Détection de débris marins flottants
Produits utilisés : s2_l2a wofs_ls_summary_alltime
Aperçu
La pollution plastique marine est un problème mondial qui menace les écosystèmes marins et la santé humaine. La détection et la quantification des déchets plastiques dans le milieu marin sont essentielles pour résoudre ce problème. Les techniques de télédétection, notamment celles utilisant l’imagerie satellite, sont devenues un outil prometteur pour identifier et surveiller les débris plastiques dans l’océan. Dans ce carnet, nous explorerons l’utilisation de l’indice de débris flottants (FDI) et de l’indice de végétation par différence normalisée (NDVI) pour détecter les plastiques flottants dans l’imagerie satellite Sentinel-2. Français Ces indices ont démontré des performances supérieures dans la détection de plastiques marins flottants dans divers endroits tels que la Grèce (Topouzelis et al., 2019, 2020), Chypre (Themistocleous et al., 2020) et Durban (Biermann et al., 2020).
Détection de débris marins :
Les débris marins constituent une menace importante pour la vie marine et la santé humaine. Détecter leur présence dans les plans d’eau est devenue une priorité mondiale. Pour y remédier, nous utiliserons les FDI et NDVI appliqués aux images satellite Sentinel-2.
Indice de débris flottants (FDI) : L’indice de débris flottants (FDI) est un indice spectral spécialement conçu pour détecter et quantifier les débris flottants à la surface de l’eau. En calculant l’indice FDI à l’aide de l’imagerie satellite Sentinel-2, nous pouvons identifier efficacement les zones où des débris marins sont présents dans la zone d’étude. L’indice FDI tire parti des caractéristiques spectrales uniques présentées par les débris flottants, ce qui nous permet de les distinguer des autres éléments de l’image. Une technique de seuillage sera appliquée aux valeurs de l’indice FDI, permettant de séparer les débris marins de l’eau environnante et d’autres matériaux.
Indice de végétation par différence normalisée (NDVI) : bien qu’il soit principalement conçu pour la surveillance de la végétation, l’indice de végétation par différence normalisée (NDVI) peut également être adapté pour détecter les débris marins flottants. Les débris marins présentent souvent des propriétés spectrales qui les distinguent des éléments naturels. En calculant le NDVI à l’aide de l’imagerie Sentinel-2, nous pouvons exploiter ces différences spectrales pour identifier les emplacements potentiels des débris marins. Le NDVI quantifie la différence entre les bandes spectrales proche infrarouge et rouge, fournissant une indication de la présence de débris marins en fonction de leurs réponses spectrales uniques. Cela nous permet de distinguer les débris marins des autres matériaux de l’image, facilitant ainsi la détection et la caractérisation des débris plastiques flottants.
Description
Workflow du carnet de notes : Les étapes suivantes seront abordées dans ce carnet pour détecter les débris marins flottants :
Prétraitement des données :
Obtenir des images satellite Sentinel-2 pour la zone d’étude.
Effectuer les étapes de prétraitement nécessaires telles que la correction atmosphérique et l’étalonnage radiométrique.
Calcul des indices spectraux :
Calculez le FDI et le NDVI en fonction des bandes spectrales de l’imagerie Sentinel-2.
Techniques de seuillage :
Appliquer des techniques de seuillage au FDI et au NDVI pour séparer les débris marins des autres caractéristiques de l’imagerie.
Déterminer les valeurs seuils appropriées sur la base d’études ou d’expérimentations antérieures.
Détection et quantification des débris marins :
Identifier et extraire les emplacements potentiels de débris marins en fonction des indices seuillés.
Générer des statistiques et des mesures pour quantifier l’étendue et la répartition des débris marins dans la zone d’étude.
Analyse des résultats :
Analyser les schémas de distribution des débris marins détectés et leurs sources potentielles.
Comparez les résultats avec les données de référence disponibles pour valider les conclusions.
Pour évaluer la précision de notre méthode de détection des débris marins, ce carnet utilise le « Marine Debris Dataset for Object Detection in Planetscope Imagery Dataset <https://mlhub.earth/data/nasa_marine_debris> ». Ce jeu de données comprend des images de 256 x 256 pixels extraites de l’imagerie optique PlanetScope, annotées avec des cadres de délimitation et des coordonnées géographiques. Le jeu de données couvre divers types de débris marins, notamment les plastiques, les algues, les sargasses, le bois et d’autres artefacts. Ce jeu de données servira de vérité fondamentale, nous permettant de mesurer quantitativement la précision de notre modèle de détection.
Importer les bibliothèques nécessaires
[1]:
# Load the necessary python packages.
%matplotlib inline
import os
import datacube
import seaborn as sns
import numpy as np
import xarray as xr
import geopandas as gpd
import matplotlib.pyplot as plt
from odc.geo.geom import Geometry
from shapely.geometry import LineString
import matplotlib.patches as mpatches
import matplotlib.lines as mlines
from sklearn import preprocessing
from deafrica_tools.spatial import xr_vectorize
from deafrica_tools.plotting import rgb
from deafrica_tools.plotting import display_map
from deafrica_tools.spatial import xr_rasterize
from deafrica_tools.areaofinterest import define_area
from deafrica_tools.bandindices import calculate_indices
Se connecter au datacube
[2]:
dc = datacube.Datacube(app='detect_marine_debris')
Paramètres d’analyse
Sélectionnez l’emplacement
Pour définir la zone d’intérêt, deux méthodes sont disponibles :
En spécifiant la latitude, la longitude et la zone tampon. Cette méthode nécessite que vous saisissiez la latitude centrale, la longitude centrale et la valeur de la zone tampon en degrés carrés autour du point central que vous souhaitez analyser. Par exemple, « lat = 10,338 », « lon = -1,055 » et « buffer = 0,1 » sélectionneront une zone avec un rayon de 0,1 degré carré autour du point avec les coordonnées (10,338, -1,055).
Vous pouvez également fournir des valeurs de tampon distinctes pour la latitude et la longitude d’une zone rectangulaire. Par exemple, « lat = 10.338 », « lon = -1.055 » et « lat_buffer = 0.1 » et « lon_buffer = 0.08 » sélectionneront une zone rectangulaire s’étendant sur 0,1 degré au nord et au sud et 0,08 degré à l’est et à l’ouest à partir du point « (10.338, -1.055) ».
Pour des temps de chargement raisonnables, définissez la mémoire tampon sur « 0,1 » ou moins.
By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
Pour utiliser l’une de ces méthodes, vous pouvez décommenter la ligne de code concernée et commenter l’autre. Pour commenter une ligne, ajoutez le symbole "#" avant le code que vous souhaitez commenter. Par défaut, la première option qui définit l’emplacement à l’aide de la latitude, de la longitude et du tampon est utilisée.
[3]:
# Method 1: Specify the latitude, longitude, and buffer
# aoi = define_area(lat=10.338, lon=-1.055, buffer=0.1)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
aoi = define_area(
vector_path=
f"../Supplementary_data/Floating_marine_debris/nasa_marine_debris_labels_ghana_bounding_box.geojson"
)
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
[4]:
display_map(x=lon_range, y=lat_range)
[4]:
Charger les données Sentinel-2 pour la zone d’intérêt et la plage horaire
Remarque : dans ce bloc-notes, l’exemple présenté se concentre sur un seul horodatage, en particulier « 2018-10-31 », pour lequel nous avons accès à des données de vérité fondamentale sous la forme du « Marine Debris Dataset for Object Detection in Planetscope Imagery Dataset <https://mlhub.earth/data/nasa_marine_debris> » dans la zone d’intérêt désignée. Cependant, la flexibilité du flux de travail permet une adaptation transparente pour analyser les données sur une plage d’horodatages. Cette capacité vous permet d’examiner la présence et la distribution de débris à différents moments dans la plage de dates spécifiée. Que vous soyez intéressé par une période spécifique ou que vous souhaitiez effectuer des analyses comparatives sur plusieurs horodatages, le flux de travail peut être personnalisé en fonction de vos besoins de recherche.
[5]:
product = 's2_l2a'
query = {
'geopolygon': geopolygon,
'time': ('2018-10-31'),
'output_crs': 'EPSG:6933',
'resolution': (-10, 10),
'measurements': ['blue', 'green', 'red', 'red_edge_2', 'nir', 'swir_1'],
'group_by': "solar_day",
}
ds = dc.load(product=product, **query)
ds
[5]:
<xarray.Dataset> Size: 30MB
Dimensions: (time: 1, y: 1633, x: 1538)
Coordinates:
* time (time) datetime64[ns] 8B 2018-10-31T10:19:11
* y (y) float64 13kB 7.068e+05 7.068e+05 ... 6.905e+05 6.905e+05
* x (x) float64 12kB -3.416e+04 -3.416e+04 ... -1.88e+04 -1.88e+04
spatial_ref int32 4B 6933
Data variables:
blue (time, y, x) uint16 5MB 852 1020 1320 1630 ... 440 424 411 402
green (time, y, x) uint16 5MB 1180 1510 1864 2096 ... 319 294 301 312
red (time, y, x) uint16 5MB 1430 2192 2200 2498 ... 214 211 220 218
red_edge_2 (time, y, x) uint16 5MB 2978 2653 2653 2750 ... 203 209 209 199
nir (time, y, x) uint16 5MB 3194 3164 2832 2812 ... 198 189 180 197
swir_1 (time, y, x) uint16 5MB 3112 3588 3588 3547 ... 168 172 172 160
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refNormaliser l’intensité des bandes
La normalisation de l’intensité des bandes utilisées dans l’indice de débris flottants (FDI) est importante pour garantir que l’indice ne soit pas biaisé par des différences de valeurs de luminosité ou de réflectance sur l’image. La normalisation permet de standardiser la plage de valeurs sur les bandes, de sorte que chaque bande contribue de manière égale à l’indice, quelles que soient ses valeurs d’intensité d’origine.
Si les valeurs d’intensité des bandes ne sont pas normalisées, cela peut entraîner des inexactitudes dans les résultats de l’IDF, comme des faux positifs ou des faux négatifs. Par exemple, si une bande présente des valeurs d’intensité nettement plus élevées que les autres, elle peut dominer le calcul de l’IDF et conduire à une surestimation de la quantité de débris flottants présents dans l’image.
En normalisant les valeurs d’intensité, l’indice FDI est calculé en fonction des différences relatives des valeurs de réflectance entre les deux bandes, plutôt que des valeurs d’intensité absolues. Cela permet de garantir que l’indice FDI est un indicateur plus précis de la présence de débris flottants et de réduire l’impact d’autres facteurs susceptibles d’affecter les valeurs de luminosité ou de réflectance de l’image, comme la couverture nuageuse ou les conditions d’éclairage variables.
[6]:
# Function to normalize the band values using scikit-learn.
def normalize_bands(ds):
bands = list(ds.data_vars)
for band in bands:
# Get the band's data as a 2D array (time x pixel).
band_data = ds[band].values.reshape(-1, 1)
# Initialize the MinMaxScaler.
scaler = preprocessing.MinMaxScaler()
# Fit the scaler on the data and transform it to normalize the values.
normalized_data = scaler.fit_transform(band_data)
# Update the dataset with the normalized values.
ds[band] = xr.DataArray(normalized_data.reshape(ds[band].shape),
dims=ds[band].dims)
return ds
# Normalize the bands.
normalized_ds = normalize_bands(ds)
rgb(normalized_ds, col="time")
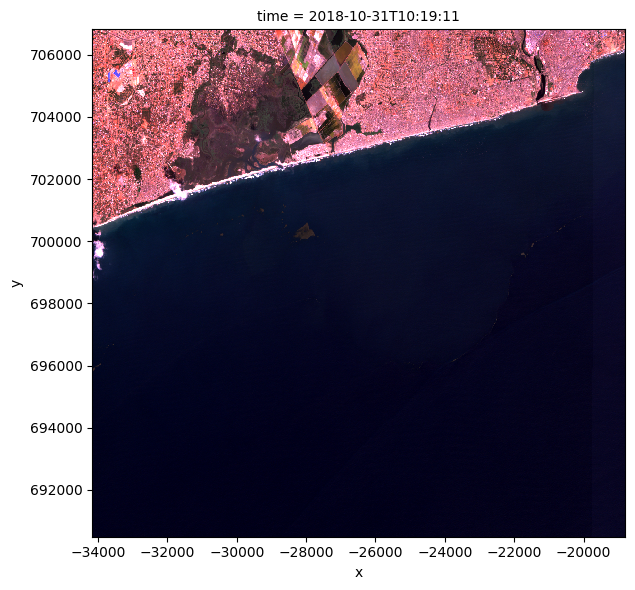
Masquer les zones non marines
Littoraux approuvés par la Banque mondiale téléchargés depuis https://datacatalog.worldbank.org/search/dataset/0038272
[7]:
world_coastlines = gpd.read_file(
"../Supplementary_data/Floating_marine_debris/WB_Coastlines_10m.shp")
#Clip the coastline to the area of interest
coastline = gpd.clip(world_coastlines, geopolygon_gdf)
coastline.explore(column='featurecla', cmap='inferno', categorical=True)
[7]:
[8]:
# Check the CRS and reproject if necessary
if coastline.crs != 'epsg:6933':
coastline = coastline.to_crs('epsg:6933')
# Assuming you have a GeoDataFrame called 'coastline' with a LineString geometry column
side = "left" # Choose the side of the line for buffering ("right" or "left")
buffer_distance = 3000 # Specify the buffer distance in the appropriate units
# Convert LineString to a list of LineString geometries
line_geometries = list(coastline.geometry)
# Create a buffered line on the desired side
buffered_geometries = []
for line in line_geometries:
if side == "right":
offset_line = line.parallel_offset(buffer_distance, "right")
elif side == "left":
offset_line = line.parallel_offset(buffer_distance, "left")
buffer = offset_line.buffer(buffer_distance)
buffer_on_side = buffer.difference(line)
buffered_geometries.append(buffer_on_side)
# Create a new GeoDataFrame with the buffered geometries
coastline_buffer = gpd.GeoDataFrame(geometry=buffered_geometries,
crs=coastline.crs)
# Plot the buffer on the image to see which parts of the image will be masked.
# This can help with determining if the buffer size is sufficient and removes inland pixels
# Create a figure and axis with a larger figsize
fig, ax = plt.subplots(figsize=(12, 8))
# Plot the rgb
rgb(normalized_ds.isel(time=0), ax=ax)
# Plot the coastline buffer over the dataset
coastline_buffer.plot(ax=ax, color='red', alpha=0.5)
# Plot the coastline over the coastline buffer
coastline.plot(ax=ax, color='blue', alpha=0.5)
# Set the aspect ratio of the plot
ax.set_aspect('equal')
# Set the plot limits to match the extent of the normalized_ds data
ax.set_xlim(normalized_ds.x.min(), normalized_ds.x.max())
ax.set_ylim(normalized_ds.y.min(), normalized_ds.y.max())
# Show the plot
plt.show()
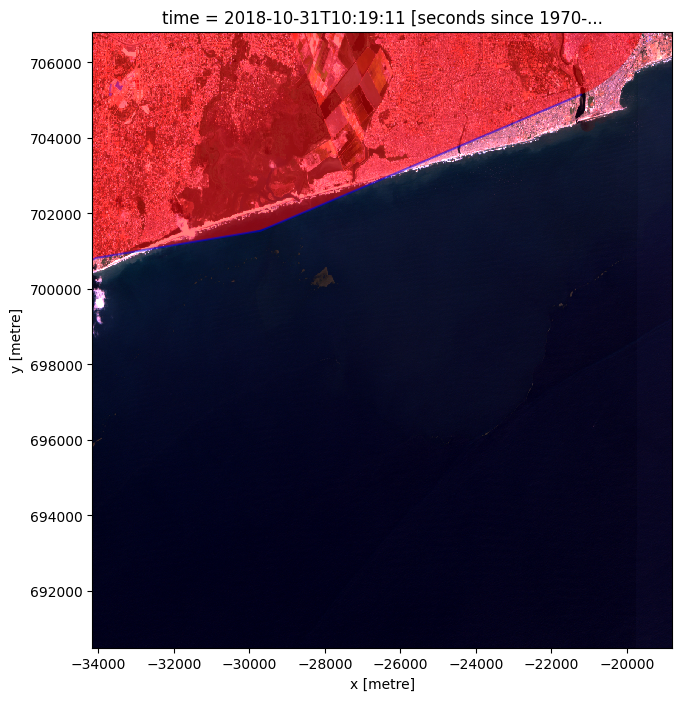
[9]:
coastline_raster = xr_rasterize(gdf=coastline_buffer,
da=ds,
crs=ds.crs)
ds_masked_coastline = normalized_ds.where(coastline_raster == 0)
rgb(ds_masked_coastline.isel(time=0))
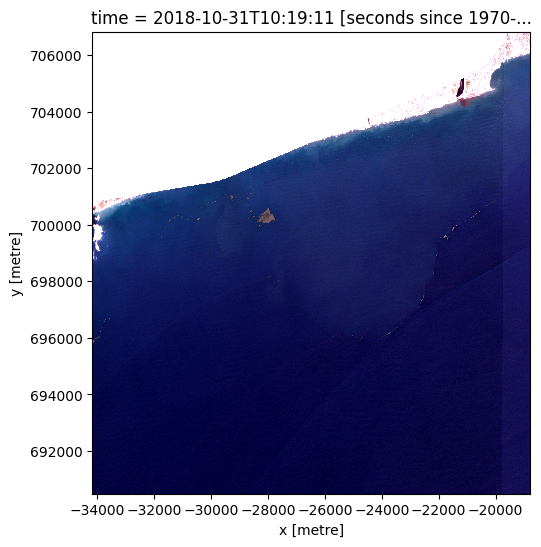
Suppression de zones de terres supplémentaires à l’aide du résumé « de tous les temps » du WOfS
L’ensemble de données sur les côtes de la Banque mondiale est utilisé pour masquer les zones terrestres. Cependant, en raison de la nature mondiale de l’ensemble de données, des inexactitudes peuvent survenir lorsque les côtes s’étendent dans l’océan ou plus loin à l’intérieur des terres. Pour résoudre ce problème, la couche récapitulative « tout le temps » de l’observation de l’eau depuis l’espace (WOfS) est utilisée pour supprimer les zones terrestres incluses par erreur dans la région d’intérêt. Malheureusement, il n’existe aucune disposition permettant de réinclure les zones aquatiques ou marines exclues accidentellement dans le carnet actuel.
[10]:
wofs_alltime = dc.load(product='wofs_ls_summary_alltime',
geopolygon=geopolygon,
resolution=(-30, 30))
wofs_alltime.frequency.plot(size=6,
cmap=sns.color_palette("mako_r", as_cmap=True))
plt.title('WOfS All-Time Summary');
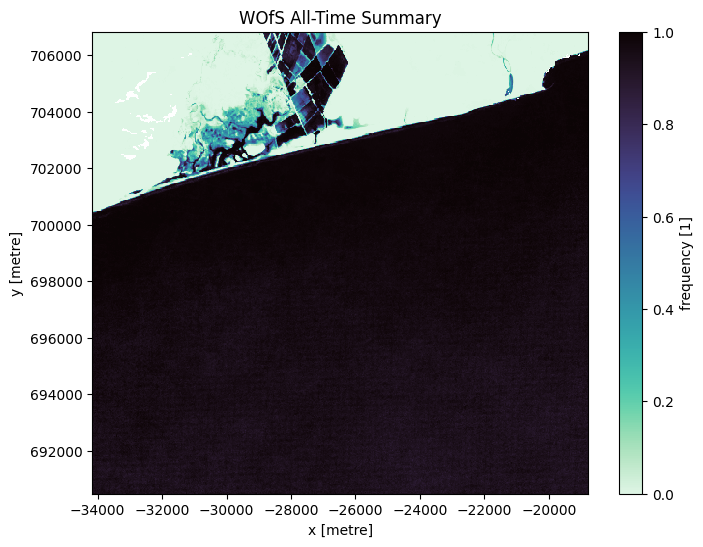
[11]:
wofs_alltime_wet = wofs_alltime.where(wofs_alltime.frequency >= 0.5)
wofs_alltime_wet = wofs_alltime_wet.isel(time=0)
ds_masked_coastline = ds_masked_coastline.where(
wofs_alltime_wet.frequency >= 0.5)
rgb(ds_masked_coastline.isel(time=0))
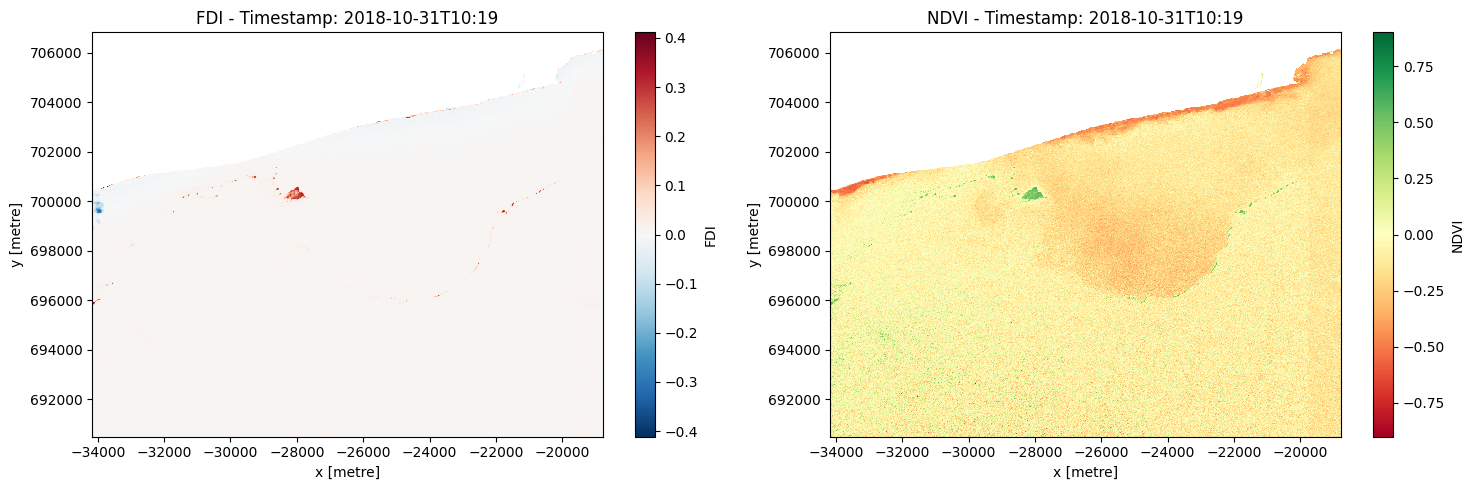
Calculer et tracer l’indice de débris flottants (FDI) et l’indice de végétation par différence normalisée (NDVI)
Indice de débris flottants (FDI) : L’indice de débris flottants (FDI) est un indice spectral spécialement conçu pour détecter et quantifier les débris flottants à la surface de l’eau. En calculant l’indice FDI à l’aide de l’imagerie satellite Sentinel-2, nous pouvons identifier efficacement les zones où des débris marins sont présents dans la zone d’étude. L’indice FDI tire parti des caractéristiques spectrales uniques présentées par les débris flottants, ce qui nous permet de les distinguer des autres éléments de l’image. Une technique de seuillage sera appliquée aux valeurs de l’indice FDI, permettant de séparer les débris marins de l’eau environnante et d’autres matériaux.
Indice de débris flottants (FDI)
\begin{equation} \text{FDI} = R_{rs},NIR - (R_{rs},RE2 + (R_{rs}, SWIR1 - R_{rs}, RE2) * \frac{(\lambda_{NIR} - \lambda_{RED})}{(\lambda_{SWIR1} - \lambda_{RED})} * 10) \end{equation}
où \(R_{rs,NIR}\), \(R_{rs, RE2}\), \(R_{rs, SWIR1}\) sont les valeurs de réflectance dans les bandes proche infrarouge, bord rouge 2 et infrarouge à ondes courtes, respectivement, \(λ_i\) est la longueur d’onde avec le nom de la bande en indice.
Notez que les valeurs de longueur d’onde sont les longueurs d’onde centrales de https://www.usgs.gov/centers/eros/science/usgs-eros-archive-sentinel-2
Indice de végétation par différence normalisée (NDVI) : bien qu’il soit principalement conçu pour la surveillance de la végétation, l’indice de végétation par différence normalisée (NDVI) peut également être adapté pour détecter les débris marins flottants. Les débris marins présentent souvent des propriétés spectrales qui les distinguent des éléments naturels. En calculant le NDVI à l’aide de l’imagerie Sentinel-2, nous pouvons exploiter ces différences spectrales pour identifier les emplacements potentiels des débris marins. Le NDVI quantifie la différence entre les bandes spectrales proche infrarouge et rouge, fournissant une indication de la présence de débris marins en fonction de leurs réponses spectrales uniques. Cela nous permet de distinguer les débris marins des autres matériaux de l’image, facilitant ainsi la détection et la caractérisation des débris plastiques flottants.
Indice de végétation par différence normalisée (NDVI)
\begin{equation} \text{NDVI} = \frac{R_{rs},NIR - R_{rs},RED}{R_{rs},NIR + R_{rs},RED} \end{equation}
où \(R_{rs,NIR}\), \(R_{rs, RED}\) sont les valeurs de réflectance dans les bandes proche infrarouge et rouge, respectivement.
[12]:
wavelength_nir = 842 * 1e-9
wavelength_red = 665 * 1e-9
wavelength_swir1 = 1610 * 1e-9
ds_masked_coastline["FDI"] = ds_masked_coastline.nir - (
ds_masked_coastline.red_edge_2 +
(ds_masked_coastline.swir_1 - ds_masked_coastline.red_edge_2) *
((wavelength_nir - wavelength_red) /
(wavelength_swir1 - wavelength_red)) * 10)
ds_masked_coastline = calculate_indices(ds_masked_coastline,
index=['NDVI'],
satellite_mission='s2')
ds_masked_coastline
[12]:
<xarray.Dataset> Size: 18MB
Dimensions: (time: 1, y: 545, x: 513)
Coordinates:
* time (time) datetime64[ns] 8B 2018-10-31T10:19:11
* y (y) float64 4kB 7.068e+05 7.068e+05 ... 6.905e+05 6.905e+05
* x (x) float64 4kB -3.416e+04 -3.412e+04 ... -1.882e+04 -1.88e+04
spatial_ref int32 4B 6933
Data variables:
blue (time, y, x) float64 2MB nan nan nan ... 0.02373 0.02076
green (time, y, x) float64 2MB nan nan nan ... 0.006422 0.006031
red (time, y, x) float64 2MB nan nan nan ... 0.00716 0.007497
red_edge_2 (time, y, x) float64 2MB nan nan nan ... 0.01732 0.01671
nir (time, y, x) float64 2MB nan nan nan ... 0.006143 0.006076
swir_1 (time, y, x) float64 2MB nan nan nan ... 0.007571 0.006508
FDI (time, y, x) float64 2MB nan nan nan ... 0.007084 0.008472
NDVI (time, y, x) float64 2MB nan nan nan ... -0.07645 -0.1047
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refCe code définit les variables affines et CRS (Coordinate Reference System) du jeu de données ds_masked_coastline, qui sont nécessaires pour tracer les données. Il crée ensuite un nouveau jeu de données ds_fdi qui contient les valeurs FDI obtenues à l’étape précédente.
Le graphique de sortie peut être utilisé pour visualiser la distribution des débris flottants dans les plans d’eau au fil du temps.
[13]:
ds_fdi = ds_masked_coastline["FDI"].squeeze()
ds_ndvi = ds_masked_coastline["NDVI"].squeeze()
# Calculate the number of rows and columns needed
try:
num_plots = ds_fdi.sizes['time']
except KeyError:
num_plots = 1 # if only one timestamp
num_cols = 2
num_rows = num_plots
# Create the figure and subplots
fig, axs = plt.subplots(num_rows, num_cols, figsize=(15, 5 * num_rows))
# Loop over each timestamp and plot the corresponding FDI and NDVI images
for i in range(num_plots):
time_val = str(ds_masked_coastline["FDI"].time.values[i]
)[:-13] # Extract timestamp and convert to string
# Plot FDI
if num_plots == 1:
ds_fdi.plot(ax=axs[0], cmap='RdBu_r')
axs[0].set_title(f'FDI - Timestamp: {time_val}')
else:
ds_fdi.isel(time=i).plot(ax=axs[i, 0], cmap='RdBu_r')
axs[i, 0].set_title(f'FDI - Timestamp: {time_val}')
# Plot NDVI
if num_plots == 1:
ds_ndvi.plot(ax=axs[1], cmap='RdYlGn')
axs[1].set_title(f'NDVI - Timestamp: {time_val}')
else:
ds_ndvi.isel(time=i).plot(ax=axs[i, 1], cmap='RdYlGn')
axs[i, 1].set_title(f'NDVI - Timestamp: {time_val}')
# Remove any unused subplots
for i in range(num_plots, num_rows):
fig.delaxes(axs[i, 0])
fig.delaxes(axs[i, 1])
plt.tight_layout()
plt.show()
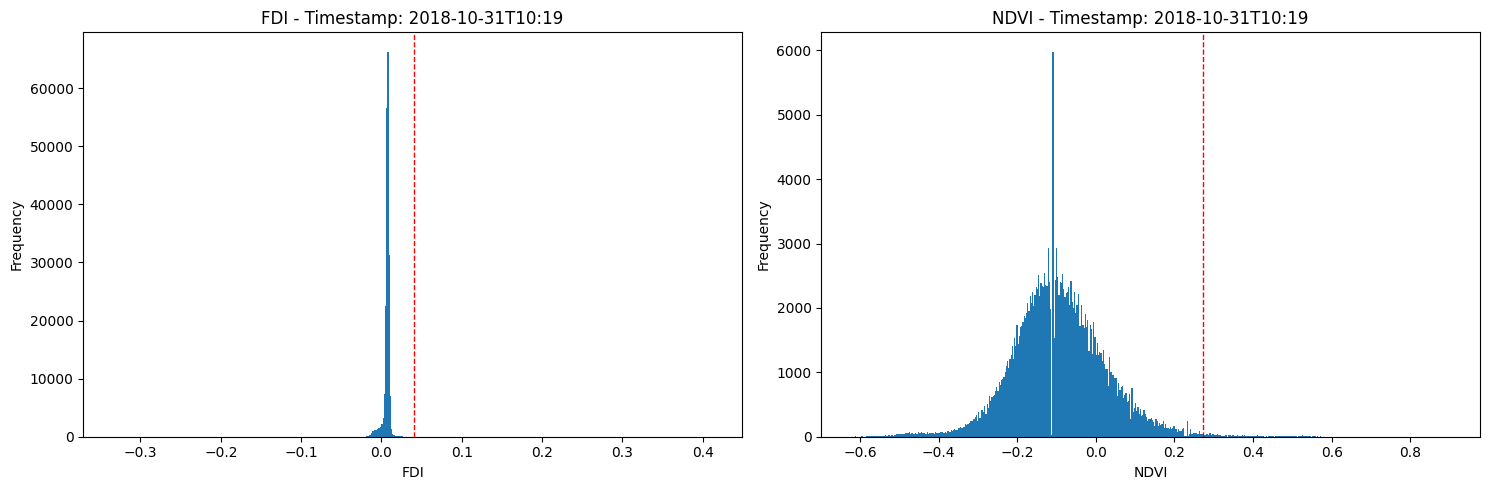
Sélectionner et appliquer le seuil
Le meilleur seuil pour identifier les débris du FDI dépendra des caractéristiques de vos données et de l’application spécifique sur laquelle vous travaillez.
Une façon de déterminer le meilleur seuil est de créer un histogramme des valeurs de l’IDE et de l’inspecter visuellement pour identifier une valeur seuil qui sépare la distribution en deux groupes distincts, l’un représentant les débris marins et l’autre représentant les débris non marins.
Seuil pour chaque horodatage et histogrammes de tracé
La règle des 3 sigma est une méthode statistique utilisée pour déterminer si un point de données est une valeur aberrante, c’est-à-dire qu’il est significativement différent des autres points de données. Dans ce cas, nous l’avons utilisée pour identifier les pixels de l’imagerie satellite susceptibles d’être des débris marins.
Pour ce faire, nous avons d’abord calculé la moyenne et l’écart type des valeurs de tous les pixels de l’imagerie satellite. Nous avons ensuite fixé un seuil à 3 écarts types au-dessus de la moyenne, ce qui signifie que tout pixel ayant une valeur supérieure à ce seuil a été classé comme un débris marin.
Tracez des histogrammes des valeurs FDI et NDVI pour chaque horodatage, la valeur seuil étant représentée par une ligne verticale en pointillés rouges. C’est un bon moyen de visualiser la distribution des valeurs FDI et NDVI et la relation entre la valeur seuil et les données.
[14]:
fdi_values = ds_fdi.values
ndvi_values = ds_ndvi.values
# Calculate thresholds for each timestamp
threshold_per_timestamp_fdi = []
threshold_per_timestamp_ndvi = []
if len(fdi_values.shape) == 2:
# Only one timestamp
fdi_values = fdi_values[None, :] # Add time dimension
ndvi_values = ndvi_values[None, :] # Add time dimension
# FDI threshold calculation
fdi_values_i = fdi_values[0, :]
fdi_values_i = fdi_values_i[~np.isnan(fdi_values_i)]
threshold_i_fdi = np.mean(fdi_values_i) + (3 * np.std(fdi_values_i))
threshold_per_timestamp_fdi.append(threshold_i_fdi)
# NDVI threshold calculation
ndvi_values_i = ndvi_values[0, :]
ndvi_values_i = ndvi_values_i[~np.isnan(ndvi_values_i)]
threshold_i_ndvi = np.mean(ndvi_values_i) + (3 * np.std(ndvi_values_i))
threshold_per_timestamp_ndvi.append(threshold_i_ndvi)
else:
# Multiple timestamps
for i in range(fdi_values.shape[0]):
# Remove missing values for this timestamp
fdi_values_i = fdi_values[i, :]
ndvi_values_i = ndvi_values[i, :]
fdi_values_i = fdi_values_i[~np.isnan(fdi_values_i)]
ndvi_values_i = ndvi_values_i[~np.isnan(ndvi_values_i)]
# FDI threshold calculation
threshold_i_fdi = np.mean(fdi_values_i) + (3 * np.std(fdi_values_i))
threshold_per_timestamp_fdi.append(threshold_i_fdi)
# NDVI threshold calculation
threshold_i_ndvi = np.mean(ndvi_values_i) + (3 * np.std(ndvi_values_i))
threshold_per_timestamp_ndvi.append(threshold_i_ndvi)
# Print the calculated thresholds for FDI and NDVI
print("Threshold per timestamp (FDI):", threshold_per_timestamp_fdi)
print("Threshold per timestamp (NDVI):", threshold_per_timestamp_ndvi)
# Create the figure and subplots
fig, axs = plt.subplots(num_rows, num_cols, figsize=(15, 5 * num_rows))
# Loop over each timestamp and plot the corresponding histograms for FDI and NDVI
for i in range(num_plots):
time_val = str(ds_masked_coastline["FDI"].time.values[i]
)[:-13] # Extract timestamp and convert to string
# FDI histogram
if num_plots == 1:
axs[0].hist(fdi_values.flatten(), bins=500)
axs[0].axvline(threshold_per_timestamp_fdi[i],
color='r',
linestyle='dashed',
linewidth=1)
axs[0].set_xlabel('FDI')
axs[0].set_ylabel('Frequency')
axs[0].set_title(f'FDI - Timestamp: {time_val}')
else:
axs[i, 0].hist(fdi_values[i].flatten(), bins=500)
axs[i, 0].axvline(threshold_per_timestamp_fdi[i],
color='r',
linestyle='dashed',
linewidth=1)
axs[i, 0].set_xlabel('FDI')
axs[i, 0].set_ylabel('Frequency')
axs[i, 0].set_title(f'FDI - Timestamp: {time_val}')
# NDVI histogram
if num_plots == 1:
axs[1].hist(ndvi_values.flatten(), bins=500)
axs[1].axvline(threshold_per_timestamp_ndvi[i],
color='r',
linestyle='dashed',
linewidth=1)
axs[1].set_xlabel('NDVI')
axs[1].set_ylabel('Frequency')
axs[1].set_title(f'NDVI - Timestamp: {time_val}')
else:
axs[i, 1].hist(ndvi_values[i].flatten(), bins=500)
axs[i, 1].axvline(threshold_per_timestamp_ndvi[i],
color='r',
linestyle='dashed',
linewidth=1)
axs[i, 1].set_xlabel('NDVI')
axs[i, 1].set_ylabel('Frequency')
axs[i, 1].set_title(f'NDVI - Timestamp: {time_val}')
# Remove any unused subplots
for i in range(num_plots, num_rows):
fig.delaxes(axs[i, 0])
fig.delaxes(axs[i, 1])
plt.tight_layout()
plt.show()
Threshold per timestamp (FDI): [0.040867291239177636]
Threshold per timestamp (NDVI): [0.27210095592438976]
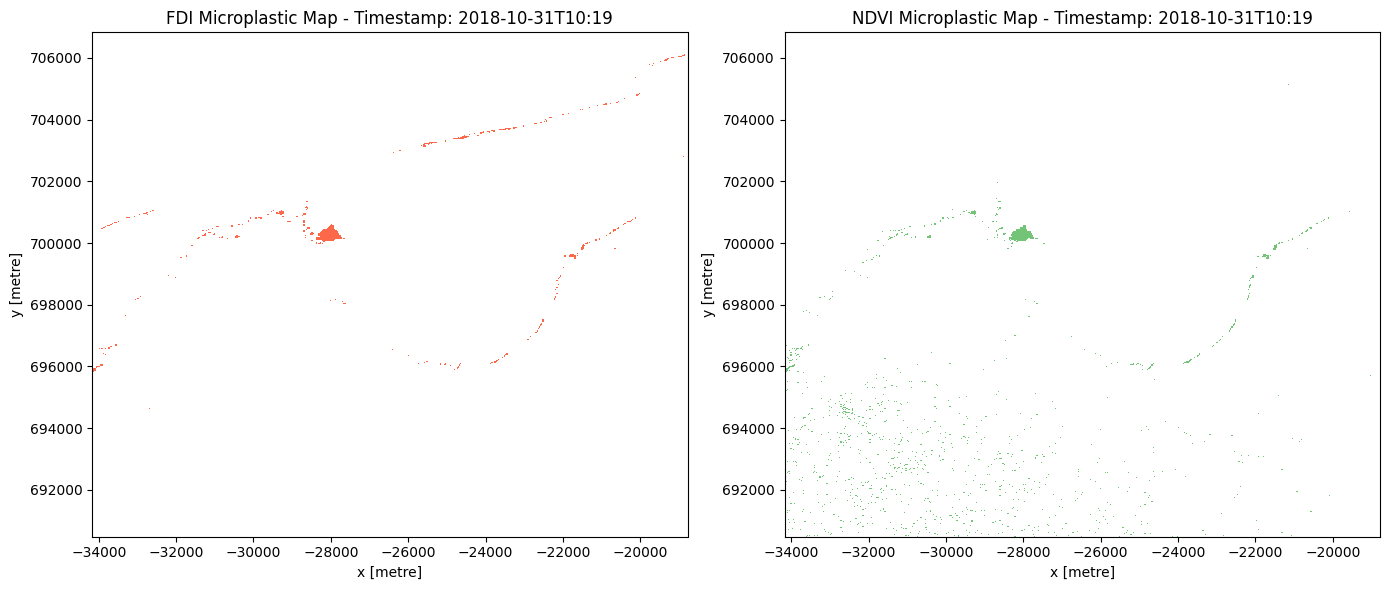
Créer et tracer des masques binaires FDI et NDVI
Ce code crée une série de masques binaires pour un ensemble de données d’images satellite à différentes étapes temporelles. Les masques sont créés sur la base d’une valeur seuil calculée pour chaque étape temporelle, et les zones résultantes des masques qui correspondent à la pollution par les débris marins sont calculées et stockées dans une liste. Le nombre de débris marins dans la zone d’intérêt pour chaque étape temporelle est également calculé et stocké dans une liste distincte. Les masques sont ensuite tracés sous forme de sous-parcelles dans un format de grille avec des couleurs personnalisées. Le code supprime également toutes les sous-parcelles inutilisées et ajuste l’espacement entre les sous-parcelles. Le résultat final est une figure montrant les masques pour chaque étape temporelle et la zone de débris marins correspondante et le nombre de débris marins.
[15]:
# Create binary maps based on thresholds
binary_fdi = ds_fdi > threshold_per_timestamp_fdi[0]
binary_ndvi = ds_ndvi > threshold_per_timestamp_ndvi[0]
# Create the figure and subplots
fig, axs = plt.subplots(nrows=num_plots, ncols=2, figsize=(14, 6 * num_plots))
# Loop over each timestamp and plot the corresponding debris maps
for i in range(num_plots):
time_val = str(ds_masked_coastline["FDI"].time.values[i]
)[:-13] # Extract timestamp and convert to string
# FDI debris map
if num_plots == 1:
debris_map_fdi = binary_fdi == 1
debris_map_fdi = debris_map_fdi.where(
debris_map_fdi, np.nan)
plot_fdi = debris_map_fdi.plot(ax=axs[0], cmap='Reds')
axs[0].set_title(f'FDI debris Map - Timestamp: {time_val}')
else:
debris_map_fdi = binary_fdi.isel(time=i) == 1
debris_map_fdi = debris_map_fdi.where(
debris_map_fdi, np.nan)
plot_fdi = debris_map_fdi.plot(ax=axs[i, 0], cmap='Reds')
axs[i, 0].set_title(f'FDI debris Map - Timestamp: {time_val}')
# NDVI debris map
if num_plots == 1:
debris_map_ndvi = binary_ndvi == 1
debris_map_ndvi = debris_map_ndvi.where(
debris_map_ndvi, np.nan)
plot_ndvi = debris_map_ndvi.plot(ax=axs[1], cmap='Greens')
axs[1].set_title(f'NDVI debris Map - Timestamp: {time_val}')
else:
debris_map_ndvi = binary_ndvi.isel(time=i) == 1
debris_map_ndvi = debris_map_ndvi.where(
debris_map_ndvi, np.nan)
plot_ndvi = debris_map_ndvi.plot(ax=axs[i, 1], cmap='Greens')
axs[i, 1].set_title(f'NDVI debris Map - Timestamp: {time_val}')
# Hide color bar
plot_fdi.colorbar.remove()
plot_ndvi.colorbar.remove()
# Remove any unused subplots
for i in range(num_plots, num_rows):
fig.delaxes(axs[i, 0])
fig.delaxes(axs[i, 1])
plt.tight_layout()
plt.show()
Créez une carte binaire unique de pixels classés comme débris en utilisant à la fois FDI et NDVI.
[16]:
# Determine the number of plots
num_plots = 1 if 'time' not in ds_fdi.dims else ds_fdi.sizes['time']
# Create the figure and subplots
fig, axs = plt.subplots(nrows=num_plots,
ncols=1,
figsize=(7, 6 * num_plots),
squeeze=False)
# Create an array to store the debris masks
debris_masks = []
# Loop over each timestamp and plot the debris map
for i in range(num_plots):
if num_plots > 1:
time_val = str(ds_masked_coastline["FDI"].time.values[i]
)[:-13] # Extract timestamp and convert to string
ax = axs[i, 0]
debris_map = binary_fdi.isel(time=i) & binary_ndvi.isel(time=i)
else:
time_val = str(ds_masked_coastline["FDI"].time.values
)[:-13] # Extract timestamp and convert to string
ax = axs[0, 0]
debris_map = binary_fdi & binary_ndvi
# Store the debris map in the array
debris_masks.append(debris_map)
# Plot the debris map with custom colormap
debris_map.where(debris_map == 1).plot(ax=ax,
cmap='binary',
vmin=0,
vmax=1)
ax.set_title(f'Predicted debris: {time_val}')
# Remove the colorbar
ax.collections[0].colorbar.remove()
plt.tight_layout()
plt.show()
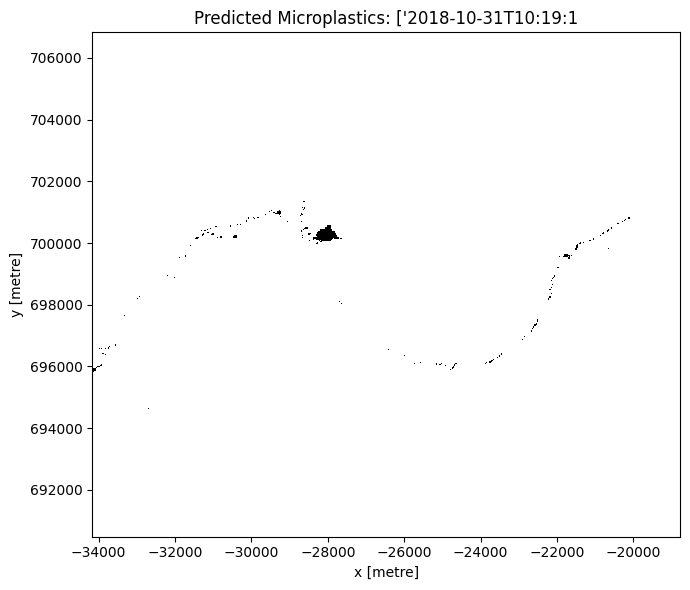
Vectoriser les pixels de débris marins identifiés pour un horodatage de votre choix
[17]:
debris_gdf = xr_vectorize(debris_masks[0],
crs=ds_masked_coastline.crs,
mask=debris_masks[0] == 1)
debris_gdf.explore()
[17]:
Évaluation de la précision
Ce bloc-notes utilise le jeu de données NASA Marine Debris for Object Detection in Planetscope Imagery comme données de validation pour la zone d’intérêt (horodatage : (2018-10-31)). Le jeu de données, fourni au format geojson, provient du dossier Supplementary_data. Il comprend des données vectorielles annotées, notamment des cadres de délimitation et des coordonnées géographiques, servant de vérité fondamentale pour la détection d’objets de débris marins.
Dans l’évaluation de la précision, il est essentiel de reconnaître que les débris marins flottants observés dans l’image Sentinel utilisée peuvent s’être déplacés entre son moment d’acquisition et l’acquisition de l’imagerie PlanetScope utilisée pour créer l’ensemble de données NASA Marine Debris for Object Detection in Planetscope Imagery. En raison de l’écart temporel et de la nature dynamique des objets flottants, il est difficile de déterminer les positions exactes des débris au moment des deux acquisitions d’images. Pour tenir compte de cette incertitude, une zone tampon a été introduite autour de l’ensemble de données de validation, permettant un mouvement potentiel des débris pendant le laps de temps entre les deux ensembles de données. Cette approche reconnaît la possibilité d’un déplacement et fournit une évaluation plus complète de la précision en prenant en compte les changements potentiels dans les positions des débris marins flottants.
[18]:
# Load the NASA Marine Debris Dataset for Object Detection in Planetscope Imagery dataset
marine_debris_dataset = gpd.read_file(
f"../Supplementary_data/Floating_marine_debris/nasa_marine_debris_labels_ghana.geojson"
)
marine_debris_dataset = marine_debris_dataset.to_crs('epsg:6933')
fig, ax = plt.subplots(figsize=(15, 10))
# Plot the identified debris
debris_gdf.plot(ax=ax, facecolor='yellow')
# Plot marine_debris_dataset on the second axis
rgb(ds.isel(time=0), ax=ax)
marine_debris_dataset.plot(ax=ax, facecolor='none', edgecolor='blue')
ax.set_title('Detected debris and NASA Marine Debris Dataset')
# Create custom legend handles and labels
legend_handles = [
mpatches.Patch(facecolor='none',
edgecolor='blue',
label='NASA Marine Dataset'),
mpatches.Patch(facecolor='yellow', label='Predicted debris'),
]
ax.legend(handles=legend_handles)
plt.show()
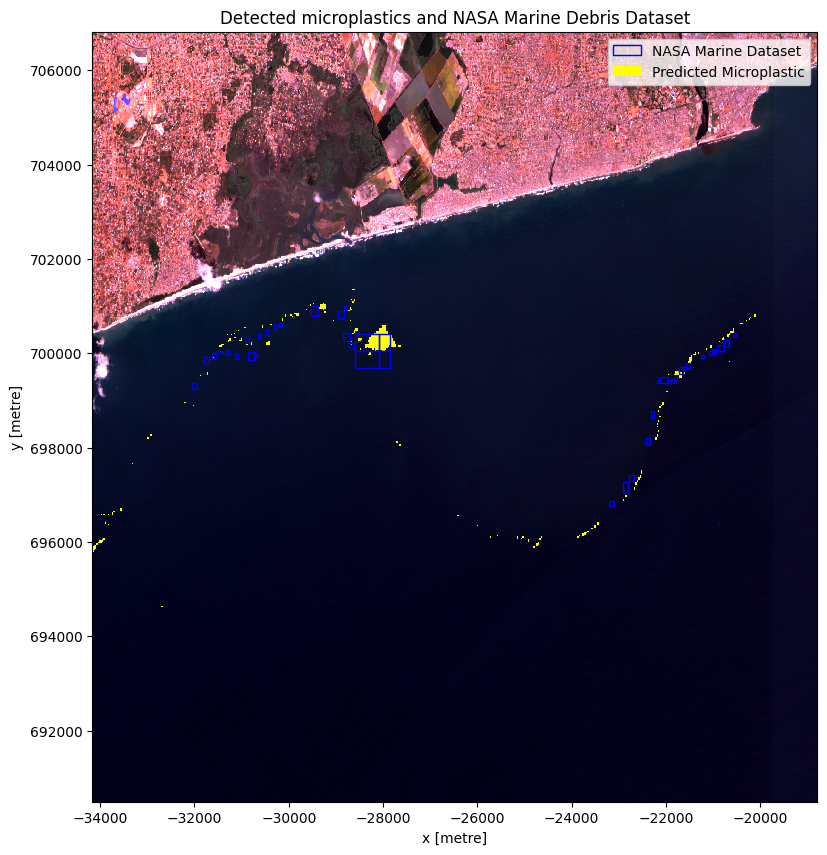
Le graphique ci-dessus montre que les débris marins prédits et les données de validation ne sont pas parfaitement alignés, ce qui est attendu en raison du mouvement des objets marins flottants. Pour tenir compte de cela, il est nécessaire d’introduire des tampons autour des données de validation, compte tenu du mouvement potentiel des débris marins entre le moment de la capture de l’image Sentinel et l’imagerie Planetscope utilisée pour la validation. Ces tampons permettent une analyse plus robuste, prenant en compte le comportement dynamique des débris marins et permettant un examen complet des emplacements potentiels des débris marins.
[19]:
# Convert geopolygon_gdf to EPSG 6933
geopolygon_gdf = geopolygon_gdf.to_crs("EPSG:6933")
# Plot the marine dataset buffers, debris, geopolygon, and clipped coastline
fig, ax = plt.subplots(figsize=(15, 10))
# Create buffers around the marine debris points
buffer_distance = 100 # Specify the buffer distance in the CRS units (meters)
marine_debris_dataset['buffer'] = marine_debris_dataset.geometry.buffer(
buffer_distance)
# Plot the rgb image
rgb(ds.isel(time=0), ax=ax)
# Plot the marine dataset buffers
buffer_gdf = gpd.GeoDataFrame(geometry=marine_debris_dataset['buffer'])
buffer_gdf.plot(ax=ax, facecolor='none', edgecolor='blue')
# Plot the debris
debris_gdf.plot(ax=ax, facecolor='yellow')
# Plot the geopolygon
geopolygon_gdf.plot(ax=ax, facecolor='none', edgecolor='red')
# Set plot title and labels
ax.set_title('Detected debris and NASA Marine Debris Dataset buffers')
ax.set_xlabel('Longitude')
ax.set_ylabel('Latitude')
# Create custom legend handles and labels
legend_handles = [
mpatches.Patch(facecolor='yellow', label='Predicted marine debris'),
mpatches.Patch(facecolor='none',
edgecolor='blue',
label='NASA Marine Dataset Buffer'),
mpatches.Patch(facecolor='none', edgecolor='red', label='Area of Interest'),
]
# Add legend
ax.legend(handles=legend_handles)
plt.show()
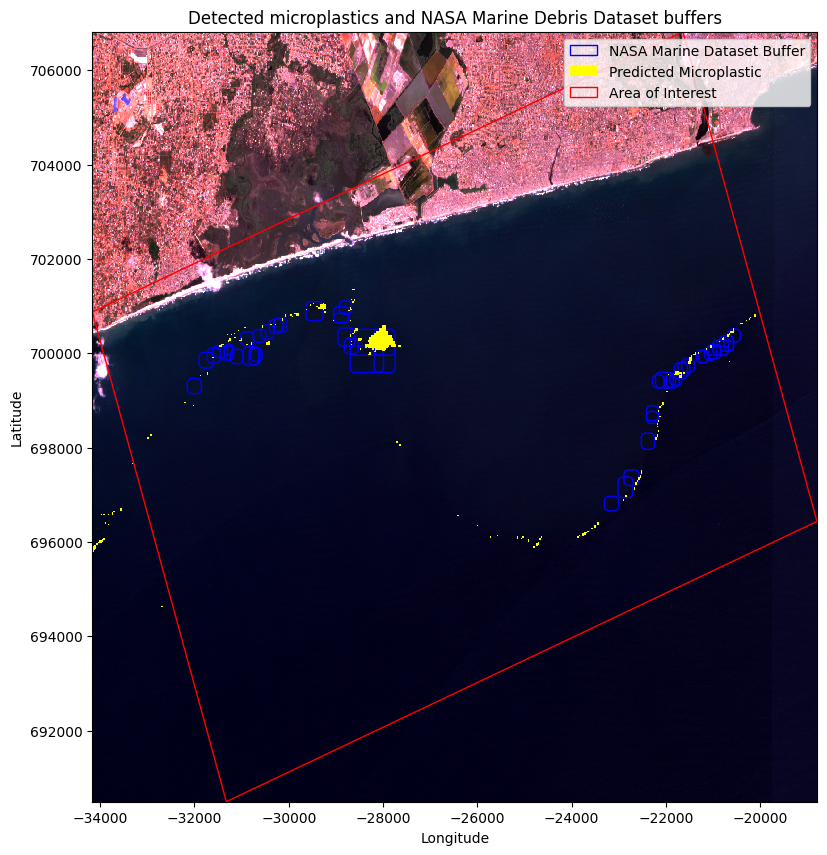
Dans cette évaluation de la précision, nous avons cherché à évaluer les performances de la détection des débris marins dans l’imagerie satellitaire en la comparant aux tampons de l’ensemble de données marines représentant les zones potentielles de débris marins. Pour garantir la précision, nous avons attribué des identifiants uniques à chaque tampon et à chaque polygone de débris marins. En effectuant une opération de jointure spatiale, nous avons identifié les zones de chevauchement entre les tampons et les débris marins détectés. L’objectif était de déterminer combien de tampons de l’ensemble de données marines contenaient des débris marins. Grâce à cette approche, nous avons évité de surcompter les tampons contenant plusieurs débris marins, car chaque tampon n’a été compté qu’une seule fois, quel que soit le nombre de débris marins qui se croisaient.
Avertissement : Il est important de noter que les résultats de l’évaluation de la précision dépendent de la taille du tampon défini. Dans ce cas, la taille du tampon a été sélectionnée de manière arbitraire et non sur la base de critères spécifiques ou de directives scientifiques. Par conséquent, le pourcentage de précision obtenu doit être interprété dans le contexte de la taille du tampon choisie. Des tailles de tampon différentes peuvent donner des résultats de précision différents.
[20]:
# Assign a unique identifier to each marine dataset buffer
buffer_gdf['buffer_id'] = range(len(buffer_gdf))
# Assign a unique identifier to each debris polygon
debris_gdf['debris_id'] = range(len(debris_gdf))
# Spatial join between the marine dataset buffers and the debris
intersection = gpd.overlay(buffer_gdf, debris_gdf, how='intersection')
# Count the number of unique buffer IDs with intersecting debris
num_buffers_with_debris = len(intersection['buffer_id'].unique())
# Calculate the total number of marine dataset buffers
num_buffers = len(buffer_gdf)
# Calculate the accuracy
accuracy = (num_buffers_with_debris / num_buffers) * 100
# Print the accuracy assessment
print("Accuracy Assessment:")
print(f"Number of marine dataset buffers: {num_buffers}")
print(
f"Number of marine dataset buffers with debris: {num_buffers_with_debris}"
)
print(f"Accuracy: {accuracy:.2f}%")
Accuracy Assessment:
Number of marine dataset buffers: 51
Number of marine dataset buffers with debris: 36
Accuracy: 70.59%
L’évaluation de la précision de l’identification des débris marins dans une zone tampon de 100 m de tampons de données marines a révélé des résultats prometteurs. Bien que les tampons et les débris marins détectés ne se chevauchent pas parfaitement en raison du mouvement et des variations naturelles, l’examen visuel a indiqué un modèle discernable de présence de débris marins qui correspondait à notre méthode d’identification. Bien que le taux de précision de 70,59 % indique que notre approche a capturé une partie importante des débris marins réels dans les tampons, il est important de prendre en compte les preuves visuelles qui soutiennent l’efficacité de notre méthode. Le décalage observé entre les débris marins détectés et les tampons est attendu en raison de la nature dynamique de la dispersion des débris marins dans les environnements marins. Dans l’ensemble, les observations visuelles renforcent notre confiance dans l’évaluation de la précision, soulignant la capacité de notre méthode à identifier les débris marins même lorsque l’alignement spatial parfait n’est pas atteint.
Biermann, L., Clewley, D., Martinez-Vicente, V., Topouzelis, K., 2020. Détection de plaques de plastique dans les eaux côtières à l’aide de données satellitaires optiques. Sci. Rep. 10, 1–10. https://doi.org/10.1038/s41598-020-62298-z
Themistocleous, K., Papoutsa, C., Michaelides, S., Hadjimitsis, D., 2020. Enquête sur la détection de déchets plastiques flottants depuis l’espace à l’aide de l’imagerie Sentinel-2. Remote Sens. 12. https://doi.org/10.3390/RS12162648
Topouzelis, K., Papageorgiou, D., Karagaitanakis, A., Papakonstantinou, A., Ballesteros, M.A., 2020. Télédétection de cibles artificielles flottantes en plastique à la surface de la mer avec Sentinel2 et des systèmes aériens sans pilote (projet de déchets plastiques 2019). Remote Sens. 12. https://doi.org/10.3390/rs12122013
Topouzelis, K., Papakonstantinou, A., Garaba, S.P., 2019. Détection de plastiques flottants à partir de systèmes satellitaires et aériens sans pilote (Plastic Litter Project 2018). Int. J. Appl. Earth Obs. Geoinf. 79, 175–183. https://doi.org/10.1016/j.jag.2019.03.011
Informations Complémentaires
Licence Le code de ce notebook est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>`__.
Les données de Digital Earth Africa sont sous licence Creative Commons Attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack DE Africa <https://digitalearthafrica.slack.com/> ou sur le GIS Stack Exchange <https://gis.stackexchange.com/questions/ask?tags=open-data-cube> en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment `ici <https://gis.stackexchange.com/questions/tagged/open-data-
Si vous souhaitez signaler un problème avec ce notebook, vous pouvez en déposer un sur Github.
Version de Datacube compatible
[21]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[21]:
'2025-01-16'