Vegetation Change Detection
Products used: ls8_sr
Keywords: data used; landsat 8, analysis; change detection, band index; NDVI, band index; EVI, forestry
Background
Detecting regions of deforestation and afforestation in satellite imagery is complicated by the need to distinguish real land use changes from the natural changes introduced by climate variability. To determine regions that have undergone significant change, we can apply hypothesis testing techniques to stacks of remotely sensed satellite images to determine where change is statistically significant relative to the natural, background variability.
Description
In this example, we measure the presence of vegetation from Landsat imagery and apply a hypothesis test to identify areas of significant change (along with the direction of the change).
The worked example takes users through the code required to do the following:
Load cloud-free Landsat 8 images for an area of interest (AOI).
Calculate indices that indicate vegetation, such as the normalised difference vegetation index (NDVI) and enhanced vegetation index (EVI).
Apply a statistical hypothesis test to find areas of significant change.
Visualise the statistically significant areas.
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
After finishing the analysis, return to the “Analysis parameters” cell, modify some values (e.g. choose a different location or time period to analyse) and re-run the analysis. There are additional instructions on modifying the notebook at the end.
Load packages
Load key Python packages and any supporting functions for the analysis.
[1]:
import datacube
import datacube.utils.rio
import matplotlib.pyplot as plt
import numpy as np
import geopandas as gpd
from scipy import stats
import xarray as xr
from odc.geo.xr import write_cog
from deafrica_tools.datahandling import mostcommon_crs, load_ard
from deafrica_tools.bandindices import calculate_indices
from deafrica_tools.plotting import display_map, rgb
from deafrica_tools.spatial import xr_rasterize
from odc.geo.geom import Geometry
from deafrica_tools.areaofinterest import define_area
#This will speed up loading data
datacube.utils.rio.set_default_rio_config(aws='auto', cloud_defaults=True)
Connect to the datacube
Activate the datacube database, which provides functionality for loading and displaying stored Earth observation data.
[2]:
dc = datacube.Datacube(app="Change_detection")
Analysis parameters
The following cell sets the parameters, which define the area of interest and the length of time to conduct the analysis over. There is also a parameter to define how the data is split in time; the split yields two non-overlapping samples, which is a requirement of the hypothesis test we want to run (more detail below). The parameters are:
latitude: The latitude at the centre of your AOI (e.g.0.02).longitude: The longitude at the centre of your AOI (e.g.35.425).buffer: The number of degrees to load around the central latitude and longitude. For reasonable loading times, set this as0.1or lower.time: The date range to analyse (e.g.('2015-01-01', '2019-09-01')). For reasonable results, the range should span at least two years to prevent detecting seasonal changes.time_baseline: The date at which to split the total sample into two non-overlapping samples (e.g.'2015-12-01'). For reasonable results, pick a date that is about halfway between the start and end dates specified intime.
To define the area of interest, there are two methods available:
By specifying the latitude, longitude, and buffer. This method requires you to input the central latitude, central longitude, and the buffer value in square degrees around the center point you want to analyze. For example,
lat = 10.338,lon = -1.055, andbuffer = 0.1will select an area with a radius of 0.1 square degrees around the point with coordinates (10.338, -1.055).Alternatively, you can provide separate buffer values for latitude and longitude for a rectangular area. For example,
lat = 10.338,lon = -1.055, andlat_buffer = 0.1andlon_buffer = 0.08will select a rectangular area extending 0.1 degrees north and south, and 0.08 degrees east and west from the point(10.338, -1.055).For reasonable loading times, set the buffer as
0.1or lower.By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
To use one of these methods, you can uncomment the relevant line of code and comment out the other one. To comment out a line, add the "#" symbol before the code you want to comment out. By default, the first option which defines the location using latitude, longitude, and buffer is being used.
If running the notebook for the first time, keep the default settings below. This will demonstrate how the analysis works and provide meaningful results. The example covers part of the Northern Tindiret Forest Reserve, Kenya.
[3]:
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=0.02, lon=35.425, buffer=0.1)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
# aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# Set the range of dates for the complete sample
time = ('2013-01-01', '2018-12-01')
# Set the date to separate the data into two samples for comparison
time_baseline = '2015-12-01'
View the selected location
The next cell will display the selected area on an interactive map. The red border represents the area of interest of the study. Zoom in and out to get a better understanding of the area of interest. Clicking anywhere on the map will reveal the latitude and longitude coordinates of the clicked point.
[4]:
display_map(x=lon_range, y=lat_range)
[4]:
Load and view Landsat data
The first step in the analysis is to load Landsat data for the specified area of interest and time range.
The code below will create a query dictionary for our region of interest, find the correct crs object for the area of interest, and then load the Landsat data using the load_ard function. For more infmation, see the Using load_ard notebook. The function will also automatically mask out clouds from the dataset, allowing us to focus on pixels that contain useful data. It will also exclude images where more than 70% of the pixels are
masked, which is set using the min_gooddata parameter in the load_ard call.
[5]:
#Create a query object
query = {
'x': lon_range,
'y': lat_range,
'time': time,
'measurements': ['red',
'green',
'blue',
'nir'],
'resolution': (-30, 30),
'group_by': 'solar_day'
}
# find the right crs for the location
crs = mostcommon_crs(dc=dc, product='ls8_sr', query=query)
# load cloud-masked fractional cover using load_ard
ds = load_ard(dc=dc,
**query,
products=['ls8_sr'],
align=(15, 15),
output_crs=crs,
min_gooddata=0.7
)
Using pixel quality parameters for USGS Collection 2
Finding datasets
ls8_sr
Counting good quality pixels for each time step
Filtering to 52 out of 128 time steps with at least 70.0% good quality pixels
Applying pixel quality/cloud mask
Re-scaling Landsat C2 data
Loading 52 time steps
Once the load is complete, examine the data by printing it in the next cell. The Dimensions argument revels the number of time steps in the data set, as well as the number of pixels in the x (longitude) and y (latitude) dimensions.
[6]:
print(ds)
<xarray.Dataset> Size: 457MB
Dimensions: (time: 52, y: 739, x: 743)
Coordinates:
* time (time) datetime64[ns] 416B 2013-04-28T07:50:43.620475 ... 20...
* y (y) float64 6kB 1.329e+04 1.326e+04 ... -8.82e+03 -8.85e+03
* x (x) float64 6kB 7.588e+05 7.588e+05 ... 7.81e+05 7.81e+05
spatial_ref int32 4B 32636
Data variables:
red (time, y, x) float32 114MB 0.06073 0.06235 0.05 ... nan nan nan
green (time, y, x) float32 114MB 0.0791 0.07838 0.06353 ... nan nan
blue (time, y, x) float32 114MB 0.03295 0.03474 0.02775 ... nan nan
nir (time, y, x) float32 114MB 0.3758 0.3708 0.2985 ... nan nan nan
Attributes:
crs: epsg:32636
grid_mapping: spatial_ref
Clip the datasets to the shape of the area of interest
A geopolygon represents the bounds and not the actual shape because it is designed to represent the extent of the geographic feature being mapped, rather than the exact shape. In other words, the geopolygon is used to define the outer boundary of the area of interest, rather than the internal features and characteristics.
Clipping the data to the exact shape of the area of interest is important because it helps ensure that the data being used is relevant to the specific study area of interest. While a geopolygon provides information about the boundary of the geographic feature being represented, it does not necessarily reflect the exact shape or extent of the area of interest.
[7]:
#Rasterise the area of interest polygon
aoi_raster = xr_rasterize(gdf=geopolygon_gdf, da=ds, crs=ds.crs)
#Mask the dataset to the rasterised area of interest
ds = ds.where(aoi_raster == 1)
Plot example timesteps in true colour
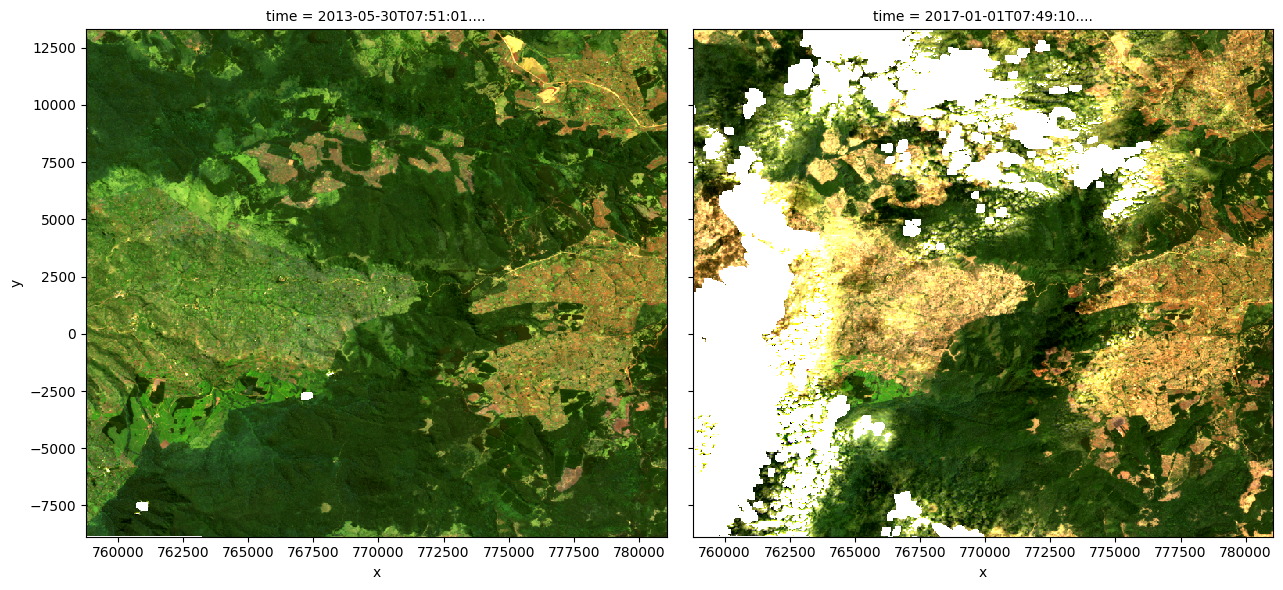
Feel free to experiment with the values for the initial_timestep and final_timestep variables; re-run the cell to plot the images for the new timesteps. The values for the timesteps can be 0 to one fewer than the number of time steps loaded in the data set. The number of time steps is the same as the total number of observations listed as the output of the cell used to load the data.
[8]:
# Set the timesteps to visualise
initial_timestep = 2
final_timestep = 37
rgb(ds, index=[initial_timestep, final_timestep])
Compute band indices
For this study, there are two indices that can be used as proxies for vegetation.
The first is the normalised difference vegetation index (NDVI). This index uses the ratio of the red and near-infrared (NIR) bands to identify live green vegetation. The formula is:
The second is the enhanced vegetation index (EVI). This index uses the red, near-infrared (NIR) and blue bands to identify vegetation; it is particularly sensitive to high biomass regions. The formula is:
When interpreting these indices, high values indicate vegetation.
Using an index in this notebook
The cell below calculates the chosen index, adds it to the dataset, then creates a new object ds_index that only contains the calculated index, allowing it to be used throughout the rest of the notebook.
To use NDVI, run the following code in the cell below:
ds = calculate_indices(ds, 'NDVI', satellite_mission='ls')
ds_index = ds.NDVI
To use EVI, run the following code in the cell below:
ds = calculate_indices(ds, 'EVI', satellite_mission='ls')
ds_index = ds.EVI
[9]:
# Calculate NDVI and add it to the loaded dataset
ds = calculate_indices(ds, 'NDVI', satellite_mission='ls')
ds_index = ds.NDVI
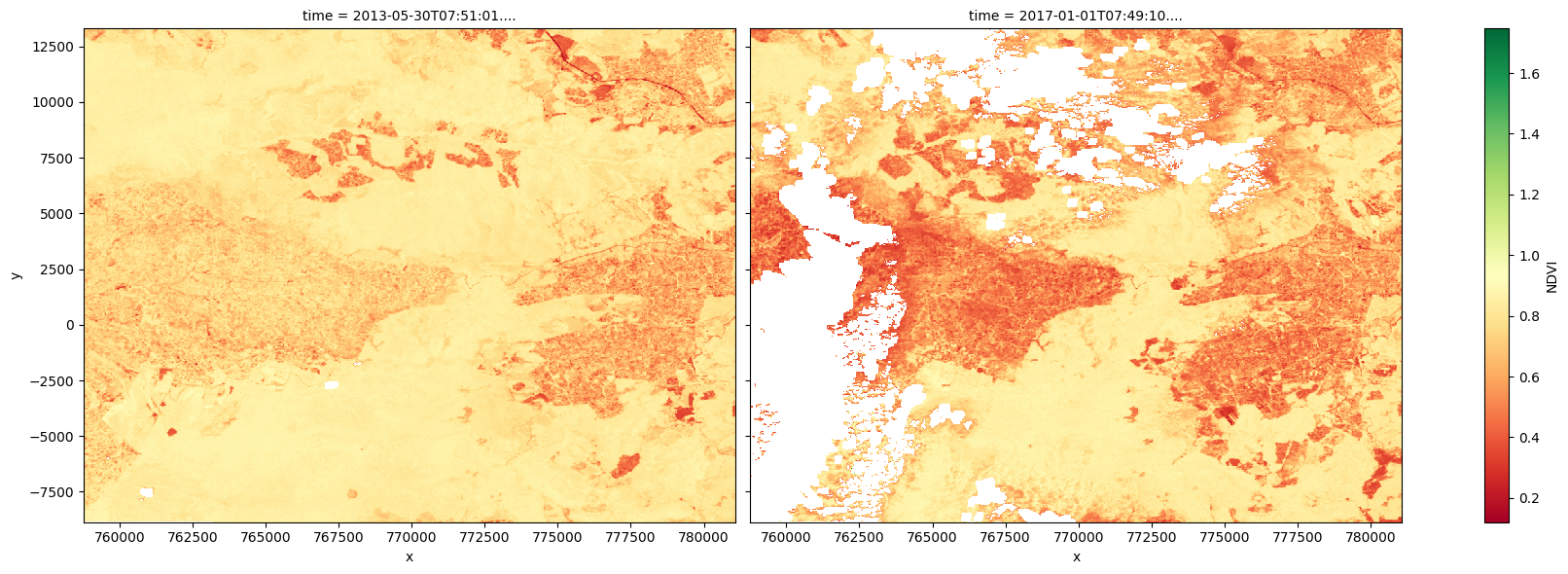
Visualising the index
The plots below show the chosen index values for the two selected timesteps used to make the true-colour images above. Use the plots to visually confirm whether the chosen index is a suitable for change detection.
[10]:
# Plot the NDVI values for pixels classified as vegetation for the two dates.
ds_index.isel(time=[initial_timestep, final_timestep]).plot.imshow(
x='x', y='y', col='time', cmap='RdYlGn', figsize=(18, 6)
)
plt.show()
Perform hypothesis test
While it is possible to visually detect change between the two timesteps, it is important to consider how to rigorously check for both positive change in vegetation (afforestation) and negative change in vegetation (deforestation).
This can be done through hypothesis testing. In this case,
The hypothesis test will indicate where there is evidence for rejecting the null hypothesis. From this, we may identify areas of signficant change, according to a given significance level (covered in more detail below).
Make samples
To perform the test, the total sample will be split in two: a baseline sample and a postbaseline sample, which respectively contain the data before and after the time_baseline date. Then, we can test for a difference in the average vegetation index (either NDVI or EVI) between the samples for each pixel in the sample. In this step, we also make mean composites for both samples, which will be useful later on for visualising the comparison.
The samples are made by filtering the index based on whether it was observed before or after the time_baseline date. The number of observations in each sample will be printed. If one sample is much larger than the other, consider changing the time_baseline parameter in the “Analysis parameters” cell, and then re-run this cell. Coordinates are recorded for later use.
[11]:
# Make samples
baseline_sample = ds_index.sel(time=ds['time'] <= np.datetime64(time_baseline))
baseline_composite = ds.sel(time=ds['time'] <= np.datetime64(time_baseline)).mean(dim=['time'])
print(f"Number of observations in baseline sample: {len(baseline_sample.time)}")
postbaseline_sample = ds_index.sel(time=ds['time'] > np.datetime64(time_baseline))
postbaseline_composite = ds.sel(time=ds['time'] > np.datetime64(time_baseline)).mean(dim=['time'])
print(f"Number of observations in postbaseline sample: {len(postbaseline_sample.time)}")
# Record coodrinates for reconstructing xarray objects
sample_lat_coords = ds.coords['y']
sample_lon_coords = ds.coords['x']
Number of observations in baseline sample: 27
Number of observations in postbaseline sample: 25
Test for change
To look for evidence that the average index value has changed between the two samples (either positively or negatively), we use Welch’s t-test. This is used to test the hypothesis that two populations have equal averages. In this case, the populations are the area of interest before and after the time_baseline date, and the average being tested is the average index value. Welch’s t-test is used (as opposed to Student’s t-test) because the two samples in the study may not necessarily have
equal variances.
The test is run using the Scipy package’s statistcs library, which provides the ttest_ind function for running t-tests. Setting equal_var=False means that the function will run Welch’s t-test. The function returns the t-statistic and p-value for each pixel after testing the difference in the average index value. These are stored as t_stat and p_val inside the t_test dataset for use in the next section.
[12]:
# Perform the t-test on the postbaseline and baseline samples
tstat, p_tstat = stats.ttest_ind(
postbaseline_sample.values,
baseline_sample.values,
equal_var=False,
nan_policy='omit',
)
# Convert results to an xarray for further analysis
t_test = xr.Dataset(
{'t_stat': (['y', 'x'], tstat),
'p_val': (['y', 'x'], p_tstat)},
coords={
'x': (['x'], sample_lon_coords.values),
'y': (['y'], sample_lat_coords.values)
}, attrs={'crs': ds.geobox.crs})
print(t_test)
/tmp/ipykernel_11028/952593560.py:2: SmallSampleWarning: After omitting NaNs, one or more axis-slices of one or more sample arguments is too small; corresponding elements of returned arrays will be NaN. See documentation for sample size requirements.
tstat, p_tstat = stats.ttest_ind(
<xarray.Dataset> Size: 4MB
Dimensions: (y: 739, x: 743)
Coordinates:
* x (x) float64 6kB 7.588e+05 7.588e+05 7.588e+05 ... 7.81e+05 7.81e+05
* y (y) float64 6kB 1.329e+04 1.326e+04 ... -8.82e+03 -8.85e+03
Data variables:
t_stat (y, x) float32 2MB nan nan nan nan ... -4.45 -4.818 -3.797 -5.055
p_val (y, x) float32 2MB nan nan nan ... 2.203e-05 0.0005809 9.102e-06
Attributes:
crs: PROJCS["WGS 84 / UTM zone 36N",GEOGCS["WGS 84",DATUM["WGS_1984"...
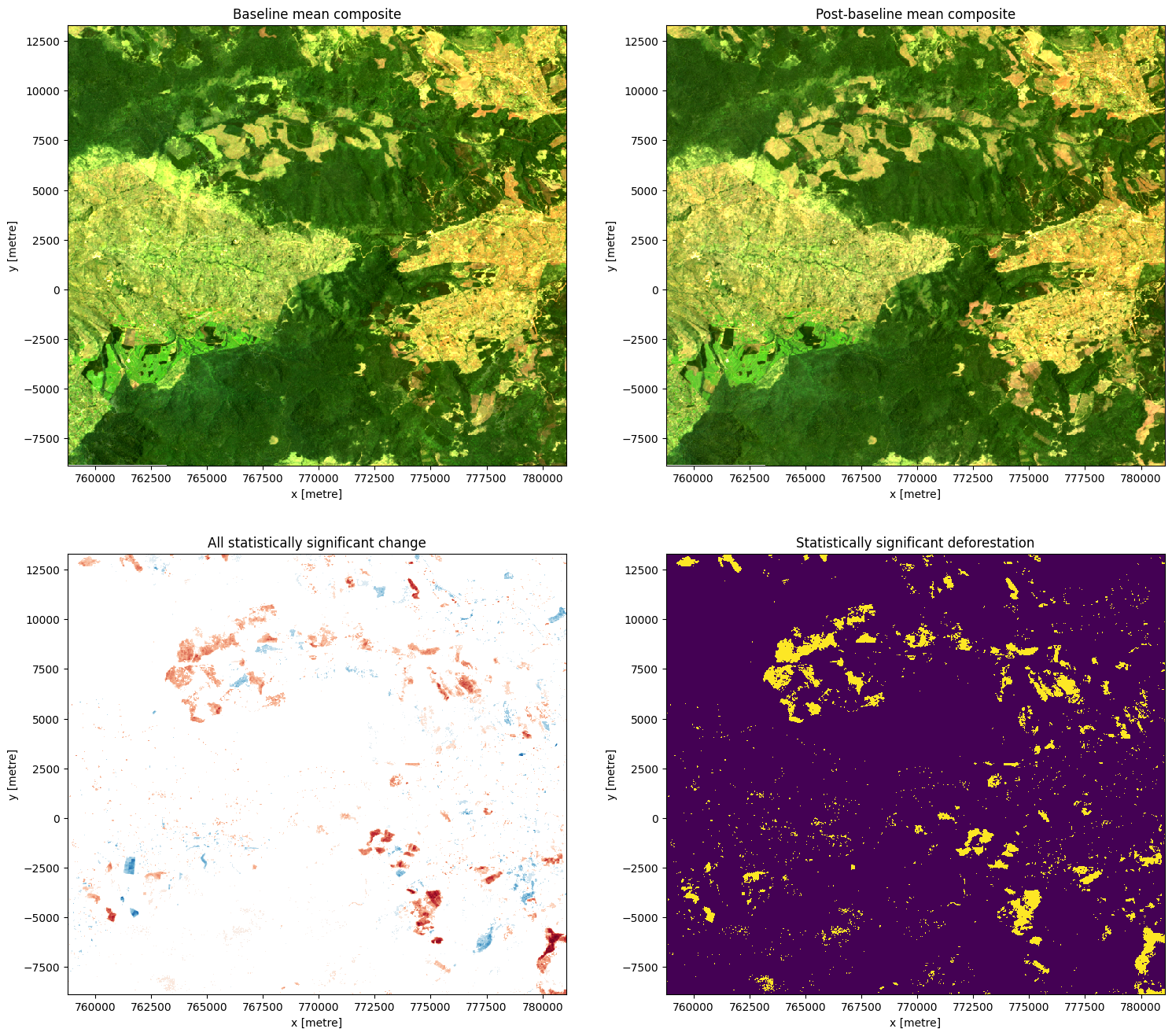
Visualise change
From the test, we’re interested in two conditions: whether the change is significant (rejection of the null hypothesis) and whether the change was positive (afforestation) or negative (deforestation).
The null hypothesis can be rejected if the \(p\)-value (p_val) is less than the chosen significance level, which is set as sig_level = 0.01 for this analysis. If the null hypothesis is rejected, the pixel will be classified as having undergone significant change.
The direction of the change can be inferred from the difference in the average index of each sample, which is calculated as \(\text{diff mean} = \text{mean(post baseline)} - \text{mean(baseline)}.\)
This means that
if the average index value for a given pixel is higher in the
post baselinesample compared to thebaselinesample, thendiff_meanfor that pixel will be positive.if the average index value for a given pixel is lower in the
post baselinesample compared to thebaselinesample, thendiff_meanfor that pixel will be negative.
Run the cell below to plot the baseline and post-baseline composites, the differences that were marked as signficant, and the mask showing areas of significant deforestation.
Note: For the plot showing areas of significant difference between the samples, positive change is shown in blue and negative change is shown in red.
[13]:
# Set the significance level
sig_level = 0.01
# Identify any difference in the mean
diff_mean = postbaseline_sample.mean(
dim=['time']) - baseline_sample.mean(dim=['time'])
diff_mean.name = f"{baseline_sample.name} Difference"
# Identify any difference in the mean classified as significant
sig_diff_mean = postbaseline_sample.mean(dim=['time']).where(
t_test.p_val < sig_level) - baseline_sample.mean(dim=['time']).where(t_test.p_val < sig_level)
sig_diff_mean.name = f"{baseline_sample.name} Difference"
# Determine areas with significant deforestation (negative difference)
sig_deforestation = sig_diff_mean < 0
sig_deforestation.name = "Deforestation"
# Determine areas with significant afforestations (positive difference)
sig_afforestation = sig_diff_mean > 0
sig_afforestation.name = "Afforestation"
[14]:
# Construct the comparison plot
fig, ax = plt.subplots(2, 2, figsize=(18, 16))
baseline_composite[['red', 'green', 'blue']].to_array().plot.imshow(ax=ax[0,0], robust=True)
postbaseline_composite[['red', 'green', 'blue']].to_array().plot.imshow(ax=ax[0,1], robust=True)
sig_diff_mean.plot(cmap='RdBu', ax=ax[1,0], add_colorbar=False)
sig_deforestation.plot(ax=ax[1,1], add_colorbar=False)
ax[0,0].set_title('Baseline mean composite')
ax[0,1].set_title('Post-baseline mean composite')
ax[1,0].set_title('All statistically significant change')
ax[1,1].set_title('Statistically significant deforestation')
plt.show()
Calculate percentage change
In addition to producing visualisations of the change, we can also estimate the number and proportion of pixels that have undergone statistically significant change.
[15]:
total_pixels = postbaseline_sample.mean(dim=['time']).count(dim=['x', 'y']).values
total_sig_change = sig_diff_mean.count(dim=['x', 'y']).values
total_deforestation = sig_deforestation.where(sig_deforestation==True).count(dim=['x', 'y']).values
percentage_sig_change = (total_sig_change/total_pixels)*100
percentage_deforestation = (total_deforestation/total_pixels)*100
print(f"{percentage_sig_change:.2f}% of pixels that likely underwent significant change in any direction")
print(f"{percentage_deforestation:.2f}% of pixels that likely underwent deforestation")
7.43% of pixels that likely underwent significant change in any direction
5.64% of pixels that likely underwent deforestation
Drawing conclusions
Here are some questions to think about:
What has happened in the forest over the time covered by the dataset?
Were there any statistically significant changes that the test found that you didn’t see in the true-colour images?
What kind of activities/events might explain the significant changes?
What kind of activities/events might explain non-significant changes?
What other information might you need to draw conclusions about the cause of the statistically significant changes?
Export the data
To explore the data further in a desktop GIS program, the data can be output as a GeoTiff. This requires data to be converted to an xarray and tagged with the appropriate coordinate reference system (crs). The diff_mean product will be saved as “ttest_diff_mean.tif”, and the sig_diff_mean product will be saved as “ttest_sig_diff_mean.tif”. These files can be downloaded from the file explorer to the left of this window (see these
instructions).
Note: If you wish to save outputs for more than one index, make sure you change the filenames below after re-running the analysis with a different index.
[16]:
write_cog(diff_mean,
fname="ttest_diff_mean.tif",
overwrite=True)
write_cog(sig_diff_mean,
fname="ttest_sig_diff_mean.tif",
overwrite=True)
[16]:
PosixPath('ttest_sig_diff_mean.tif')
Next steps
When you are done, return to the “Analysis parameters” section, modify some values (e.g. latitude, longitude, time or time_baseline) and re-run the analysis. You can use the interactive map in the “View the selected location” section to find new central latitude and longitude values by panning and zooming, and then clicking on the area you wish to extract location values for. You can also use Google maps to search for a location you know, then return the latitude and longitude
values by clicking the map.
You could also return to the “Compute band indices” section and change which index you use. You may find it interesting to save the GeoTIFFs for both indices and compare them in a GIS program. > Note: remember to change the output file names when saving the GeoTIFFs if you want to keep multiple different outcomes.
Additional information
License The code in this notebook is licensed under the Apache License, Version 2.0.
Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact If you need assistance, please post a question on the DE Africa Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here).
If you would like to report an issue with this notebook, you can file one on Github.
Compatible datacube version
[17]:
print(datacube.__version__)
1.8.20
Last Tested:
[18]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[18]:
'2025-01-16'