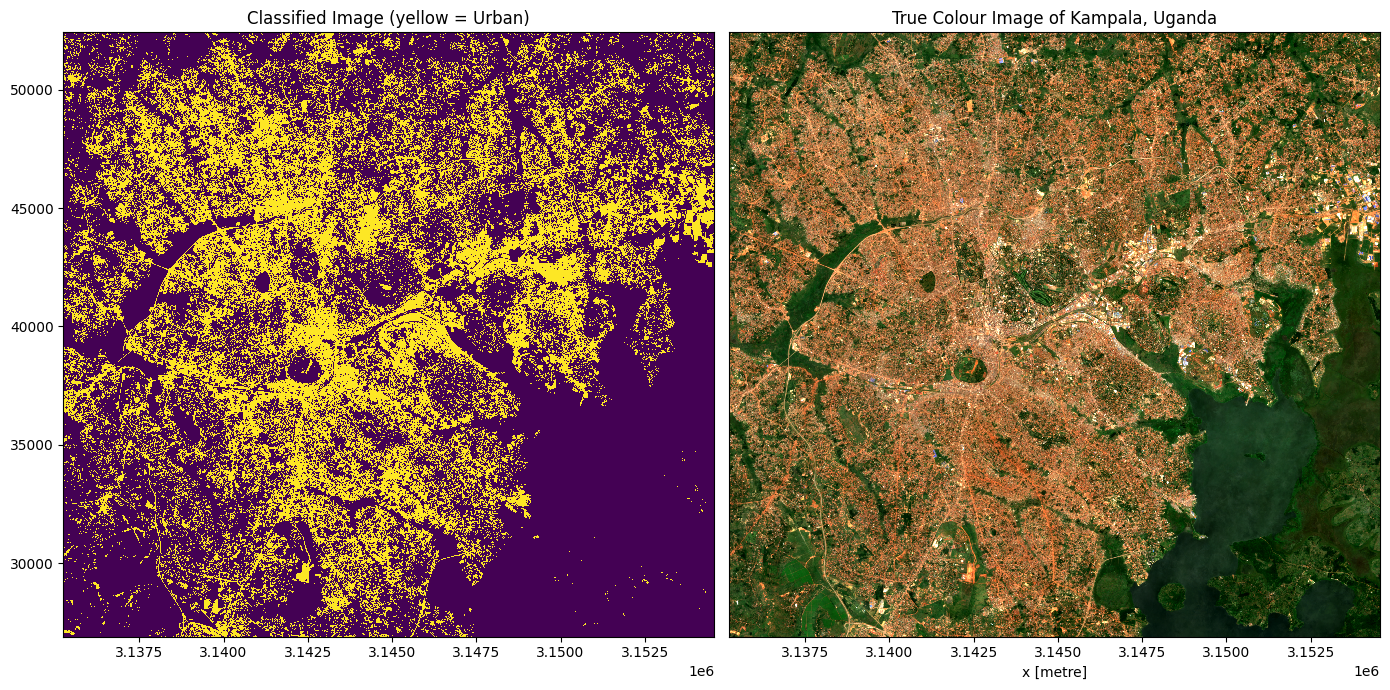
Pour évaluer qualitativement la qualité de la classification, nous pouvons tracer les données classées/prédites à côté de notre imagerie satellite d’entrée.
Remarque : Il est peu probable que le résultat ci-dessous soit optimal la première fois que la classification est exécutée. Le processus de formation du modèle est un processus d’expérimentation et de vérification des hypothèses qui se déroule dans un cycle itératif. Utilisez les étapes « Évaluer le classificateur » ci-dessous pour vous aider à améliorer le modèle
[21]:
# Set up plot
fig, axes = plt.subplots(1, 2, figsize=(14, 7))
# Plot classified image
predicted.Predictions.plot(ax=axes[0],
cmap='viridis',
add_labels=False,
add_colorbar=False)
# Plot true colour image
rgb(data, ax=axes[1], percentile_stretch=(0.01, 0.99))
# Remove axis on right plot
axes[1].get_yaxis().set_visible(False)
# Add plot titles
axes[0].set_title('Classified Image (yellow = Urban)')
axes[1].set_title('True Colour Image of Kampala, Uganda')
plt.tight_layout();
Exportation de la classification
Nous pouvons maintenant exporter la couverture terrestre prévue vers un fichier GeoTIFF « .tif ». Ce fichier peut être chargé dans un logiciel SIG (par exemple QGIS, ArcMap) pour être inspecté de plus près.
[22]:
write_cog(predicted.Predictions,
fname="predicted.tif",
overwrite=True)
[22]:
PosixPath('predicted.tif')
Informations Complémentaires
Licence Le code de ce notebook est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>`__.
Les données de Digital Earth Africa sont sous licence Creative Commons Attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack DE Africa <https://digitalearthafrica.slack.com/> ou sur le GIS Stack Exchange <https://gis.stackexchange.com/questions/ask?tags=open-data-cube> en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment `ici <https://gis.stackexchange.com/questions/tagged/open-data-
Si vous souhaitez signaler un problème avec ce notebook, vous pouvez en déposer un sur Github.
Version de Datacube compatible
[23]:
print(datacube.__version__)
1.9.13
Dernier test :
[24]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[24]:
'2026-04-08'