Rainfall anomalies from Climate Hazards Group InfraRed Precipitation with Station data (CHIRPS)
Products used: rainfall_chirps_monthly
Keywords: datasets; CHIRPS, climate, rainfall, monthly
Background
Rainfall anomalies are deviations of rainfall from long-run averages. They are useful for identifying wet and dry periods which can be linked to climatically influenced patterns such as flooding, river flows, and agricultural production.
Description
In this real world example we will calculate rainfall anomalies for a selected African country using the CHIRPS monthly rainfall dataset. Standardised anomaly is calculated as:
\begin{equation} \text{Standardised anomaly }=\frac{x-m}{s} \end{equation}
x is the seasonal mean, m is the long-term mean, and s is the long-term standard deviation.
This means we need a long-term reference period (m) and a period of interest (x) for which we’ll calculate the anomalies. This notebook names datasets ds_rf_m and ds_rf_x accordingly.
The notebook outlines:
Loading a shapefile for African countries and selecting a single country
Loading and rainfall data and masking it to the selected country.
Calculating monthly rainfall anomalies and plotting the result, aggregated over space, as a bar chart.
Calculating and plotting monthly rainfall anomalies spatially.
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
Load packages
[1]:
%matplotlib inline
# Force GeoPandas to use Shapely instead of PyGEOS
# In a future release, GeoPandas will switch to using Shapely by default.
import os
os.environ['USE_PYGEOS'] = '0'
import datacube
import numpy as np
import pandas as pd
import geopandas as gpd
import xarray as xr
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from odc.geo.geom import Geometry
from odc.geo import CRS
from deafrica_tools.spatial import xr_rasterize
from deafrica_tools.dask import create_local_dask_cluster
Set up a Dask cluster
Dask can be used to better manage memory use and conduct the analysis in parallel. For an introduction to using Dask with Digital Earth Africa, see the Dask notebook.
Note: We recommend opening the Dask processing window to view the different computations that are being executed; to do this, see the Dask dashboard in DE Africa section of the Dask notebook.
To use Dask, set up the local computing cluster using the cell below.
[2]:
create_local_dask_cluster()
Client
Client-a9724b44-33f3-11f1-830d-4e2ec4a7c32d
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/8787/status |
Cluster Info
LocalCluster
f11f6029
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/8787/status | Workers: 1 |
| Total threads: 4 | Total memory: 26.21 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-d31c6b92-2579-437b-a83b-d77305c683a3
| Comm: tcp://127.0.0.1:45465 | Workers: 0 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/8787/status | Total threads: 0 |
| Started: Just now | Total memory: 0 B |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:43059 | Total threads: 4 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34279/status | Memory: 26.21 GiB |
| Nanny: tcp://127.0.0.1:34533 | |
| Local directory: /tmp/dask-scratch-space/worker-2o4babtm | |
Analysis parameters
The following cell sets important parameters for the analysis:
country: In this analysis, we’ll select an African country to mask the dataset and analysis.time_m: CHIRPS monthly rainfall is available from 1981. The long-term mean for rainfall anomalies is often calculated on a 30-year period, so we’ll use 1981 to 2011 in this example.time_x: This is the period for which we want to calculate anomalies.resolution: We’ll use 5,000 m, which is approximately equal to the default resolution shown above.dask_chunks: the size of the dask chunks, dask breaks data into manageable chunks that can be easily stored in memory, e.g. dict(x=1000,y=1000)
Standardised anomaly is calculated as:
\begin{equation} \text{Standardised anomaly }=\frac{x-m}{s} \end{equation}
\(x\) is the seasonal mean, \(m\) is the long-term mean, and \(s\) is the long-term standard deviation.
This means we need a long-term reference period (m) and a period of interest (x) for which we’ll calculate the anomalies. This notebook names datasets ds_rf_m and ds_rf_x accordingly.
If running the notebook for the first time, keep the default settings below. This will demonstrate how the analysis works and provide meaningful results.
[3]:
# Select a country, for the example we will use Kenya, a complete list of countries is available below.
country = "Kenya"
# Set the range of dates for the climatology, this will be the reference period (m) for the anomaly calculation.
# Standard practice is to use a 30 year period, so we've used 1981 to 2011 in this example.
time_m = ('1981', '2011')
# time period for monthly anomaly (x)
time_x = ('1981', '2021')
# CHIRPS has a spatial resolution of ~5x5 km
resolution = (-5000, 5000)
#size of dask chunks
dask_chunks = dict(x=500,y=500)
Connect to the datacube
Connect to the datacube so we can access DE Africa data. The app parameter is a unique name for the analysis which is based on the notebook file name.
[4]:
dc = datacube.Datacube(app='rainfall_anomaly')
Load the African Countries shapefile
This shapefile contains polygons for the boundaries of African countries and will allows us to calculate rainfall anomalies within a chosen country
[5]:
african_countries = gpd.read_file('../Supplementary_data/Rainfall_anomaly_CHIRPS/african_countries.geojson')
african_countries.explore()
[5]:
List countries
You can change the country in the analysis parameters cell to any African country. A complete list of countries is printed below.
[6]:
print(np.unique(african_countries.COUNTRY))
['Algeria' 'Angola' 'Benin' 'Botswana' 'Burkina Faso' 'Burundi' 'Cameroon'
'Cape Verde' 'Central African Republic' 'Chad' 'Comoros'
'Congo-Brazzaville' 'Cote d`Ivoire' 'Democratic Republic of Congo'
'Djibouti' 'Egypt' 'Equatorial Guinea' 'Eritrea' 'Ethiopia' 'Gabon'
'Gambia' 'Ghana' 'Guinea' 'Guinea-Bissau' 'Kenya' 'Lesotho' 'Liberia'
'Libya' 'Madagascar' 'Malawi' 'Mali' 'Mauritania' 'Morocco' 'Mozambique'
'Namibia' 'Niger' 'Nigeria' 'Rwanda' 'Sao Tome and Principe' 'Senegal'
'Sierra Leone' 'Somalia' 'South Africa' 'Sudan' 'Swaziland' 'Tanzania'
'Togo' 'Tunisia' 'Uganda' 'Western Sahara' 'Zambia' 'Zimbabwe']
Setup polygon
The country selected needs to be transformed into a geometry object to be used in the dc.load() function.
[7]:
idx = african_countries[african_countries['COUNTRY'] == country].index[0]
geom = Geometry(geom=african_countries.iloc[idx].geometry, crs=african_countries.crs)
Load rainfall data
First, let’s have a look at the product information for CHIRPS rainfall. We can see that it is stored in monthly timestamps and its native resolution is approximately 0.05 degrees.
[8]:
dc.list_products().loc[dc.list_products()['name'].str.contains('chirps')]
[8]:
| name | description | license | default_crs | default_resolution | |
|---|---|---|---|---|---|
| name | |||||
| rainfall_chirps_daily | rainfall_chirps_daily | Rainfall Estimates from Rain Gauge and Satelli... | None | EPSG:4326 | Resolution(x=0.05, y=-0.05) |
| rainfall_chirps_monthly | rainfall_chirps_monthly | Rainfall Estimates from Rain Gauge and Satelli... | None | EPSG:4326 | Resolution(x=0.05, y=-0.05) |
Load data for long-term climatology (m)
Using the analysis parameters defined above, we will load CHIRPS monthly rainfall data for the 30-year reference period (m).
[9]:
query = {'geopolygon': geom,
'time': time_m,
'output_crs': 'epsg:6933',
'resolution': resolution,
'measurements': ['rainfall'],
'dask_chunks':dask_chunks
}
ds_rf = dc.load(product='rainfall_chirps_monthly', **query)
ds_rf
[9]:
<xarray.Dataset> Size: 55MB
Dimensions: (time: 372, y: 238, x: 155)
Coordinates:
* time (time) datetime64[ns] 3kB 1981-01-16T11:59:59.500000 ... 201...
* y (y) float64 2kB 5.875e+05 5.825e+05 ... -5.925e+05 -5.975e+05
* x (x) float64 1kB 3.272e+06 3.278e+06 ... 4.038e+06 4.042e+06
spatial_ref int32 4B 6933
Data variables:
rainfall (time, y, x) float32 55MB dask.array<chunksize=(1, 238, 155), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refMask the rainfall dataset using the country boundary
Below, the country polygon is rasterized so the rainfall dataset is masked within that raster.
[10]:
african_countries = african_countries.to_crs('epsg:6933')
mask = xr_rasterize(african_countries[african_countries['COUNTRY'] == country], ds_rf)
#mask the rainfall dataset
ds_rf = ds_rf.where(mask)
# Plot the mask
mask.plot()
[10]:
<matplotlib.collections.QuadMesh at 0x7f50e955fda0>
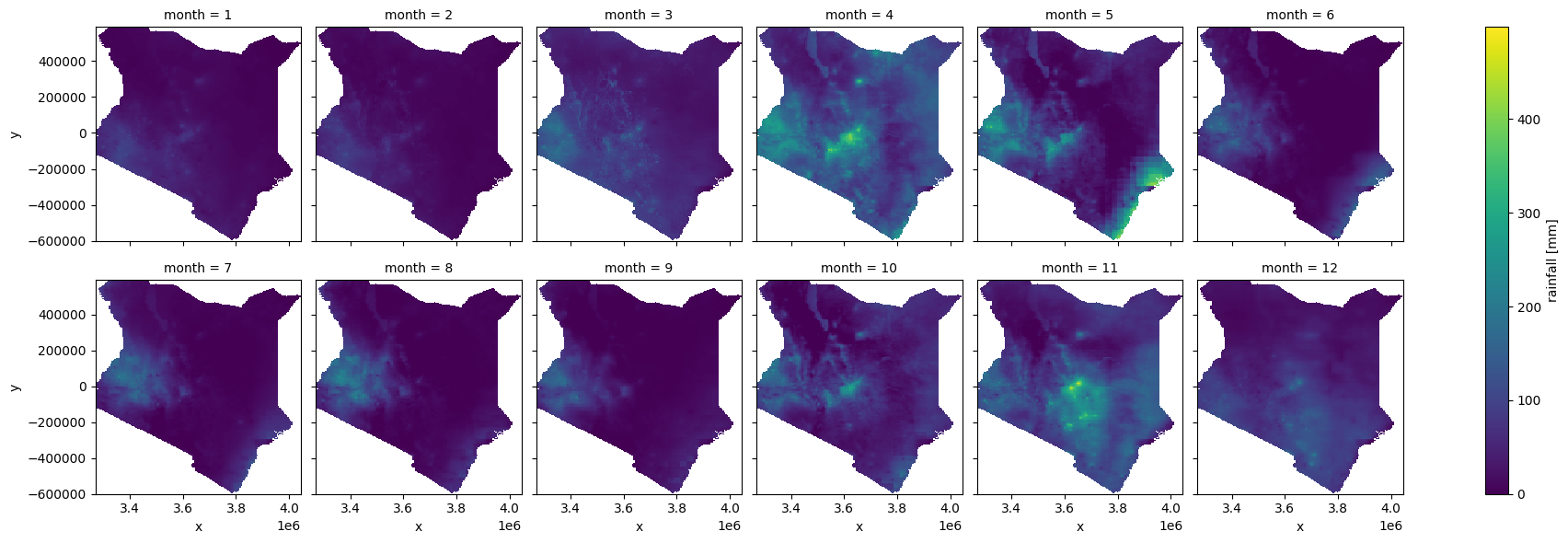
Calculate monthly rainfall climatology
We want to capture both the monthly mean (i.e. each month averaged over thirty years) and the monthly standard deviation of rainfall within the country polygon for each year from 1981 to 2011. Firstly, rainfall is grouped by month and a mean is calculated, then the standard devation in rainfall total for each month is calculated
[11]:
ds_rf_m = ds_rf.where(ds_rf !=-9999.) #convert missing values to NaN
# monthly means
climatology_mean = ds_rf_m.groupby('time.month').mean('time').compute()
#calculate monthly std dev
climatology_std = ds_rf_m.groupby('time.month').std('time').compute()
Now we can plot the rainfall mean climatology, this is the average rainfall (over 30 years) for each month
[12]:
climatology_mean['rainfall'].plot.imshow(cmap='viridis', col='month', col_wrap=6, label=False);
Load data for the anomaly period
Using the analysis parameters defined above, we will load CHIRPS rainfall data for the period over which we want to calculate anomalies (x). We also need to mask this dataset to the country polygon.
[13]:
#load rainfall data for the anomaly period matching the spatial extent of the climatologies
ds_rf_x = dc.load(product='rainfall_chirps_monthly',
like=ds_rf.odc.geobox,
time=time_x,
dask_chunks=dask_chunks)
#mask with country polygon
ds_rf_x=ds_rf_x.where(mask)
Calculate standardised anomalies
We can visualise the anomalies spatially and see if they are associated with certain landscape features.
Do the spatial anomalies shown in the plots below align with the aggregated anomalies shown above?
[14]:
stand_anomalies = xr.apply_ufunc(
lambda x, m, s: (x - m) / s,
ds_rf_x.groupby("time.month"),
climatology_mean,
climatology_std,
output_dtypes=[ds_rf_x.rainfall.dtype],
dask="allowed"
).compute()
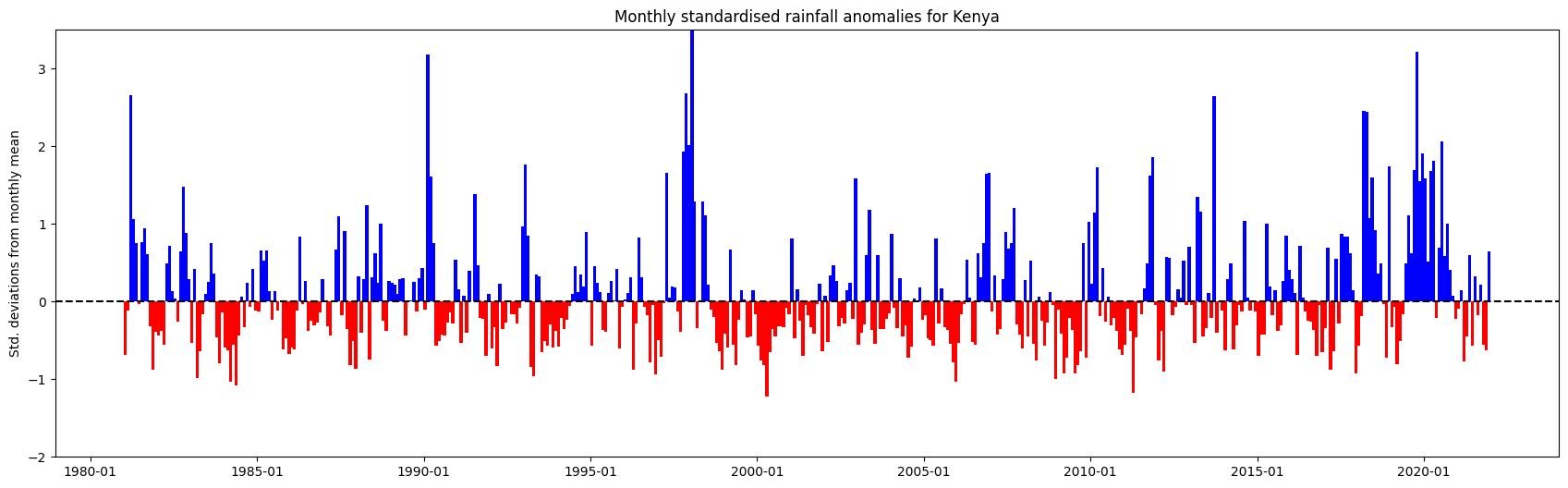
Plot average rainfall anomalies across the country
Below, the spatial mean is taken so we can present the monthly anomalies aggregated across the selected country.
[15]:
spatial_mean_anoms = stand_anomalies.rainfall.mean(['x','y']).to_dataframe().drop(['spatial_ref', 'month'], axis=1)
Below, we plot a bar graph that will show the average rainfall anomaly across the country
[16]:
fig, ax = plt.subplots(figsize=(21,6))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m"))
ax.set_ylim(-2,3.5)
ax.bar(spatial_mean_anoms.index,
spatial_mean_anoms.rainfall,
width=35, align='center',
color=(spatial_mean_anoms['rainfall'] > 0).map({True: 'b', False: 'r'}))
ax.axhline(0, color='black', linestyle='--')
plt.title('Monthly standardised rainfall anomalies for '+country)
plt.ylabel('Std. deviations from monthly mean');
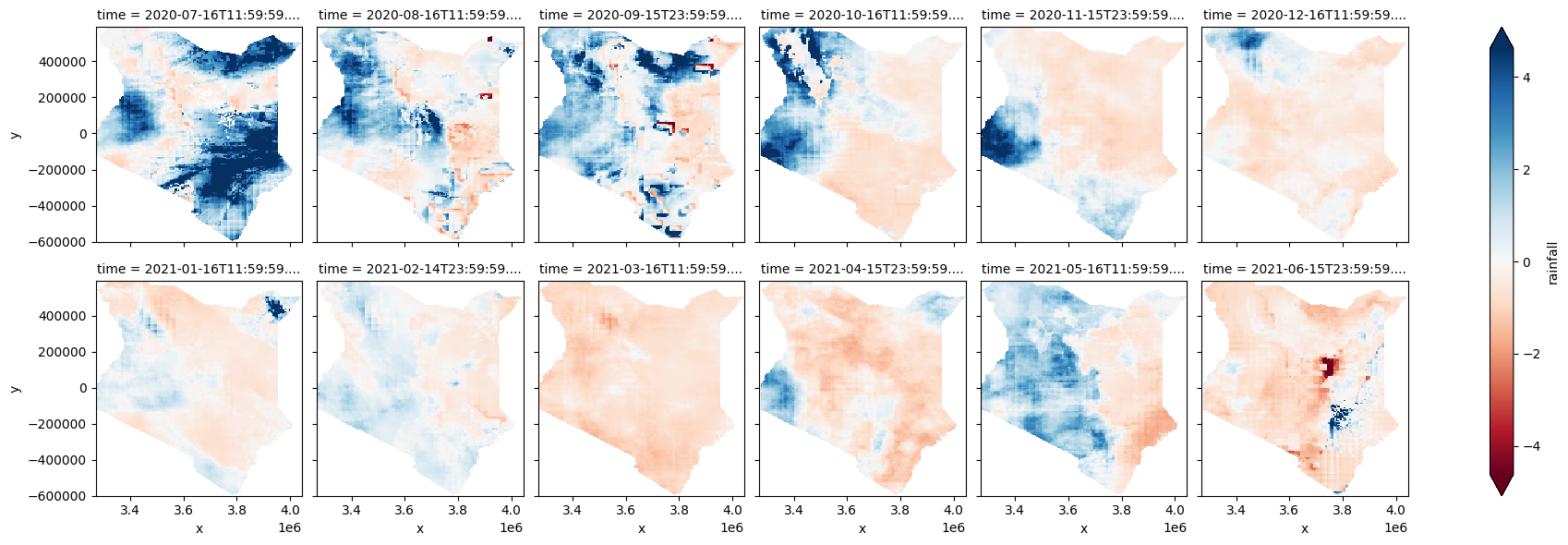
Per-pixel plots of rainfall anomalies
Average anomalies across the entire country obscure details on how rainfall anomalies are spatially distrbuted within the country. Below, enter a start and end date (in format 'YYYY-MM') that is within the time_x range you entered in the Analysis parameters section to plot per-pixel anomalies for the range of dates you specify.
[17]:
#Select a time-range to plot
start='2020-07'
end='2021-06'
Plot the per-pixel anomalies
[18]:
stand_anomalies['rainfall'].sel(time=slice(start,end)).plot(cmap='RdBu', label=False, col="time", col_wrap=6, robust=True);
Additional information
License The code in this notebook is licensed under the Apache License, Version 2.0.
Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact If you need assistance, please post a question on the DE Africa Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here).
If you would like to report an issue with this notebook, you can file one on Github.
Compatible datacube version
[19]:
print(datacube.__version__)
1.9.13
Last Tested:
[20]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[20]:
'2026-04-09'