Anomalies de précipitations provenant des données de la station de précipitations infrarouges du Climate Hazards Group (CHIRPS)
Produits utilisés : rainfall_chirps_monthly
Mots-clés : datasets; CHIRPS, climat, précipitations, mensuel
Aperçu
Les anomalies pluviométriques sont des écarts de précipitations par rapport aux moyennes à long terme. Elles sont utiles pour identifier les périodes humides et sèches qui peuvent être liées à des phénomènes influencés par le climat, tels que les inondations, le débit des rivières et la production agricole.
Description
Dans cet exemple concret, nous allons calculer les anomalies de précipitations pour un pays africain sélectionné à l’aide de l’ensemble de données mensuelles sur les précipitations CHIRPS. L’anomalie standardisée est calculée comme suit :
\begin{equation} \text{Anomalie normalisée}=\frac{x-m}{s} \end{equation}
x est la moyenne saisonnière, m est la moyenne à long terme et s est l’écart type à long terme.
Cela signifie que nous avons besoin d’une période de référence à long terme (m) et d’une période d’intérêt (x) pour lesquelles nous calculerons les anomalies. Ce bloc-notes nomme les ensembles de données « ds_rf_m » et « ds_rf_x » en conséquence.
Le carnet décrit :
Chargement d’un fichier de formes pour les pays africains et sélection d’un seul pays
Chargement des données de précipitations et masquage de celles-ci en fonction du pays sélectionné.
Calcul des anomalies mensuelles de précipitations et représentation du résultat, agrégé dans l’espace, sous forme de graphique à barres.
Calcul et représentation spatiale des anomalies mensuelles de précipitations.
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Charger des paquets
[1]:
%matplotlib inline
# Force GeoPandas to use Shapely instead of PyGEOS
# In a future release, GeoPandas will switch to using Shapely by default.
import os
os.environ['USE_PYGEOS'] = '0'
import datacube
import numpy as np
import pandas as pd
import geopandas as gpd
import xarray as xr
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from odc.geo.geom import Geometry
from odc.geo import CRS
from deafrica_tools.spatial import xr_rasterize
from deafrica_tools.dask import create_local_dask_cluster
Configurer un cluster Dask
Dask peut être utilisé pour mieux gérer l’utilisation de la mémoire et effectuer l’analyse en parallèle. Pour une introduction à l’utilisation de Dask avec Digital Earth Africa, consultez le Dask notebook.
Remarque : nous vous recommandons d’ouvrir la fenêtre de traitement Dask pour afficher les différents calculs en cours d’exécution ; pour ce faire, consultez la section Tableau de bord Dask en Afrique de l’Ouest du Dask notebook.
Pour utiliser Dask, configurez le cluster de calcul local à l’aide de la cellule ci-dessous.
[2]:
create_local_dask_cluster()
Client
Client-a9724b44-33f3-11f1-830d-4e2ec4a7c32d
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/8787/status |
Cluster Info
LocalCluster
f11f6029
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/8787/status | Workers: 1 |
| Total threads: 4 | Total memory: 26.21 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-d31c6b92-2579-437b-a83b-d77305c683a3
| Comm: tcp://127.0.0.1:45465 | Workers: 0 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/8787/status | Total threads: 0 |
| Started: Just now | Total memory: 0 B |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:43059 | Total threads: 4 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34279/status | Memory: 26.21 GiB |
| Nanny: tcp://127.0.0.1:34533 | |
| Local directory: /tmp/dask-scratch-space/worker-2o4babtm | |
Paramètres d’analyse
La cellule suivante définit des paramètres importants pour l’analyse :
« pays » : dans cette analyse, nous sélectionnerons un pays africain pour masquer l’ensemble de données et l’analyse.
time_m: les précipitations mensuelles CHIRPS sont disponibles à partir de 1981. La moyenne à long terme des anomalies de précipitations est souvent calculée sur une période de 30 ans, nous utiliserons donc la période de 1981 à 2011 dans cet exemple.time_x: C’est la période pour laquelle nous voulons calculer les anomalies.« résolution » : nous utiliserons 5 000 m, ce qui correspond approximativement à la résolution par défaut indiquée ci-dessus.
dask_chunks: la taille des morceaux dask, dask divise les données en morceaux gérables qui peuvent être facilement stockés en mémoire, par exemple dict(x=1000,y=1000)
L’anomalie standardisée est calculée comme suit :
\begin{equation} \text{Anomalie normalisée}=\frac{x-m}{s} \end{equation}
\(x\) est la moyenne saisonnière, \(m\) est la moyenne à long terme et \(s\) est l’écart type à long terme.
Cela signifie que nous avons besoin d’une période de référence à long terme (m) et d’une période d’intérêt (x) pour lesquelles nous calculerons les anomalies. Ce bloc-notes nomme les ensembles de données « ds_rf_m » et « ds_rf_x » en conséquence.
Si vous exécutez le bloc-notes pour la première fois, conservez les paramètres par défaut ci-dessous. Cela permettra de démontrer le fonctionnement de l’analyse et de fournir des résultats significatifs.
[3]:
# Select a country, for the example we will use Kenya, a complete list of countries is available below.
country = "Kenya"
# Set the range of dates for the climatology, this will be the reference period (m) for the anomaly calculation.
# Standard practice is to use a 30 year period, so we've used 1981 to 2011 in this example.
time_m = ('1981', '2011')
# time period for monthly anomaly (x)
time_x = ('1981', '2021')
# CHIRPS has a spatial resolution of ~5x5 km
resolution = (-5000, 5000)
#size of dask chunks
dask_chunks = dict(x=500,y=500)
Se connecter au datacube
Connectez-vous au datacube pour que nous puissions accéder aux données de DE Africa. Le paramètre « app » est un nom unique pour l’analyse qui est basé sur le nom du fichier du notebook.
[4]:
dc = datacube.Datacube(app='rainfall_anomaly')
Charger le fichier de formes des pays africains
Ce shapefile contient des polygones pour les frontières des pays africains et nous permettra de calculer les anomalies de précipitations dans un pays choisi
[5]:
african_countries = gpd.read_file('../Supplementary_data/Rainfall_anomaly_CHIRPS/african_countries.geojson')
african_countries.explore()
[5]:
Liste des pays
Vous pouvez modifier le pays dans la cellule des paramètres d’analyse pour choisir n’importe quel pays africain. Une liste complète des pays est imprimée ci-dessous.
[6]:
print(np.unique(african_countries.COUNTRY))
['Algeria' 'Angola' 'Benin' 'Botswana' 'Burkina Faso' 'Burundi' 'Cameroon'
'Cape Verde' 'Central African Republic' 'Chad' 'Comoros'
'Congo-Brazzaville' 'Cote d`Ivoire' 'Democratic Republic of Congo'
'Djibouti' 'Egypt' 'Equatorial Guinea' 'Eritrea' 'Ethiopia' 'Gabon'
'Gambia' 'Ghana' 'Guinea' 'Guinea-Bissau' 'Kenya' 'Lesotho' 'Liberia'
'Libya' 'Madagascar' 'Malawi' 'Mali' 'Mauritania' 'Morocco' 'Mozambique'
'Namibia' 'Niger' 'Nigeria' 'Rwanda' 'Sao Tome and Principe' 'Senegal'
'Sierra Leone' 'Somalia' 'South Africa' 'Sudan' 'Swaziland' 'Tanzania'
'Togo' 'Tunisia' 'Uganda' 'Western Sahara' 'Zambia' 'Zimbabwe']
Configuration du polygone
Le pays sélectionné doit être transformé en objet géométrique à utiliser dans la fonction « dc.load() ».
[7]:
idx = african_countries[african_countries['COUNTRY'] == country].index[0]
geom = Geometry(geom=african_countries.iloc[idx].geometry, crs=african_countries.crs)
Charger les données de précipitations
Commençons par examiner les informations produit relatives aux précipitations CHIRPS. Nous pouvons voir qu’elles sont stockées sous forme d’horodatages mensuels et que leur résolution native est d’environ 0,05 degré.
[8]:
dc.list_products().loc[dc.list_products()['name'].str.contains('chirps')]
[8]:
| name | description | license | default_crs | default_resolution | |
|---|---|---|---|---|---|
| name | |||||
| rainfall_chirps_daily | rainfall_chirps_daily | Rainfall Estimates from Rain Gauge and Satelli... | None | EPSG:4326 | Resolution(x=0.05, y=-0.05) |
| rainfall_chirps_monthly | rainfall_chirps_monthly | Rainfall Estimates from Rain Gauge and Satelli... | None | EPSG:4326 | Resolution(x=0.05, y=-0.05) |
Charger les données pour la climatologie à long terme (m)
En utilisant les paramètres d’analyse définis ci-dessus, nous chargerons les données mensuelles de précipitations CHIRPS pour la période de référence de 30 ans (m).
[9]:
query = {'geopolygon': geom,
'time': time_m,
'output_crs': 'epsg:6933',
'resolution': resolution,
'measurements': ['rainfall'],
'dask_chunks':dask_chunks
}
ds_rf = dc.load(product='rainfall_chirps_monthly', **query)
ds_rf
[9]:
<xarray.Dataset> Size: 55MB
Dimensions: (time: 372, y: 238, x: 155)
Coordinates:
* time (time) datetime64[ns] 3kB 1981-01-16T11:59:59.500000 ... 201...
* y (y) float64 2kB 5.875e+05 5.825e+05 ... -5.925e+05 -5.975e+05
* x (x) float64 1kB 3.272e+06 3.278e+06 ... 4.038e+06 4.042e+06
spatial_ref int32 4B 6933
Data variables:
rainfall (time, y, x) float32 55MB dask.array<chunksize=(1, 238, 155), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refMasquer l’ensemble de données sur les précipitations à l’aide de la frontière du pays
Ci-dessous, le polygone du pays est rasterisé de sorte que l’ensemble de données sur les précipitations est masqué dans ce raster.
[10]:
african_countries = african_countries.to_crs('epsg:6933')
mask = xr_rasterize(african_countries[african_countries['COUNTRY'] == country], ds_rf)
#mask the rainfall dataset
ds_rf = ds_rf.where(mask)
# Plot the mask
mask.plot()
[10]:
<matplotlib.collections.QuadMesh at 0x7f50e955fda0>
Calculer la climatologie des précipitations mensuelles
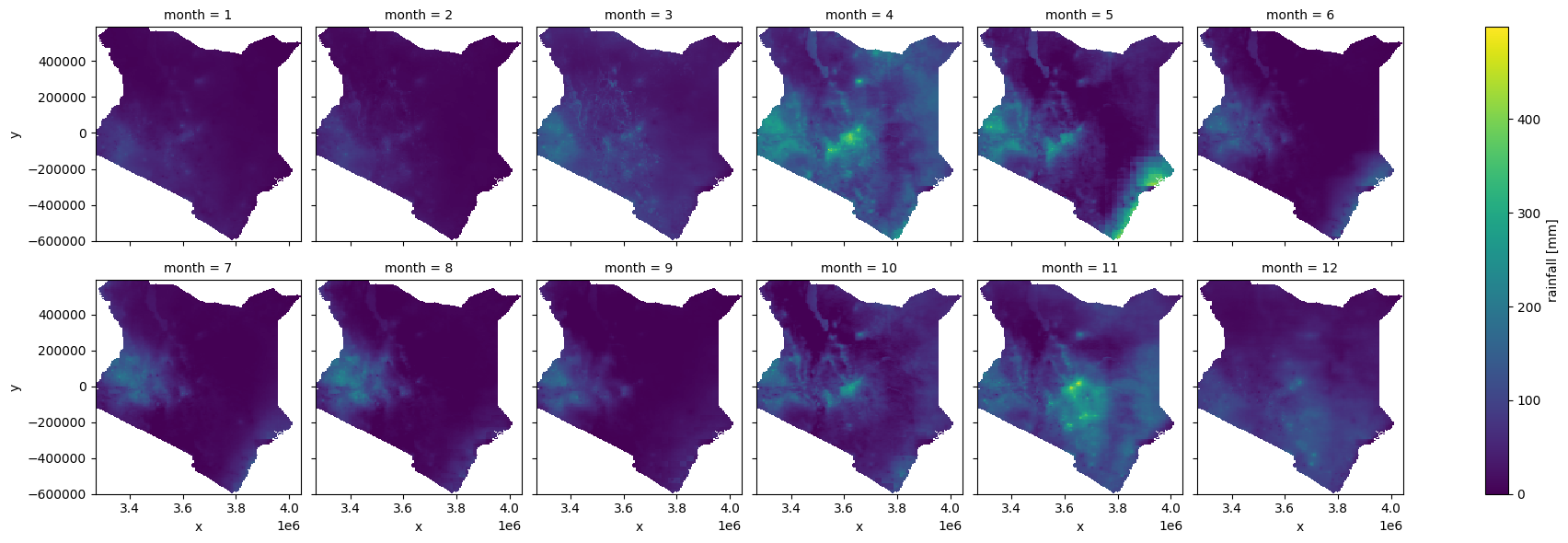
Nous souhaitons capturer à la fois la moyenne mensuelle (c’est-à-dire chaque mois en moyenne sur trente ans) et l’écart type mensuel des précipitations dans le polygone du pays pour chaque année de 1981 à 2011. Tout d’abord, les précipitations sont regroupées par mois et une moyenne est calculée, puis l’écart type du total des précipitations pour chaque mois est calculé.
[11]:
ds_rf_m = ds_rf.where(ds_rf !=-9999.) #convert missing values to NaN
# monthly means
climatology_mean = ds_rf_m.groupby('time.month').mean('time').compute()
#calculate monthly std dev
climatology_std = ds_rf_m.groupby('time.month').std('time').compute()
Nous pouvons maintenant tracer la climatologie moyenne des précipitations, il s’agit des précipitations moyennes (sur 30 ans) pour chaque mois
[12]:
climatology_mean['rainfall'].plot.imshow(cmap='viridis', col='month', col_wrap=6, label=False);
Charger les données pour la période d’anomalie
En utilisant les paramètres d’analyse définis ci-dessus, nous allons charger les données de précipitations CHIRPS pour la période sur laquelle nous souhaitons calculer les anomalies (x). Nous devons également masquer cet ensemble de données au polygone du pays.
[13]:
#load rainfall data for the anomaly period matching the spatial extent of the climatologies
ds_rf_x = dc.load(product='rainfall_chirps_monthly',
like=ds_rf.odc.geobox,
time=time_x,
dask_chunks=dask_chunks)
#mask with country polygon
ds_rf_x=ds_rf_x.where(mask)
Calculer les anomalies standardisées
Nous pouvons visualiser les anomalies spatialement et voir si elles sont associées à certaines caractéristiques du paysage.
Les anomalies spatiales présentées dans les graphiques ci-dessous correspondent-elles aux anomalies agrégées présentées ci-dessus ?
[14]:
stand_anomalies = xr.apply_ufunc(
lambda x, m, s: (x - m) / s,
ds_rf_x.groupby("time.month"),
climatology_mean,
climatology_std,
output_dtypes=[ds_rf_x.rainfall.dtype],
dask="allowed"
).compute()
Tracer les anomalies moyennes des précipitations à travers le pays
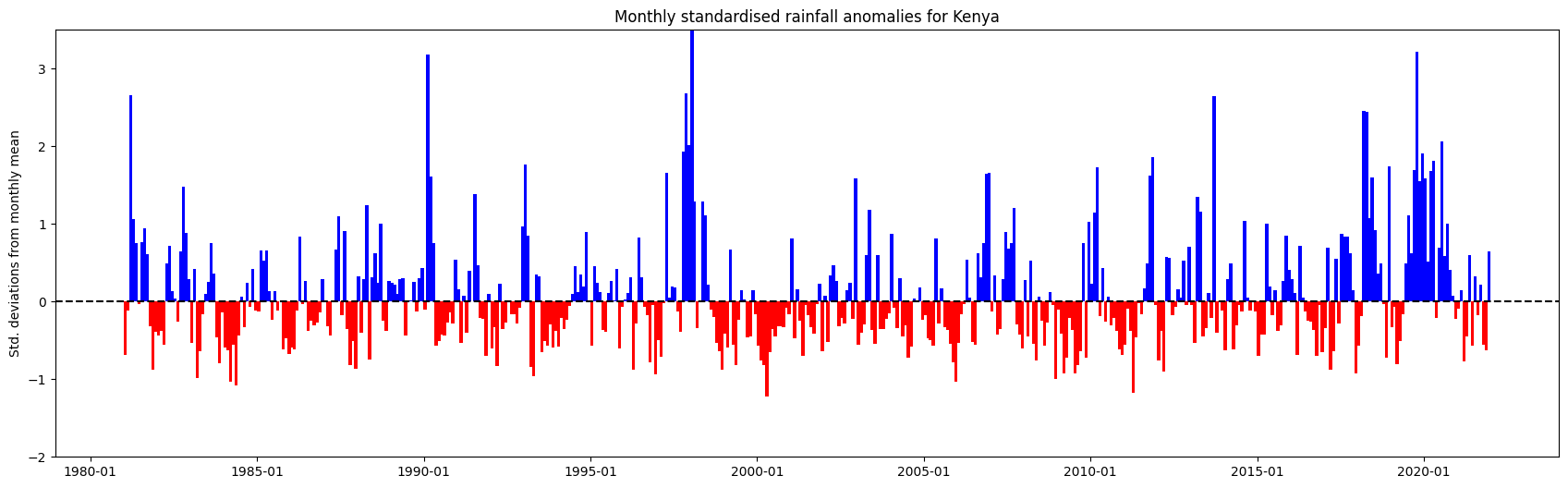
Ci-dessous, la moyenne spatiale est prise afin que nous puissions présenter les anomalies mensuelles agrégées sur l’ensemble du pays sélectionné.
[15]:
spatial_mean_anoms = stand_anomalies.rainfall.mean(['x','y']).to_dataframe().drop(['spatial_ref', 'month'], axis=1)
Ci-dessous, nous traçons un graphique à barres qui montrera l’anomalie moyenne des précipitations à travers le pays
[16]:
fig, ax = plt.subplots(figsize=(21,6))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m"))
ax.set_ylim(-2,3.5)
ax.bar(spatial_mean_anoms.index,
spatial_mean_anoms.rainfall,
width=35, align='center',
color=(spatial_mean_anoms['rainfall'] > 0).map({True: 'b', False: 'r'}))
ax.axhline(0, color='black', linestyle='--')
plt.title('Monthly standardised rainfall anomalies for '+country)
plt.ylabel('Std. deviations from monthly mean');
Graphiques par pixel des anomalies de précipitations
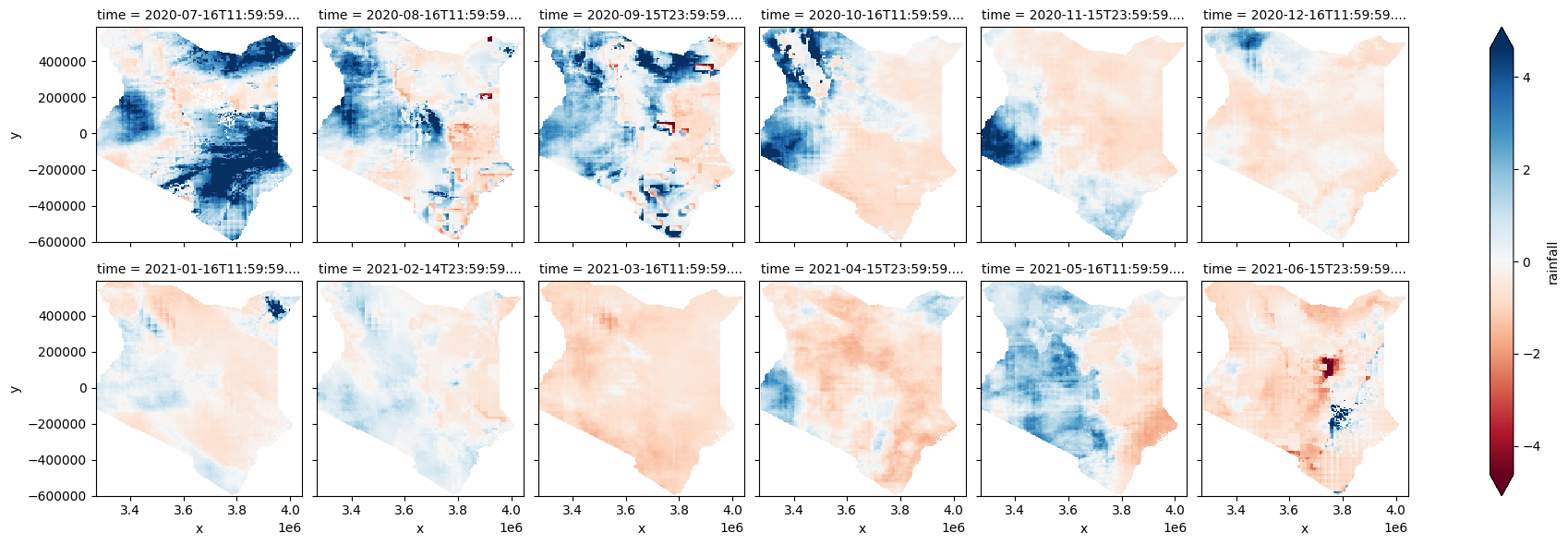
Les anomalies moyennes sur l’ensemble du pays masquent les détails sur la façon dont les anomalies de précipitations sont réparties spatialement dans le pays. Ci-dessous, saisissez une date de « début » et de « fin » (au format « AAAA-MM ») qui se situe dans la plage « time_x » que vous avez saisie dans la section « Paramètres d’analyse » pour tracer les anomalies par pixel pour la plage de dates que vous spécifiez.
[17]:
#Select a time-range to plot
start='2020-07'
end='2021-06'
Tracer les anomalies par pixel
[18]:
stand_anomalies['rainfall'].sel(time=slice(start,end)).plot(cmap='RdBu', label=False, col="time", col_wrap=6, robust=True);
Informations Complémentaires
Licence Le code de ce notebook est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>`__.
Les données de Digital Earth Africa sont sous licence Creative Commons Attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack DE Africa <https://digitalearthafrica.slack.com/> ou sur le GIS Stack Exchange <https://gis.stackexchange.com/questions/ask?tags=open-data-cube> en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment `ici <https://gis.stackexchange.com/questions/tagged/open-data-
Si vous souhaitez signaler un problème avec ce notebook, vous pouvez en déposer un sur Github.
Version de Datacube compatible
[19]:
print(datacube.__version__)
1.9.13
Dernier test :
[20]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[20]:
'2026-04-09'