Monitoring Mangrove Extents
Keywords: data used; sentinel-2, data used; external, mangroves, band index; NDVI
Background
Global Mangrove Watch (GMW) is an initiative to track global mangrove extents. Using ALOS PALSAR and Landsat (optical) data to form a baseline extent of mangroves for the years 1996, 2007, 2008, 2009, 2010, 2015, and 2016 . More detailed information on the initiative can be found here. This dataset has been rasterized and indexed into DE Africa’s Open Data Cube, for more information on how to load this dataset check out the GMW Datasets notebook.
Description
The goal of this notebook is to monitor the changing extent of mangroves, using the GMW layers as a baseline mask.
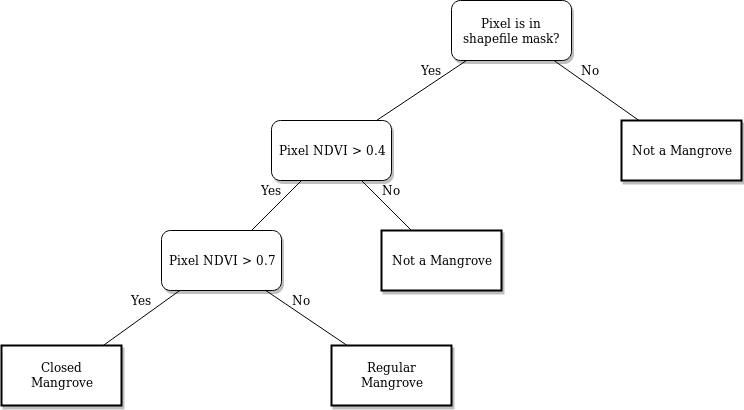
The process begins with retrieving Sentnel-2 data for a specific area in a time series. This dataset is then compressed into a median composite for each year. From the composite, we then calculate the NDVI values of each pixel in each year. The dataset is then masked, and the NDVI threshold is applied for mangrove classification. The following image shows the decision tree for the classification.
After classification, we can perform a variety of analyses on the data:
We can estimate the change in mangrove areas by counting all the classified pixels for each year and plotting the trend line of the count.
We can also visualize the mangrove areas by plotting each classified pixel a certain color.
Getting started
To run this analysis, run all the cells in the notebook, starting with the Load packages cell.
After finishing the analysis, return to the Analysis parameters cell, modify some values (e.g. choose a your own mangrove shapefile or time period to analyse) and re-run the analysis.
Load packages
[1]:
%matplotlib inline
import warnings
import datacube
import numpy as np
import pandas as pd
import xarray as xr
import geopandas as gpd
import matplotlib.pyplot as plt
from datacube.utils import geometry
from matplotlib.patches import Patch
from matplotlib.colors import ListedColormap
from deafrica_tools.bandindices import calculate_indices
from deafrica_tools.dask import create_local_dask_cluster
from deafrica_tools.datahandling import load_ard
from deafrica_tools.plotting import display_map
from odc.geo.geom import Geometry
from deafrica_tools.spatial import xr_rasterize
from deafrica_tools.areaofinterest import define_area
from eo_tides.eo import tag_tides
Set up a Dask cluster
Dask can be used to better manage memory use down and conduct the analysis in parallel. For an introduction to using Dask with Digital Earth Africa, see the Dask notebook.
Note: We recommend opening the Dask processing window to view the different computations that are being executed; to do this, see the Dask dashboard in DE Africa section of the Dask notebook.
To use Dask, set up the local computing cluster using the cell below.
[2]:
create_local_dask_cluster()
Client
Client-0cac734d-c464-11f0-88b1-22be2d1047ac
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/37905/status |
Cluster Info
LocalCluster
ef26f679
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/37905/status | Workers: 1 |
| Total threads: 4 | Total memory: 26.21 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-fb8c210e-bfc7-4345-b685-c845c0f7e6aa
| Comm: tcp://127.0.0.1:34577 | Workers: 1 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/37905/status | Total threads: 4 |
| Started: Just now | Total memory: 26.21 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:37267 | Total threads: 4 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/45861/status | Memory: 26.21 GiB |
| Nanny: tcp://127.0.0.1:39507 | |
| Local directory: /tmp/dask-scratch-space/worker-s36gr1se | |
Load the data
Connect to the datacube database and set up a processing cluster.
[3]:
dc = datacube.Datacube(app="Mangrove")
Analysis parameters
lat, lon, buffer: center lat/lon and analysis window size for the area of interestproduct_name: The name of the satellite product to use.time_range: The date range to analyse (e.g.("2017", "2020")).tide_range: The minimum and maximum proportion of the tidal range to include in the analysis. For example,tide_range = (0.25, 0.75)will select all satellite images taken during mid-tide conditions (i.e. 25th to 75th percentile range). This allows us to remove any impact of tides on the classification of mangrove extent. Also, because Sentinel-2 is a sun-synchronoous sensor, the mid-tide is observed more than low and high tides, therefore it is advantageous to use the mid-tide extent as we will retain more satellite images.
Select location
To define the area of interest, there are two methods available:
By specifying the latitude, longitude, and buffer. This method requires you to input the central latitude, central longitude, and the buffer value in square degrees around the center point you want to analyze. For example,
lat = 10.338,lon = -1.055, andbuffer = 0.1will select an area with a radius of 0.1 square degrees around the point with coordinates (10.338, -1.055).Alternatively, you can provide separate buffer values for latitude and longitude for a rectangular area. For example,
lat = 10.338,lon = -1.055, andlat_buffer = 0.1andlon_buffer = 0.08will select a rectangular area extending 0.1 degrees north and south, and 0.08 degrees east and west from the point(10.338, -1.055).For reasonable loading times, set the buffer as
0.1or lower.By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
To use one of these methods, you can uncomment the relevant line of code and comment out the other one. To comment out a line, add the "#" symbol before the code you want to comment out. By default, the first option which defines the location using latitude, longitude, and buffer is being used.
If running the notebook for the first time, keep the default settings below. This will demonstrate how the analysis works and provide meaningful results.
[4]:
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=11.88, lon=-15.8558, buffer=0.15)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
#aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
product_name = "s2_l2a"
time_range = ("2017", "2021")
tide_range = (0.25, 0.75) # only keep mid tides
View the selected location
The next cell will display the selected area on an interactive map. Feel free to zoom in and out to get a better understanding of the area you’ll be analysing. Clicking on any point of the map will reveal the latitude and longitude coordinates of that point.
[5]:
display_map(lon_range, lat_range)
[5]:
Load cloud-masked Sentinel-2 data
The code below uses the load_ard function to load in data from the Sentinel-2 satellites for the area and time specified. For more information, see the Using load_ard notebook. The function will also automatically mask out clouds from the dataset, allowing us to focus on pixels that contain useful data:
[6]:
# create a query dict for the datacube
query = {
"time": time_range,
'x': lon_range,
'y': lat_range,
"group_by": "solar_day",
"resolution": (-20, 20),
"output_crs":"EPSG:6933",
}
# load data
ds = load_ard(
dc=dc,
products=[product_name],
measurements=["red", "nir_2"], #use nir-narrow for NDVI
mask_filters=[("opening", 5), ("dilation", 5)],
dask_chunks={"time": 1, "x": 1000, "y": 1000},
**query,
)
print(ds)
Using pixel quality parameters for Sentinel 2
Finding datasets
s2_l2a
Applying morphological filters to pq mask [('opening', 5), ('dilation', 5)]
Applying pixel quality/cloud mask
Returning 344 time steps as a dask array
<xarray.Dataset> Size: 7GB
Dimensions: (time: 344, y: 1875, x: 1449)
Coordinates:
* time (time) datetime64[ns] 3kB 2017-01-05T11:27:37 ... 2021-12-30...
* y (y) float64 15kB 1.524e+06 1.524e+06 ... 1.486e+06 1.486e+06
* x (x) float64 12kB -1.544e+06 -1.544e+06 ... -1.515e+06
spatial_ref int32 4B 6933
Data variables:
red (time, y, x) float32 4GB dask.array<chunksize=(1, 1000, 1000), meta=np.ndarray>
nir_2 (time, y, x) float32 4GB dask.array<chunksize=(1, 1000, 1000), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
/opt/venv/lib/python3.12/site-packages/deafrica_tools/datahandling.py:565: FutureWarning: In a future version of xarray the default value for compat will change from compat='no_conflicts' to compat='override'. This is likely to lead to different results when combining overlapping variables with the same name. To opt in to new defaults and get rid of these warnings now use `set_options(use_new_combine_kwarg_defaults=True) or set compat explicitly.
ds = xr.merge([ds_data, ds_masks])
Clip the datasets to the shape of the area of interest
A geopolygon represents the bounds and not the actual shape because it is designed to represent the extent of the geographic feature being mapped, rather than the exact shape. In other words, the geopolygon is used to define the outer boundary of the area of interest, rather than the internal features and characteristics.
Clipping the data to the exact shape of the area of interest is important because it helps ensure that the data being used is relevant to the specific study area of interest. While a geopolygon provides information about the boundary of the geographic feature being represented, it does not necessarily reflect the exact shape or extent of the area of interest.
[7]:
#Rasterise the area of interest polygon
aoi_raster = xr_rasterize(gdf=geopolygon_gdf, da=ds, crs=ds.crs)
#Mask the dataset to the rasterised area of interest
ds = ds.where(aoi_raster == 1)
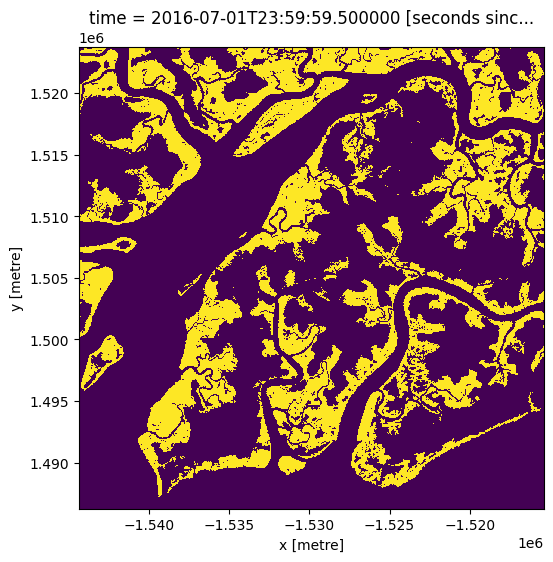
Load in the Global Mangrove Watch
Below we load the latest GMW layer, which is from 2016
[8]:
gmw = dc.load(product='gmw',
time='2016',
like=ds.geobox)
[9]:
gmw.mangrove.plot(figsize=(6,6), add_colorbar=False);
Model tide heights
The location of the shoreline can vary greatly from low to high tide, which may impact the NDVI values of pixels where water and mangroves intermingle. In the code below, we aim to reduce the effect of tides by modelling tide height data, and keeping only the satellite images that were taken at specific tidal conditions. For example, if tide_range = (0.00, 0.50), we are telling the analysis to focus only on satellite images taken when the tide was between the lowest tidal conditions and the
median (50th percentile) conditions.
We can pass our satellite dataset ds to the tag_tides function from the eo-tides Python package to model a tide for each timestep in our dataset. This can help sort and filter images by tide height, allowing us to learn more about how coastal environments respond to the effect of changing tides. The tag_tides function uses the time and date of acquisition and the geographic centroid of each satellite observation as inputs for the selected tide model (EOT20 by default). It returns an
xarray.DataArray called tide_height, with a modelled tide for every timestep in our satellite dataset.
Important note: this function can only model tides correctly if the centre of your study area is located over water. If this isn’t the case, you can specify a custom tide modelling location by passing a coordinate to
tidepost_latandtidepost_lon(e.g. tidepost_lat=14.283, tidepost_lon=-16.921). If you are not running the default analysis, then either change thetidepost_latandtidepost_lonbelow to a location over the ocean near your study-area, or try setting them toNoneand see if the code can infer the location of your study-area
[10]:
tidepost_lat=11.7443
tidepost_lon=-15.9949
[11]:
# Model tides
tides_da = tag_tides(
ds,
directory="/var/share/tide_models",
tidepost_lat=tidepost_lat,
tidepost_lon=tidepost_lon,
)
# We can easily combine these modelled tides with our original satellite data for further analysis.
# The code below adds our modelled tides as a new tide_height variable under Data variables.
ds["tide_height"] = tides_da
# Print the output dataset with new `tide_height` variable
print(ds)
Using tide modelling location: -15.99, 11.74
Modelling tides with EOT20
<xarray.Dataset> Size: 7GB
Dimensions: (time: 344, y: 1875, x: 1449)
Coordinates:
* time (time) datetime64[ns] 3kB 2017-01-05T11:27:37 ... 2021-12-30...
* y (y) float64 15kB 1.524e+06 1.524e+06 ... 1.486e+06 1.486e+06
* x (x) float64 12kB -1.544e+06 -1.544e+06 ... -1.515e+06
spatial_ref int32 4B 6933
tide_model <U5 20B 'EOT20'
Data variables:
red (time, y, x) float32 4GB dask.array<chunksize=(1, 1000, 1000), meta=np.ndarray>
nir_2 (time, y, x) float32 4GB dask.array<chunksize=(1, 1000, 1000), meta=np.ndarray>
tide_height (time) float32 1kB -0.9229 1.316 0.3223 ... -0.1774 -0.7789
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
[12]:
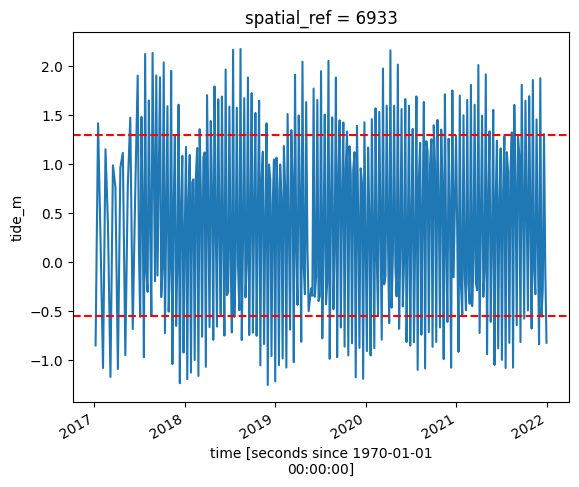
# Calculate the min and max tide heights to include based on the % range
min_tide, max_tide = ds.tide_height.quantile(tide_range)
# Plot the resulting tide heights for each Landsat image:
ds.tide_height.plot()
plt.axhline(min_tide, c="red", linestyle="--")
plt.axhline(max_tide, c="red", linestyle="--")
plt.show()
Filter satellite images by tide height
Here we take the dataset and only keep the images with tide heights we want to analyse (i.e. tides within the heights given by tide_range). This will result in a smaller number of images.
[13]:
# Keep timesteps larger than the min tide, and smaller than the max tide
ds_filtered = ds.sel(time=(ds.tide_height > min_tide) & (ds.tide_height <= max_tide))
print(ds_filtered)
<xarray.Dataset> Size: 4GB
Dimensions: (time: 172, y: 1875, x: 1449)
Coordinates:
* time (time) datetime64[ns] 1kB 2017-01-25T11:33:57 ... 2021-12-25...
* y (y) float64 15kB 1.524e+06 1.524e+06 ... 1.486e+06 1.486e+06
* x (x) float64 12kB -1.544e+06 -1.544e+06 ... -1.515e+06
spatial_ref int32 4B 6933
tide_model <U5 20B 'EOT20'
Data variables:
red (time, y, x) float32 2GB dask.array<chunksize=(1, 1000, 1000), meta=np.ndarray>
nir_2 (time, y, x) float32 2GB dask.array<chunksize=(1, 1000, 1000), meta=np.ndarray>
tide_height (time) float32 688B 0.3223 1.063 0.472 ... -0.1634 -0.1774
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
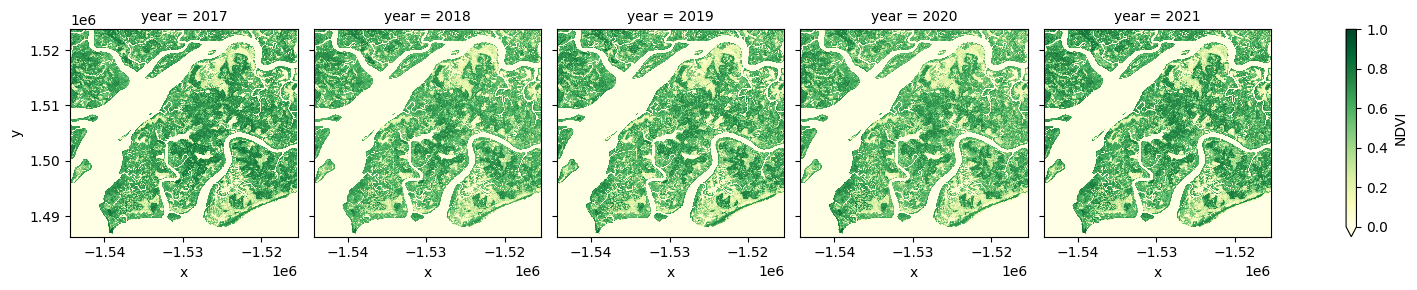
Combine observations into noise-free summary images
In the code below, we take the time series of images and combine them into single images for each year using the median NDVI. The Normalised Difference Vegetation Index (NDVI) shows vegetation and is used for mangrove classification within the mangrove mask.
For more information on indices, see the Calculating Band Indices notebook.
Note: This step can take several minutes to load if the study area is large. We recommend opening the Dask processing window to view the different computations that are being executed; to do this, see the Dask dashboard in DE Africa section of the Dask notebook.
[14]:
#calculate NDVI, rename nir2 to trick calculate_indices
ds_filtered = ds_filtered.rename({'nir_2':'nir'})
ds_filtered = calculate_indices(ds_filtered, index='NDVI', satellite_mission='s2')
[15]:
# generate median annual summaries of NDVI
ds_summaries = ds_filtered.NDVI.groupby("time.year").median().compute()
# Plot the output summary images
ds_summaries.plot(col="year", cmap="YlGn", col_wrap=len(ds_summaries.year.values), vmin=0, vmax=1.0);
/opt/venv/lib/python3.12/site-packages/rasterio/warp.py:387: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix will be returned.
dest = _reproject(
Mangrove classification
Apply a mask of the mangrove area
We will use the mangrove mask from the Global Mangrove Watch dataset so we can work with only the pixels in the mangrove area.
[16]:
# Mask dataset to set pixels outside the GMW layer to `NaN`
ds_summaries_masked = ds_summaries.where(gmw.mangrove.squeeze())
Calculating regular and closed mangroves
Using the mangrove decision tree above, we can classify the pixels as:
mangroves: pixels in the mangrove area with an
NDVI > 0.4regular mangroves: mangroves with
NDVI <= 0.7closed mangroves: mangroves with
NDVI > 0.7
[17]:
all_mangroves = xr.where(ds_summaries_masked > 0.4, 1, np.nan)
regular_mangroves = all_mangroves.where(ds_summaries_masked <= 0.7)
closed_mangroves = all_mangroves.where(ds_summaries_masked > 0.7)
Plot the mangrove types
Again we will combine the mangrove types for easier plotting.
[18]:
mangroves = xr.concat(
[regular_mangroves, closed_mangroves, all_mangroves],
dim=pd.Index(["regular", "closed", "total"], name="mangrove_type"),
)
regular_color = "gold"
closed_color = "green"
# Create a FacetGrid, so there is a subplot for each year
grid = xr.plot.FacetGrid(
mangroves,
col="year",
col_wrap=len(ds_summaries.year.values),
size=6,
aspect=mangroves.x.size / mangroves.y.size,
)
# Define the sub-plot of mangrove types with a legend on a background of grey-scale NDVI
def plot_mangrove(data, ax, **kwargs):
ds_summaries.sel(year=data.year).plot.imshow(
ax=ax, cmap="Greys", vmin=-1, vmax=1, add_colorbar=False, add_labels=False
)
data.sel(mangrove_type="regular").plot.imshow(
ax=ax,
cmap=ListedColormap([regular_color]),
add_colorbar=False,
add_labels=False,
)
data.sel(mangrove_type="closed").plot.imshow(
ax=ax, cmap=ListedColormap([closed_color]), add_colorbar=False, add_labels=False
)
ax.legend(
[Patch(facecolor=regular_color), Patch(facecolor=closed_color)],
["Regular", "Closed"],
loc="lower right",
)
# Plot the each year sub-plot
grid.map_dataarray(plot_mangrove, x="x", y="y", add_colorbar=False)
# Update sub-plot titles
for i, name in np.ndenumerate(grid.name_dicts):
grid.axes[i].title.set_text(str(name["year"]));
/tmp/ipykernel_2225/2631477952.py:44: DeprecationWarning: self.axes is deprecated since 2022.11 in order to align with matplotlibs plt.subplots, use self.axs instead.
grid.axes[i].title.set_text(str(name["year"]));

Mangrove change
Plot the change of mangrove classification in area over time
[19]:
# Convert pixel count to km^2
m2_per_ha = 10000
m2_per_pixel = query["resolution"][1] ** 2
mangrove_area = mangroves.sum(dim=("x", "y")) * m2_per_pixel / m2_per_ha
# Fix axis and legend text
mangrove_area.name = r"Area (Ha)"
mangrove_area = mangrove_area.rename(mangrove_type="Mangrove type")
# Plot the line graph
mangrove_area.plot(
hue="Mangrove type",
x="year",
xticks=mangrove_area.year,
size=6,
linestyle="--",
marker="o",
)
plt.title("Mangrove classification over time");
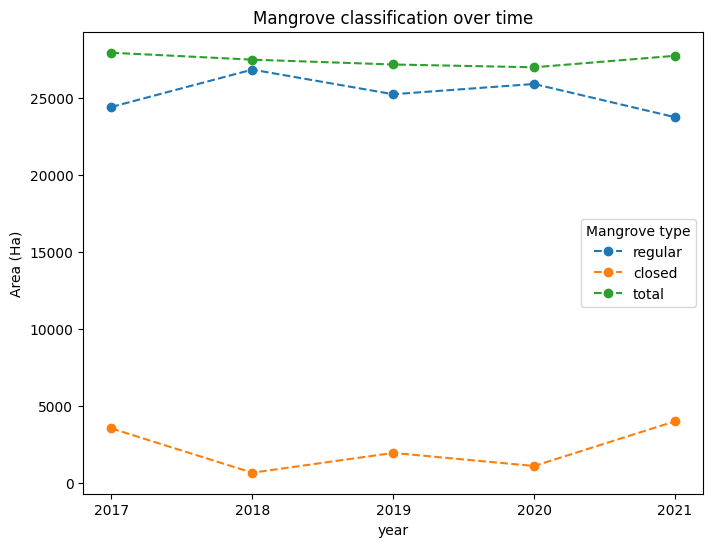
Monitoring change in mangroves
We can calculate the growth and loss of mangroves between the first and last year in our timeseries
[20]:
total_mangroves = (mangroves.loc["total"] == 1).astype(int)
# Calculate the change in mangrove extent
old = total_mangroves.isel(year=0)
new = total_mangroves.isel(year=-1)
change = new - old
# reclassify into growth, loss and stable
growth = xr.where(change == 1, 1, np.nan)
loss = xr.where(change == -1, -1, np.nan)
stable = old.where(~change)
stable = xr.where(stable == 1, 1, np.nan)
Plot the change
[21]:
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ds_summaries.isel(year=0).plot.imshow(
ax=ax, cmap="Greys", vmin=-1, vmax=1, add_colorbar=False, add_labels=False
)
stable.plot(
ax=ax, cmap=ListedColormap(["palegoldenrod"]), add_colorbar=False, add_labels=False
)
growth.squeeze().plot.imshow(
ax=ax, cmap=ListedColormap(["lime"]), add_colorbar=False, add_labels=False
)
loss.plot.imshow(
ax=ax, cmap=ListedColormap(["fuchsia"]), add_colorbar=False, add_labels=False
)
ax.legend(
[
Patch(facecolor='lime'),
Patch(facecolor='fuchsia'),
Patch(facecolor="palegoldenrod"),
],
["New mangroves", "Loss of mangroves", "Stable mangroves"],
loc="lower right",
)
plt.title('Change in mangrove extent between {} and {}'.format(ds_summaries.year.values[0], ds_summaries.year.values[-1]));
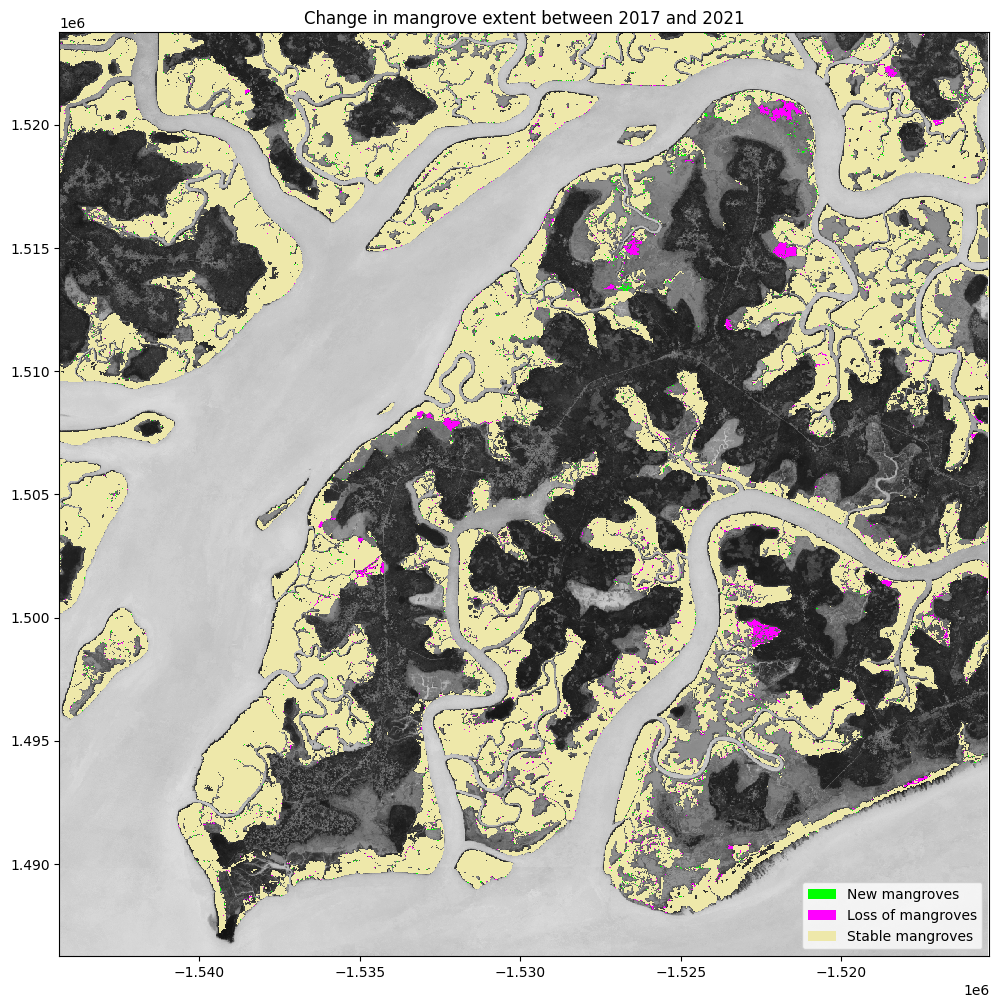
Determine the net change between years
[22]:
loss_count = loss.sum().values * m2_per_pixel / m2_per_ha
gain_count = growth.sum().values * m2_per_pixel / m2_per_ha
stable_count = stable.sum().values* m2_per_pixel / m2_per_ha
counts = {
'Loss of Mangroves': loss_count,
'New Mangroves': gain_count,
'No Change': stable_count,
'Delta Change': gain_count + loss_count
}
df = pd.DataFrame(counts, index=['Area (Ha)'])
df.plot.barh(color=['tab:red','tab:green','tab:orange','tab:blue'])
plt.title('Change in mangrove extent between {} and {}'.format(ds_summaries.year.values[0], ds_summaries.year.values[-1]));
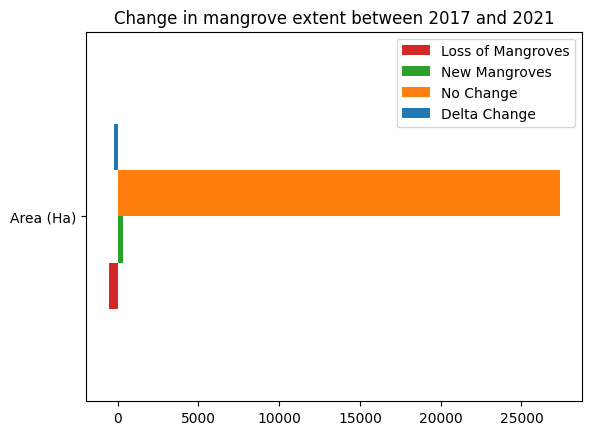
Advanced: Compare Recent Mangrove Extent to GMW 1996
In the previous plots, we were calculating the change in mangrove extent from the start of the Sentinel-2 time series (2017) until now (2021). However, the baseline mangrove extent map, the Global Mangrove Watch (GMW) layer goes all the way back to 1996. Thus, the mangrove extent may have change significantly between 1996 and the beginning of the Sentinel-2 archive. We can use the GMW layer to inspect how mangrove extent has changed since the development of the 2016 product that we examined above.
A word of caution here, the GMW product was developed using a different methodology to the one used here, so differences in mangrove extent may be attributable to the different methods. Nevertheless, this should still provide us with a reasonable indication of the changes that have occurred between 1996 and the beginning of the Sentinel-2 archive in 2017.
Load the earliest GMW layer
[23]:
gmw_1996 = dc.load(product='gmw',
time='1996',
like=ds.geobox)
Determine change between 1996 and 2017
[24]:
#Find the change between now and the baseline
baseline_change = old - gmw_1996.mangrove.squeeze()
# reclassify into growth, loss and stable
growth_bs = xr.where(baseline_change == 1, 1, np.nan)
loss_bs = xr.where(baseline_change == -1, -1, np.nan)
stable_bs = gmw_1996.mangrove.squeeze().where(~baseline_change)
stable_bs = xr.where(stable == 1, 1, np.nan)
Plot the change
[25]:
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ds_summaries.isel(year=0).plot.imshow(
ax=ax, cmap="Greys", vmin=-1, vmax=1, add_colorbar=False, add_labels=False
)
stable_bs.plot(
ax=ax, cmap=ListedColormap(["palegoldenrod"]), add_colorbar=False, add_labels=False
)
growth_bs.plot.imshow(
ax=ax, cmap=ListedColormap(["lime"]), add_colorbar=False, add_labels=False
)
loss_bs.plot.imshow(
ax=ax, cmap=ListedColormap(["fuchsia"]), add_colorbar=False, add_labels=False
)
ax.legend(
[
Patch(facecolor='lime'),
Patch(facecolor='fuchsia'),
Patch(facecolor="palegoldenrod"),
],
["New mangroves", "Loss of mangroves", "Stable Mangroves"],
loc="lower right",
)
plt.title('Change in mangrove extent between GMV 1996 baseline and {}'.format(ds_summaries.year.values[0]));
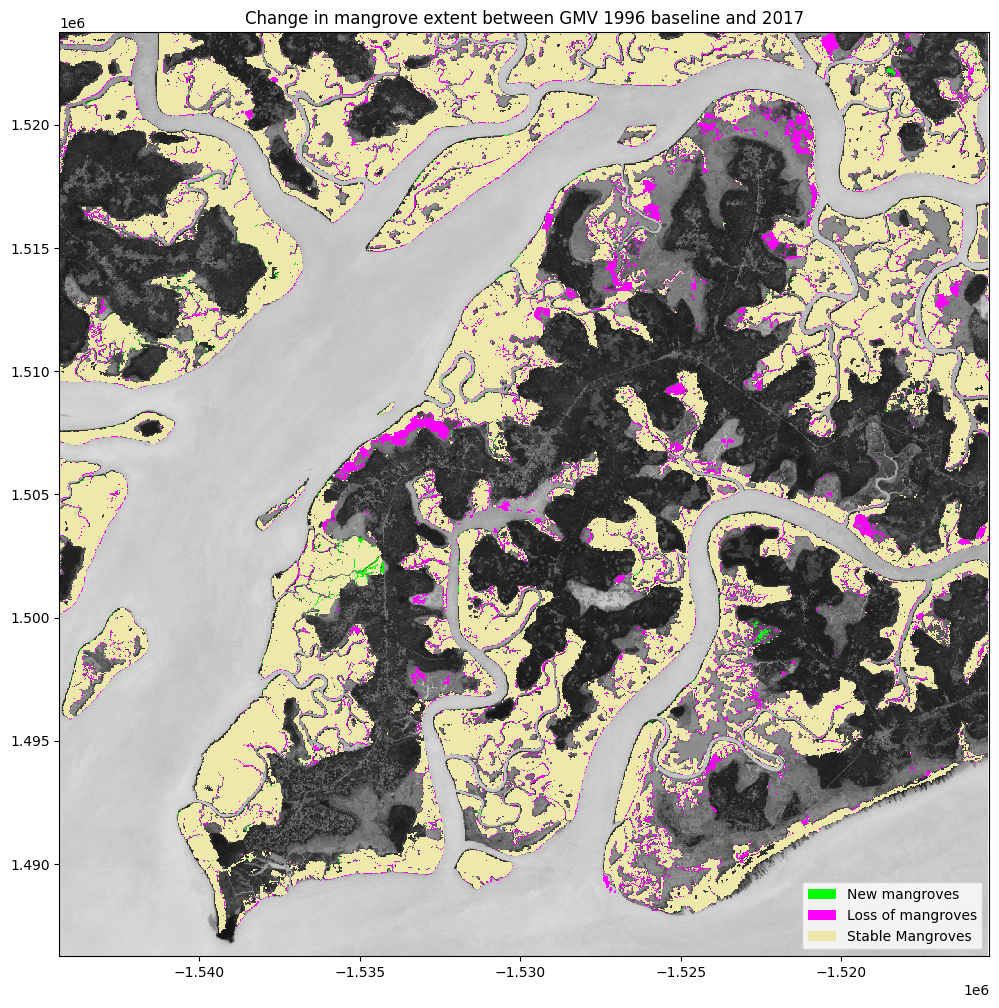
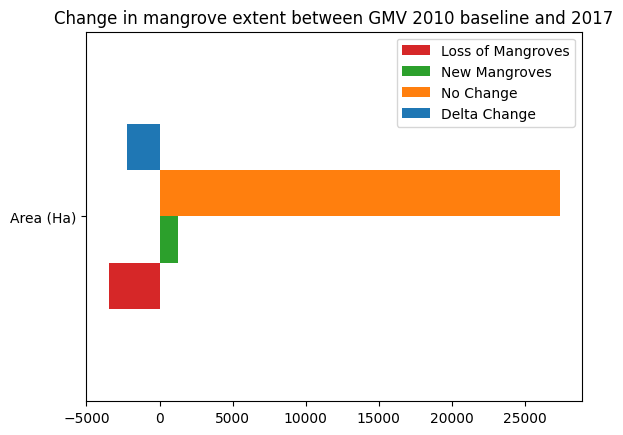
Determine the net change between 1996 and 2017
[26]:
loss_bs_count = loss_bs.sum().values * m2_per_pixel / m2_per_ha
gain_bs_count = growth_bs.sum().values * m2_per_pixel / m2_per_ha
stable_bs_count = stable_bs.sum().values* m2_per_pixel / m2_per_ha
counts = {
'Loss of Mangroves': loss_bs_count,
'New Mangroves': gain_bs_count,
'No Change': stable_bs_count,
'Delta Change': gain_bs_count + loss_bs_count
}
df = pd.DataFrame(counts, index=['Area (Ha)'])
df.plot.barh(color=['tab:red','tab:green','tab:orange','tab:blue'])
plt.title('Change in mangrove extent between GMV 2010 baseline and {}'.format(ds_summaries.year.values[0]));
Drawing conclusions
Here are some questions to think about:
What are the causes of mangrove growth and loss?
Additional information
License The code in this notebook is licensed under the Apache License, Version 2.0.
Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact If you need assistance, please post a question on the DE Africa Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here).
If you would like to report an issue with this notebook, you can file one on Github.
Compatible datacube version
[27]:
print(datacube.__version__)
1.8.20
Last Tested:
[28]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[28]:
'2025-11-18'