Surveillance de la chlorophylle-a dans les plans d’eau africains
Produits utilisés : s2_l2a
Mots clés : données utilisées ; sentinelle 2, indice de bande ; MNDWI, indice de bande ; NDCI, analyse ; surveillance des changements, qualité de l’eau
Aperçu
Les plans d’eau intérieurs sont essentiels à la vie humaine, à la fois par l’approvisionnement en eau potable et par le soutien à l’agriculture et à l’aquaculture. Ces plans d’eau peuvent être contaminés par des « polluants urbains » provenant des communautés vivant à proximité, ce qui entraîne des problèmes de santé pour les personnes et les animaux. Si la santé des plans d’eau peut être surveillée depuis le sol grâce à des échantillonnages, l’imagerie satellite peut compléter cette surveillance. Un événement particulier lié à la mauvaise qualité de l’eau est la présence de proliférations d’algues. Plus précisément, les eaux contenant des niveaux élevés de nutriments provenant des engrais, des eaux usées ou du ruissellement urbain peuvent accueillir de grandes proliférations d’algues. Cependant, il doit exister un moyen bien compris et testé de relier les observations par satellite à la présence de proliférations d’algues.
Cas d’utilisation de Sentinel-2
Les proliférations d’algues sont associées à la présence de chlorophylle-a dans les plans d’eau. Mishra et Mishra (2012) <https://doi.org/10.1016/j.rse.2011.10.016> ont développé l’indice de différence normalisée de chlorophylle (NDCI), qui sert d’indicateur qualitatif de la concentration de chlorophylle-a à la surface d’un plan d’eau. L’indice nécessite des informations provenant d’une partie spécifique du spectre infrarouge, connue sous le nom de « bord rouge ». Celle-ci est capturée dans le cadre des 13 bandes spectrales de Sentinel-2, ce qui permet de mesurer le NDCI avec Sentinel-2.
Description
Dans cet exemple, nous mesurons le NDCI pour le lac Bosomtwe, qui est affecté par la pollution comme mentionné dans la section Contexte. Ceci est combiné avec des informations sur la taille du plan d’eau, qui sont utilisées pour créer une visualisation utile de la façon dont le niveau d’eau et la présence de chlorophylle-a évoluent au fil du temps. L’exemple pratique guide les utilisateurs à travers le code requis pour :
Chargez des images Sentinel-2 sans nuage pour une zone d’intérêt.
Calculer des indices pour mesurer la présence d’eau et de chlorophylle-a.
Générer des visualisations informatives pour identifier la présence de chlorophylle-a.
Quelques mises en garde
Le NDCI est actuellement traité comme un indice expérimental pour les capteurs Sentinel-2, car des travaux supplémentaires sont nécessaires pour calibrer et valider dans quelle mesure l’indice est lié à la présence de chlorophylle-a.
Il est également important de se rappeler que les proliférations d’algues entraînent généralement une augmentation des valeurs de l’indice NDCI, mais que toutes les augmentations de l’indice NDCI ne sont pas dues aux proliférations d’algues. Par exemple, il peut y avoir des fluctuations saisonnières dans la quantité de chlorophylle-a dans un plan d’eau.
Des travaux de validation supplémentaires sont nécessaires pour comprendre comment les effets des eaux peu profondes et de l’atmosphère affectent le NDCI et son utilisation pour identifier les concentrations élevées de chlorophylle-a.
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Une fois l’analyse terminée, revenez à la cellule « Paramètres d’analyse », modifiez certaines valeurs (par exemple, choisissez un autre lieu ou une autre période à analyser) et relancez l’analyse. Vous trouverez des instructions supplémentaires sur la modification du bloc-notes à la fin.
Charger des paquets
Chargez les principaux packages Python et les fonctions de support pour l’analyse.
[1]:
%matplotlib inline
import datacube
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import geopandas as gpd
import sys
import xarray as xr
import warnings
warnings.filterwarnings("ignore")
from odc.geo.geom import Geometry
from deafrica_tools.spatial import xr_rasterize
from deafrica_tools.plotting import display_map, rgb
from deafrica_tools.datahandling import load_ard, mostcommon_crs
from deafrica_tools.bandindices import calculate_indices
from deafrica_tools.dask import create_local_dask_cluster
from deafrica_tools.areaofinterest import define_area
Configurer un cluster Dask
Dask peut être utilisé pour mieux gérer l’utilisation de la mémoire et effectuer l’analyse en parallèle. Pour une introduction à l’utilisation de Dask avec Digital Earth Africa, consultez le Dask notebook.
Remarque : nous vous recommandons d’ouvrir la fenêtre de traitement Dask pour afficher les différents calculs en cours d’exécution ; pour ce faire, consultez la section Tableau de bord Dask en Afrique de l’Ouest du Dask notebook.
Pour utiliser Dask, configurez le cluster de calcul local à l’aide de la cellule ci-dessous.
[2]:
create_local_dask_cluster()
Client
Client-dea766b6-3752-11f1-927a-66901f7a1b9b
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34857/status |
Cluster Info
LocalCluster
1b142241
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34857/status | Workers: 1 |
| Total threads: 4 | Total memory: 26.21 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-d865b351-99a5-4fe0-ae00-a308558e90ee
| Comm: tcp://127.0.0.1:36423 | Workers: 0 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34857/status | Total threads: 0 |
| Started: Just now | Total memory: 0 B |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:45477 | Total threads: 4 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34299/status | Memory: 26.21 GiB |
| Nanny: tcp://127.0.0.1:46243 | |
| Local directory: /tmp/dask-scratch-space/worker-pyqa_vbn | |
2026-04-13 16:10:50,087 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0)->('gt-stack-all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0))
new run_spec: Alias(('all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0)->('getitem-gt-stack-all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0))
old dependencies: {('gt-stack-all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0)}
new dependencies: frozenset({('getitem-gt-stack-all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0)})
Se connecter au datacube
Activez la base de données Datacube, qui fournit des fonctionnalités pour le chargement et l’affichage des données d’observation de la Terre stockées.
[3]:
dc = datacube.Datacube(app="Chlorophyll_monitoring")
Paramètres d’analyse
La cellule suivante définit les paramètres qui définissent la zone d’intérêt et la durée de l’analyse. Les paramètres sont
« lat » : la latitude centrale à analyser (par exemple « 6,502 »).
« lon » : la longitude centrale à analyser (par exemple « -1,409 »).
« buffer » : le nombre de degrés carrés à charger autour de la latitude et de la longitude centrales. Pour des temps de chargement raisonnables, définissez cette valeur sur « 0,1 » ou moins.
time: la plage de dates à analyser (par exemple,("2017-08-01", "2019-11-01")). Pour des temps de chargement raisonnables, assurez-vous que la plage s’étend sur moins de 3 ans. Notez que les données Sentinel-2 ne sont disponibles qu’après juillet 2015.
Sélectionnez l’emplacement
Pour définir la zone d’intérêt, deux méthodes sont disponibles :
En spécifiant la latitude, la longitude et la zone tampon. Cette méthode nécessite que vous saisissiez la latitude centrale, la longitude centrale et la valeur de la zone tampon en degrés carrés autour du point central que vous souhaitez analyser. Par exemple, « lat = 10,338 », « lon = -1,055 » et « buffer = 0,1 » sélectionneront une zone avec un rayon de 0,1 degré carré autour du point avec les coordonnées (10,338, -1,055).
Vous pouvez également fournir des valeurs de tampon distinctes pour la latitude et la longitude d’une zone rectangulaire. Par exemple, « lat = 10.338 », « lon = -1.055 » et « lat_buffer = 0.1 » et « lon_buffer = 0.08 » sélectionneront une zone rectangulaire s’étendant sur 0,1 degré au nord et au sud et 0,08 degré à l’est et à l’ouest à partir du point « (10.338, -1.055) ».
Pour des temps de chargement raisonnables, définissez la mémoire tampon sur « 0,1 » ou moins.
By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
Pour utiliser l’une de ces méthodes, vous pouvez décommenter la ligne de code concernée et commenter l’autre. Pour commenter une ligne, ajoutez le symbole "#" avant le code que vous souhaitez commenter. Par défaut, la première option qui définit l’emplacement à l’aide de la latitude, de la longitude et du tampon est utilisée.
Si vous exécutez le bloc-notes pour la première fois, conservez les paramètres par défaut ci-dessous. Cela montrera comment fonctionne l’analyse et fournira des résultats significatifs. L’exemple porte sur le lac Bosomtwe, l’un des plus grands lacs d’Afrique de l’Ouest.
Pour exécuter le bloc-notes pour une zone différente, assurez-vous que les données Sentinel-2 sont disponibles pour la zone choisie à l’aide de DEAfrica Explorer. Utilisez le menu déroulant pour vérifier la couverture de s2_l2a.
[4]:
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=-17.9, lon=30.8, buffer=0.04)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
#aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# Set the range of dates for the analysis
time = ("2018-01-01", "2019-12-31")
Afficher l’emplacement sélectionné
La cellule suivante affichera la zone sélectionnée sur une carte interactive. N’hésitez pas à zoomer et dézoomer pour mieux comprendre la zone que vous allez analyser. En cliquant sur n’importe quel point de la carte, vous découvrirez les coordonnées de latitude et de longitude de ce point.
[5]:
display_map(x=lon_range, y=lat_range)
[5]:
Charger et afficher les données Sentinel-2
La première étape de l’analyse consiste à charger les données Sentinel-2 pour la zone d’intérêt et la plage de temps spécifiées. Cela utilise la fonction utilitaire prédéfinie « load_ard ». Cette fonction masquera automatiquement tous les nuages dans l’ensemble de données et ne renverra que les images où plus de 80 % des pixels ont été classés comme clairs.
Remarque : cette analyse effectue des calculs qui utilisent la surface au sol de chaque pixel. Pour ce type d’analyse, il est recommandé de reprojeter toutes les données sur une projection à surface égale, telle que EPSG:6933. Pour ce faire, définissez le paramètre
output_crssur"EPSG:6933".
Veuillez être patient. Le chargement des données peut prendre quelques minutes et la progression sera indiquée par une sortie texte. Le chargement est terminé lorsque l’état de la cellule passe de « [*] » à « [numéro] ».
[6]:
# Choose the Sentinel-2 products to load
products = ["s2_l2a"]
# Create a reusable query
query = {
"x": lon_range,
"y": lat_range,
"time": time,
"resolution": (-10, 10),
"measurements": ["red_edge_1",
"red",
"green",
"blue",
"nir_1",
"swir_1",]
}
# Since this analysis calculates pixel areas,
# set the output projection to equal area projection EPSG:6933
output_crs = "EPSG:6933"
# Load available data from Sentinel-2A and -2B and filter to retain only times
# with at least 80% good data
ds = load_ard(dc=dc,
products=products,
min_gooddata=0.9,
output_crs=output_crs,
group_by="solar_day",
dask_chunks={'time':1, 'x':2000, 'y':2000},
**query)
Using pixel quality parameters for Sentinel 2
Finding datasets
s2_l2a
Counting good quality pixels for each time step
/opt/venv/lib/python3.12/site-packages/rasterio/warp.py:385: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix will be returned.
dest = _reproject(
Filtering to 76 out of 146 time steps with at least 90.0% good quality pixels
Applying pixel quality/cloud mask
Returning 76 time steps as a dask array
Une fois le chargement terminé, examinez les données en les imprimant dans la cellule suivante. L’argument « Dimensions » révèle le nombre d’intervalles de temps dans l’ensemble de données, ainsi que le nombre de pixels dans les dimensions « x » (longitude) et « y » (latitude).
[7]:
ds
[7]:
<xarray.Dataset> Size: 1GB
Dimensions: (time: 76, y: 973, x: 773)
Coordinates:
* time (time) datetime64[ns] 608B 2018-01-02T08:07:58 ... 2019-12-2...
* y (y) float64 8kB -2.243e+06 -2.243e+06 ... -2.252e+06 -2.252e+06
* x (x) float64 6kB 2.968e+06 2.968e+06 ... 2.976e+06 2.976e+06
spatial_ref int32 4B 6933
Data variables:
red_edge_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
red (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
green (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
blue (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
nir_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
swir_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refDécoupez les ensembles de données selon la forme de la zone d’intérêt
Un géopolygone représente les limites et non la forme réelle, car il est conçu pour représenter l’étendue de l’entité géographique cartographiée, plutôt que sa forme exacte. En d’autres termes, le géopolygone est utilisé pour définir la limite extérieure de la zone d’intérêt, plutôt que les entités et caractéristiques internes.
Il est important de découper les données selon la forme exacte de la zone d’intérêt, car cela permet de garantir que les données utilisées sont pertinentes pour la zone d’étude spécifique. Bien qu’un géopolygone fournisse des informations sur la limite de l’entité géographique représentée, il ne reflète pas nécessairement la forme ou l’étendue exacte de la zone d’intérêt.
[8]:
#Rasterise the area of interest polygon
aoi_raster = xr_rasterize(gdf=geopolygon_gdf, da=ds, crs=ds.crs)
#Mask the dataset to the rasterised area of interest
ds = ds.where(aoi_raster == 1)
Exemple de tracé de pas de temps en vraies couleurs
Pour visualiser les données, utilisez la fonction utilitaire « rgb » préchargée pour tracer une image en vraies couleurs pour un pas de temps donné.
Les paramètres ci-dessous afficheront les images pour deux intervalles de temps, l’un en novembre 2017, l’autre en janvier 2019. Les zones blanches indiquent les endroits où les nuages ou d’autres pixels non valides de l’image ont été masqués. Quelles sont les principales différences entre les deux images ?
N’hésitez pas à expérimenter avec les valeurs des variables « initial_timestep » et « final_timestep » ; réexécutez la cellule pour tracer les images pour les nouveaux pas de temps. Les valeurs des pas de temps peuvent être « 0 » à « n_time - 1 » où « n_time » est le nombre de pas de temps (voir la liste « time » sous la catégorie « Dimensions » dans l’impression du jeu de données ci-dessus).
Remarque : si l’emplacement et l’heure sont modifiés, vous devrez peut-être modifier les paramètres « intial_timestep » et « final_timestep » pour afficher les images à des périodes similaires de l’année.
[9]:
# Set the timesteps to visualise
initial_timestep = 3
final_timestep = 28
# Generate RGB plots at each timestep
rgb(ds, index=[initial_timestep, final_timestep],
percentile_stretch=[0.01, 0.99])

Calculer les indices de bande
Cette étude mesure la présence d’eau via l’indice de différence normalisée de l’eau modifié (MNDWI) et la chlorophylle-a via l’indice de différence normalisée de la chlorophylle (NDCI).
Le MNDWI est calculé à partir des bandes vertes et infrarouges à ondes courtes (SWIR) pour identifier l’eau. La formule est
Lors de l’interprétation de cet indice, les valeurs supérieures à 0 indiquent de l’eau.
Le NDCI est calculé à partir du bord rouge 1 et des bandes rouges pour identifier l’eau. La formule est
Lors de l’interprétation de cet indice, des valeurs élevées indiquent la présence de chlorophylle-a.
Les deux indices sont disponibles via la fonction calculate_indices, importée depuis deafrica_tools.bandindices. Ici, nous utilisons satellite_mission="s2" puisque nous travaillons avec les données Sentinel-2.
[10]:
# Calculate MNDWI and add it to the loaded data set
ds = calculate_indices(ds, index="MNDWI", satellite_mission="s2")
# Calculate NDCI and add it to the loaded data set
ds = calculate_indices(ds, index="NDCI", satellite_mission="s2")
Les valeurs MNDWI et NDCI doivent maintenant apparaître comme variables de données, avec les mesures chargées, dans l’ensemble de données « ds ». Vérifiez cela en imprimant l’ensemble de données ci-dessous :
[11]:
ds
[11]:
<xarray.Dataset> Size: 2GB
Dimensions: (time: 76, y: 973, x: 773)
Coordinates:
* time (time) datetime64[ns] 608B 2018-01-02T08:07:58 ... 2019-12-2...
* y (y) float64 8kB -2.243e+06 -2.243e+06 ... -2.252e+06 -2.252e+06
* x (x) float64 6kB 2.968e+06 2.968e+06 ... 2.976e+06 2.976e+06
spatial_ref int32 4B 6933
Data variables:
red_edge_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
red (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
green (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
blue (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
nir_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
swir_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
MNDWI (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
NDCI (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refCréer un résumé de l’intrigue
Pour comprendre l’évolution de la masse d’eau au fil du temps, la section suivante construit un graphique qui utilise le MNDWI pour mesurer la surface approximative de la masse d’eau, ainsi que le NDCI pour suivre l’évolution de la concentration de chlorophylle-a au fil du temps. Cela pourrait être utilisé pour évaluer rapidement l’état d’une masse d’eau donnée.
Configurer les constantes
Le nombre de pixels classés comme eau (MNDWI > 0) peut être utilisé comme proxy pour la surface du plan d’eau si la surface du pixel est connue. Exécutez la cellule suivante pour générer les constantes nécessaires à la réalisation de cette conversion.
[12]:
# Constants for calculating waterbody area
pixel_length = query["resolution"][1] # in metres
m_per_km = 1000 # conversion from metres to kilometres
area_per_pixel = pixel_length**2 / m_per_km**2
Calculer la surface totale de l’eau
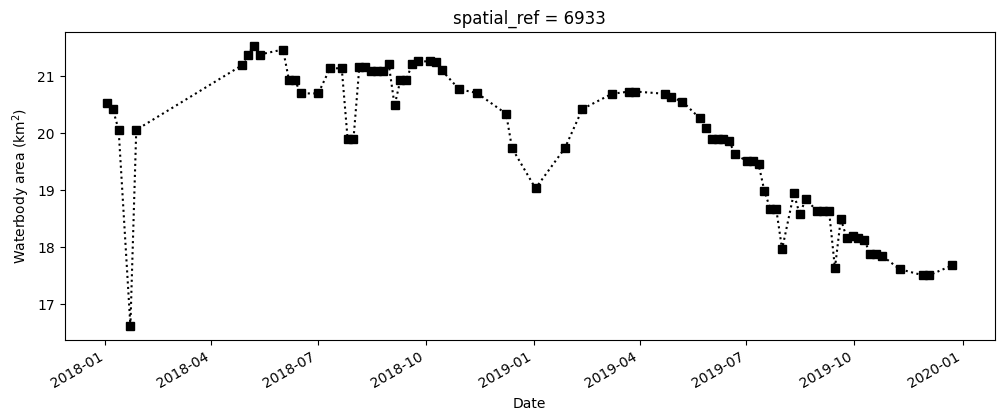
La cellule suivante commence par filtrer l’ensemble de données pour ne conserver que les pixels classés comme eau. Elle calcule ensuite la surface de l’eau en comptant tous les pixels MNDWI dans l’ensemble de données filtré, en calculant une médiane mobile (cela permet de lisser les résultats pour tenir compte des variations dues au masquage des nuages), puis en multipliant ce nombre médian par la surface par pixel.
Remarque : nous vous recommandons d’ouvrir la fenêtre de traitement Dask pour afficher les différents calculs en cours d’exécution ; pour ce faire, consultez la section Tableau de bord Dask en Afrique de l’Ouest du Dask notebook.
[13]:
# Filter the data to contain only pixels classified as water
ds_waterarea = ds.where(ds.MNDWI > 0.0)
# Ensure time chunk is valid for rolling
ds_waterarea = ds_waterarea.chunk({"time": -1}).persist()
# Calculate the total water area (in km^2)
waterarea = (
ds_waterarea.MNDWI.count(dim=["x", "y"])
.rolling(time=3, center=True, min_periods=1)
.median(skipna=True)
* area_per_pixel
).persist()
# Plot the resulting water area through time
fig, axes = plt.subplots(1, 1, figsize=(12, 4))
waterarea.plot(linestyle=":", marker="s", color="k")
axes.set_xlabel("Date")
axes.set_ylabel("Waterbody area (km$^2$)")
plt.show()
Calculer le NDCI moyen
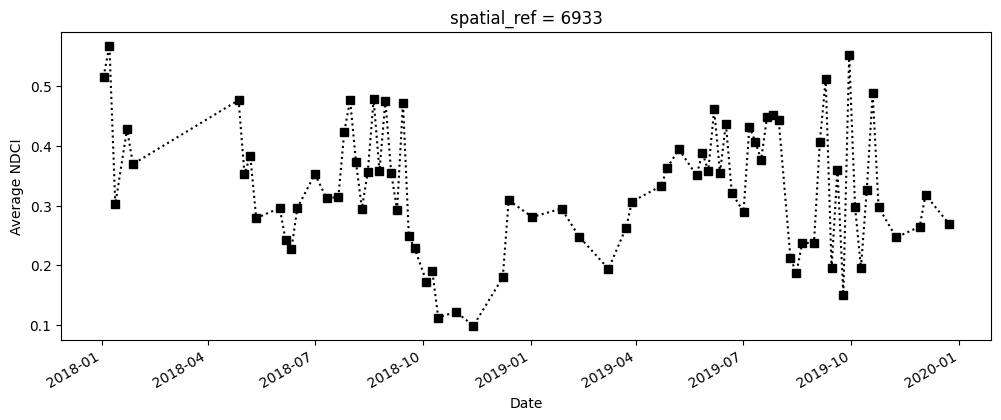
La cellule suivante calcule le NDCI moyen pour chaque pas de temps en utilisant l’ensemble de données filtrées. Cela signifie que nous suivons uniquement le NDCI dans les zones de plans d’eau, et non sur des terres. Pour créer le graphique récapitulatif, nous calculons le NDCI sur tous les pixels ; cela nous permet de suivre les changements globaux du NDCI, mais ne nous indique pas où l’augmentation s’est produite dans le plan d’eau (ce point est abordé dans la section suivante).
Remarque : nous vous recommandons d’ouvrir la fenêtre de traitement Dask pour afficher les différents calculs en cours d’exécution ; pour ce faire, consultez la section Tableau de bord Dask en Afrique de l’Ouest du Dask notebook.
[14]:
# Calculate the average NDCI
average_ndci = ds_waterarea.NDCI.mean(dim=["x", "y"], skipna=True).persist()
# Plot average NDCI through time
fig, axes = plt.subplots(1, 1, figsize=(12, 4))
average_ndci.plot(linestyle=":", marker="s", color="k")
axes.set_xlabel("Date")
axes.set_ylabel("Average NDCI")
plt.show()
Combinez les données pour créer le graphique récapitulatif
La cellule ci-dessous combine la surface totale de l’eau et la série chronologique moyenne NDCI que nous avons générée ci-dessus dans un seul graphique récapitulatif. Notez que Python peut être utilisé pour créer des graphiques hautement personnalisés. Si cela vous intéresse, prenez le temps de comprendre comment le graphique est construit. Sinon, exécutez la cellule pour créer le graphique.
Remarque : la carte de couleurs utilisée ci-dessous est normalisée de sorte que la valeur maximale du NDCI soit de 0,5, ce qui correspondrait à un événement de prolifération d’algues grave (Mishra et Mishra 2012) <https://doi.org/10.1016/j.rse.2011.10.016>. La valeur minimale du NDCI de -0,1 correspond à de faibles concentrations de chlorophylle-a. Cela permet d’identifier plus facilement les événements de prolifération d’algues graves dans le graphique.
[15]:
# Set up the figure
fig, axes = plt.subplots(1, 1, figsize=(12, 4))
# Set the colour map to use and the normalisation. NDCI is plotted on a scale
# of -0.1 to 0.5 so the colour map is normalised to these values
min_ndci_scale = -0.1
max_ndci_scale = 0.5
cmap = plt.get_cmap("cividis")
normal = plt.Normalize(vmin=min_ndci_scale, vmax=max_ndci_scale)
# Store the dates from the data set as numbers for ease of plotting
dates = matplotlib.dates.date2num(ds_waterarea.time.values)
# Add the basic plot to the figure
# This is just a line showing the area of the waterbody over time
axes.plot_date(x=dates, y=waterarea, color="black", linestyle="-", marker="")
# Fill in the plot by looping over the possible threshold values and filling
# the areas that are greater than the threshold
color_vals = np.linspace(0, 1, 100)
threshold_vals = np.linspace(min_ndci_scale, max_ndci_scale, 100)
for ii, thresh in enumerate(threshold_vals):
im = axes.fill_between(dates,
0,
waterarea,
where=(average_ndci >= thresh),
norm=normal,
facecolor=cmap(color_vals[ii]),
alpha=1)
# Add the colour bar to the plot
cax, _ = matplotlib.colorbar.make_axes(axes)
cb2 = matplotlib.colorbar.ColorbarBase(cax, cmap=cmap, norm=normal)
cb2.set_label("NDCI")
# Add titles and labels to the plot
axes.set_xlabel("Date")
axes.set_ylabel("Waterbody area (km$^2$)")
plt.show()
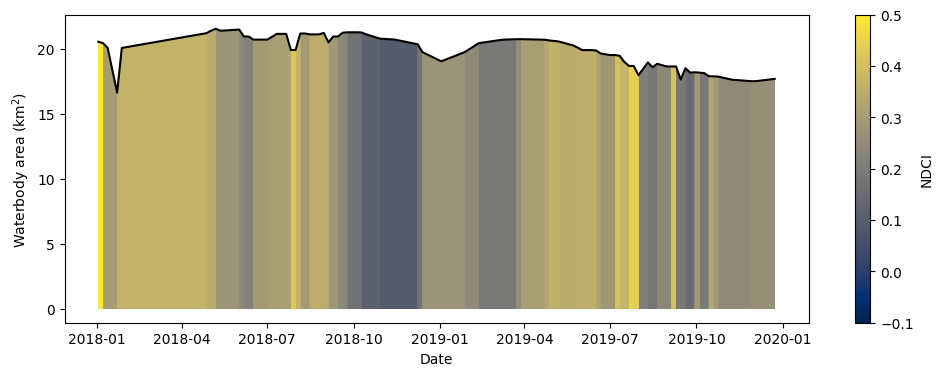
Que révèle le graphique sur le plan d’eau ? Y a-t-il des périodes où les valeurs NDCI sont élevées ?
Comparer le NDCI spatial à deux dates différentes
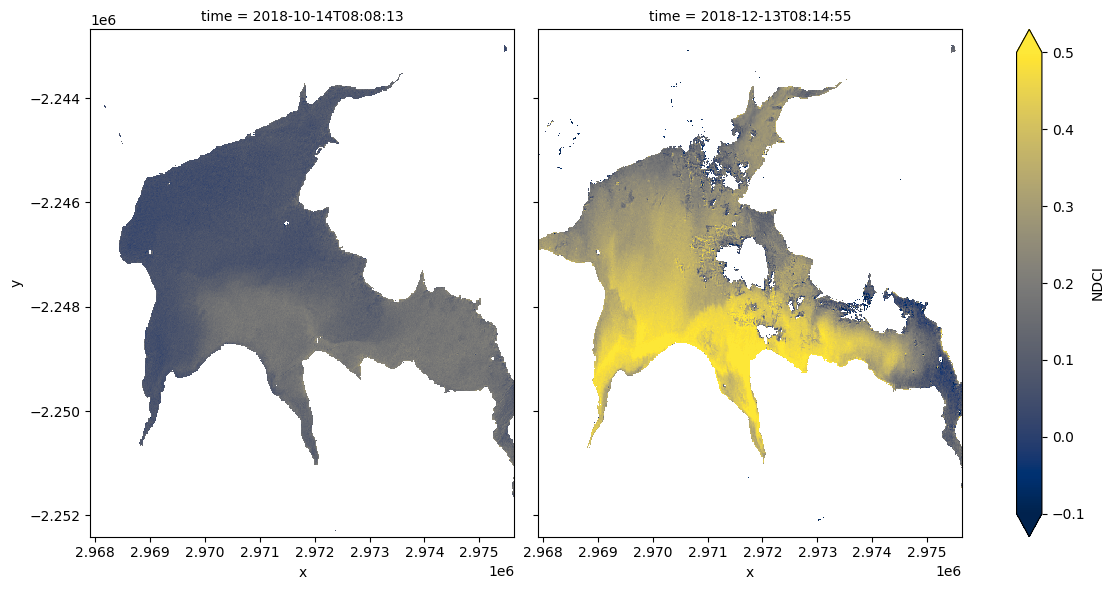
Bien que le graphique récapitulatif soit utile en un coup d’œil, il peut être intéressant d’avoir une vue d’ensemble de l’image spatiale dans les moments où le NDCI est faible ou élevé. Le code ci-dessous définit deux fonctions utiles : « closest_date » recherchera la date dans une liste de dates la plus proche d’une date donnée ; « date_index » renverra la position d’une date particulière dans une liste de dates. Ces fonctions sont utiles pour sélectionner des images à comparer.
[16]:
def closest_date(list_of_dates, desired_date):
return min(list_of_dates,
key=lambda x: abs(x - np.datetime64(desired_date)))
def date_index(list_of_dates, known_date):
return (np.where(list_of_dates == known_date)[0][0])
Exécutez la cellule ci-dessous pour définir deux dates à comparer. N’hésitez pas à modifier les dates pour consulter le NDCI du plan d’eau à des moments différents.
[17]:
# Set the dates to view
date_1 = "2018-10-15"
date_2 = "2018-12-15"
# Compute the closest date available from the data set
closest_date_1 = closest_date(ds.time.values, date_1)
closest_date_2 = closest_date(ds.time.values, date_2)
# Make an xarray containing the closest dates, which is used to select
# the dates from the data set
time_xr = xr.DataArray([closest_date_1, closest_date_2], dims=["time"])
# Plot the NDCI values for pixels classified as water for the two dates.
ds_waterarea.NDCI.sel(time=time_xr).plot.imshow(x="x",
y="y",
col="time",
cmap=cmap,
vmin=min_ndci_scale,
vmax=max_ndci_scale,
col_wrap=2,
robust=True,
figsize=(12, 6))
plt.show()
Exécutez la cellule ci-dessous pour voir les images en vraies couleurs pour les mêmes dates
[18]:
# Compute the index of the closest dates
closest_date_1_idx = date_index(ds.time.values, closest_date_1)
closest_date_2_idx = date_index(ds.time.values, closest_date_2)
# Make the true colour plots for the closest dates
rgb(ds, index=[closest_date_1_idx, closest_date_2_idx],
percentile_stretch=[0.02, 0.95])
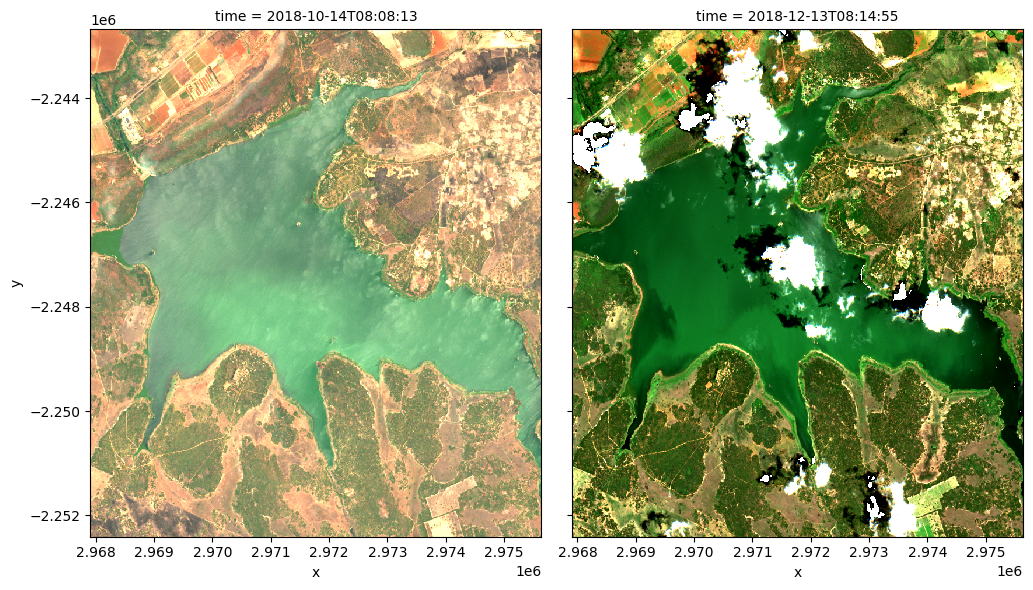
Tirer des conclusions
Voici quelques questions sur lesquelles réfléchir :
Dans quelle mesure les valeurs NDCI augmentées correspondent-elles à ce que vous voyez sur les images en vraies couleurs ?
Quand serait-il plus utile d’utiliser le graphique récapitulatif par rapport au graphique de comparaison temporelle et vice-versa ?
À quoi ressemble l’eau sur l’image en vraies couleurs lorsque le NDCI est faible à moyen ou élevé ?
Quelles autres informations pourriez-vous rechercher si vous détectiez une valeur NDCI anormalement élevée ?
Prochaines étapes
Une fois terminé, revenez à la section « Paramètres d’analyse », modifiez certaines valeurs (par exemple « lat », « lon » ou « heure ») et relancez l’analyse. Vous pouvez utiliser la carte interactive dans la section « Afficher l’emplacement sélectionné » pour trouver de nouvelles valeurs de latitude et de longitude centrales en effectuant un panoramique et un zoom, puis en cliquant sur la zone pour laquelle vous souhaitez extraire les valeurs de localisation. Vous pouvez également utiliser Google Maps pour rechercher un emplacement que vous connaissez, puis renvoyer les valeurs de latitude et de longitude en cliquant sur la carte.
Si vous souhaitez modifier l’emplacement, vous devez vous assurer que les données Sentinel-2 sont disponibles pour le nouvel emplacement, ce que vous pouvez vérifier sur le site DEAfrica Explorer <https://explorer.digitalearth.africa>. Utilisez le menu déroulant pour vérifier la couverture de s2a_l2a.
Si vous souhaitez observer le réservoir de Weija, essayez les coordonnées suivantes sur la même période que l’exemple d’origine :
lat = 5.577
lon = -0.362
Informations Complémentaires
Licence Le code de ce notebook est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>`__.
Les données de Digital Earth Africa sont sous licence Creative Commons Attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack DE Africa <https://digitalearthafrica.slack.com/> ou sur le GIS Stack Exchange <https://gis.stackexchange.com/questions/ask?tags=open-data-cube> en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment `ici <https://gis.stackexchange.com/questions/tagged/open-data-
Si vous souhaitez signaler un problème avec ce notebook, vous pouvez en déposer un sur Github.
Version de Datacube compatible
[19]:
print(datacube.__version__)
1.9.13
Dernier test :
[20]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[20]:
'2026-04-13'