Cube in a Box (CiaB)
Why use the Cube in a Box?
The Cube in a Box and the Digital Earth Africa Analysis Sandbox are both deployments of the Open Data Cube.
The Digital Earth Africa Analysis Sandbox is a cloud deployment of the Open Data Cube. This environment is externally hosted and managed by Digital Earth Africa and consists of :
An Amazon Web Service instance of cloud computing
A JupyterLab platform for conducting analysis
Direct access to an Open Data Cube instance containing all of Digital Earth Africa’s earth observation data.
Pre-loaded Jupyter notebooks demonstrating how to use the Open Data Cube to conduct earth observation analysis
The Sandbox is the simplest way to getting started with the Open Data Cube. It provides a limited, but free compute resource to explore Digital Earth Africa’s earth observation data and analysis tools for ad-hoc report generation and rapid development of new algorithms. Being an externally managed environment, the Sandbox only allows access to products indexed by Digital Earth Africa into the Open Data Cube instance.
If you are looking to install the Open Data Cube on your own resources, whether locally or on a cloud service such as Amazon Web Services (AWS) then the Cube in a Box is a great option. The Cube in a Box (CIAB) is a distributable, ready to run reference install of an independent Open Data Cube. It allows you to create your own Open Data Cube environment, similar to the Sandbox. This Open Data Cube instance is specifically maintained and customized by the user. You can index Digital Earth Africa earth observation data and index (add) your own data, be it commercial, in-situ, or derived products into your self managed Open Data Cube instance.
Getting started with Cube in a Box
Installing the Cube in a Box requires you to have Docker and Docker-Compose installed. To install the Digital Earth Africa’s Cube in a Box, clone the the Github repository digitalearthafrica/cube-in-a-box and follow the detailed install instructions.
You can deploy the Cube in a Box to AWS using this magic link. You need to be logged in to the AWS Console to deploy using this URL. Once logged in, click the link, and follow the prompts including settings a bounding box region of interest, EC2 instance type and password for Jupyter.
There is a notebook provided in the Cube in a Box Github repository that shows how to index more data into the Cube in a Box.
Technical information
The Open Data Cube is a collection of software that is designed to:
Catalogue large amounts of Earth Observation data
Provide a Python based API for high performance querying and data access
Give scientists and other users easy ability to perform Exploratory Data Analysis
Allow scalable continent scale processing of the stored data
Track the provenance of all the contained data to allow for quality control and updates
The Open Data Cube is composed of the following:
Data: The data can be stored on a file system, either in local directories of GeoTIFFs or NetCDF files, or stored on an object store like AWS’ S3 as Cloud Optimised GeoTIFFs.
An index: This is a PostgreSQL database that contains an index pointing to where the actual data is stored. The index enables a user to ask for data at a time and location, without needing to know specifically where the required files are stored and how to access them.
Software : The Open Data Cube python library is the core of the ODC. Other Software include Jupyter Notebooks built on the ODC python library which one can use to explore the data indexed.
Figure 1: Technical Components of the Open Data Cube
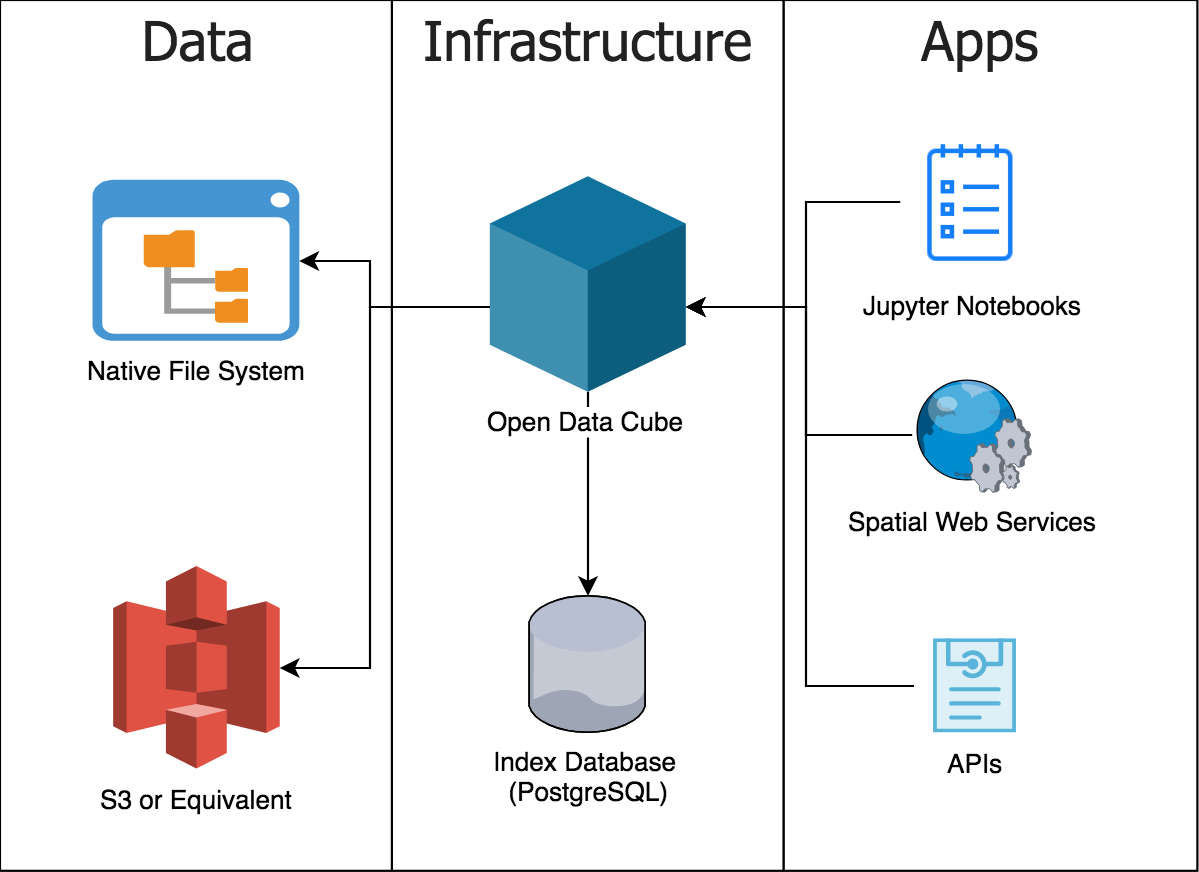
Image from the What is the Open Data Cube? by Alex Leith.
The ODC can be deployed on various computing platforms. Possible deployments include:
Local deployment (e.g., high-end workstation)
Cloud (e.g., Amazon Web Services)
High Performance Computing infrastructure (e.g., NCI)