Cube dans une boîte (CiaB)
Pourquoi utiliser le Cube in a Box ?
Le Cube in a Box et le Digital Earth Africa Analysis Sandbox sont tous deux des déploiements de l’Open Data Cube.
Le Digital Earth Africa Analysis Sandbox est un déploiement cloud de l’Open Data Cube. Cet environnement est hébergé et géré en externe par Digital Earth Africa et se compose de :
Une instance de cloud computing d’Amazon Web Service
Une plateforme JupyterLab pour réaliser des analyses
Accès direct à une instance Open Data Cube contenant toutes les données d’observation de la Terre de Digital Earth Africa.
Bloc-notes Jupyter préchargés montrant comment utiliser Open Data Cube pour effectuer une analyse d’observation de la Terre
Le Sandbox est le moyen le plus simple de démarrer avec Open Data Cube. Il fournit une ressource de calcul limitée, mais gratuite, pour explorer les données d’observation de la Terre et les outils d’analyse de Digital Earth Africa pour la génération de rapports ad hoc et le développement rapide de nouveaux algorithmes. Étant un environnement géré en externe, le Sandbox permet uniquement l’accès aux produits indexés par Digital Earth Africa dans l’instance Open Data Cube.
Si vous souhaitez installer Open Data Cube sur vos propres ressources, que ce soit localement ou sur un service cloud tel qu’Amazon Web Services (AWS), alors Cube in a Box est une excellente option. Cube in a Box (CIAB) est une installation de référence distribuable et prête à l’emploi d’un Open Data Cube indépendant. Il vous permet de créer votre propre environnement Open Data Cube, similaire au Sandbox. Cette instance Open Data Cube est spécifiquement maintenue et personnalisée par l’utilisateur. Vous pouvez indexer les données d’observation de la Terre de Digital Earth Africa et indexer (ajouter) vos propres données, qu’elles soient commerciales, in situ ou dérivées, dans votre instance Open Data Cube autogérée.
Premiers pas avec Cube in a Box
L’installation de Cube in a Box nécessite que Docker et Docker-Compose soient installés. Pour installer Cube in a Box de Digital Earth Africa, clonez le dépôt Github digitalearthafrica/cube-in-a-box et suivez les instructions d’installation détaillées.
Vous pouvez déployer Cube in a Box sur AWS à l’aide de ce lien magique <https://console.aws.amazon.com/cloudformation/home?#/stacks/new?stackName=cube-in-a-box&templateURL=https://deafrica-dev-cfn.s3.af-south-1.amazonaws.com/cube-in-a-box/cube-in-a-box-cloudformation.yml>. Vous devez être connecté à la console AWS pour effectuer le déploiement à l’aide de cette URL. Une fois connecté, cliquez sur le lien et suivez les invites, notamment les paramètres d’une zone de délimitation d’intérêt, le type d’instance EC2 et le mot de passe pour Jupyter.
Il existe un bloc-notes fourni dans le référentiel Github « Cube in a Box <https://github.com/digitalearthafrica/cube-in-a-box/blob/main/notebooks/Indexing_More_Data.ipynb> » qui montre comment indexer davantage de données dans Cube in a Box.
Informations techniques
L’Open Data Cube est une collection de logiciels conçue pour :
Cataloguer de grandes quantités de données d’observation de la Terre
Fournir une API basée sur Python pour des requêtes et un accès aux données hautes performances
Donnez aux scientifiques et aux autres utilisateurs la possibilité d’effectuer facilement des analyses exploratoires de données
Permettre un traitement évolutif à l’échelle du continent des données stockées
Suivre la provenance de toutes les données contenues pour permettre le contrôle de la qualité et les mises à jour
L’Open Data Cube est composé des éléments suivants :
Données : Les données peuvent être stockées sur un système de fichiers, soit dans des répertoires locaux de fichiers GeoTIFF ou NetCDF, soit stockées sur un magasin d’objets comme S3 d’AWS sous forme de GeoTIFF optimisés pour le cloud.
Un index : il s’agit d’une base de données PostgreSQL qui contient un index pointant vers l’emplacement de stockage des données. L’index permet à un utilisateur de demander des données à un moment et à un endroit précis, sans avoir besoin de savoir précisément où sont stockés les fichiers requis et comment y accéder.
Logiciel : La bibliothèque Python Open Data Cube est le cœur de l’ODC. D’autres logiciels incluent Jupyter Notebooks construits sur la bibliothèque Python ODC que l’on peut utiliser pour explorer les données indexées.
Figure 1 : Composants techniques du cube Open Data
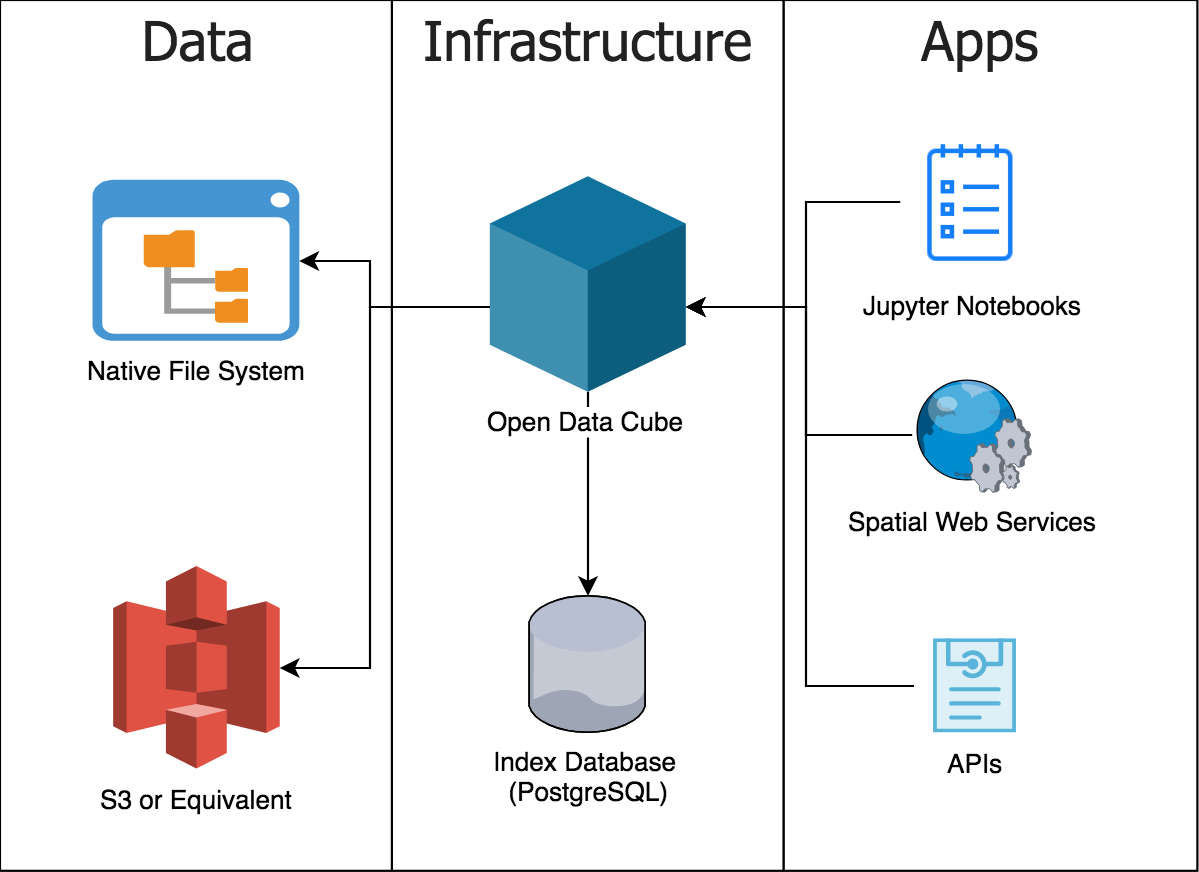
Image tirée de « Qu’est-ce que l’Open Data Cube ? » par Alex Leith.
L’ODC peut être déployé sur différentes plates-formes informatiques. Les déploiements possibles incluent :
Déploiement local (par exemple, poste de travail haut de gamme)
Cloud (par exemple, Amazon Web Services)
Infrastructure de calcul haute performance (par exemple, NCI)