Generating composite images
Products used: s2_l2a
Keywords data used; sentinel-2, band index; NDVI, analysis; time series, analysis; composites
Background
Individual remote sensing images can be affected by noisy data, including clouds, cloud shadows, and haze. To produce cleaner images that can be compared more easily across time, we can create ‘summary’ images or ‘composites’ that combine multiple images into one.
Some methods for generating composites include estimating the median, mean, minimum, or maximum pixel values in an image. Care must be taken with these, as they do not necessarily preserve spectral relationships across bands. To learn how to generate a composite that does preserve these relationships, see the Generating geomedian composites notebook.
Description
This notebook demonstrates how to generate a number of different composites from satellite images, and discusses the uses of each. Specifically, this notebook demonstrates how to generate:
Median composites
Mean composites
Minimum and maximum composites
Nearest-time composites
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
Load packages
Import Python packages that are used for the analysis.
[1]:
%matplotlib inline
import datacube
import matplotlib.pyplot as plt
import xarray as xr
import geopandas as gpd
from odc.geo.geom import Geometry
from deafrica_tools.plotting import rgb
from deafrica_tools.datahandling import load_ard, mostcommon_crs, first, last, nearest
from deafrica_tools.bandindices import calculate_indices
from deafrica_tools.areaofinterest import define_area
Connect to the datacube
Connect to the datacube so we can access DE Africa data. The app parameter is a unique name for the analysis which is based on the notebook file name.
[2]:
dc = datacube.Datacube(app='Generating_composites')
Load Sentinel-2 data
Here we load a timeseries of cloud-masked Sentinel-2 satellite images through the datacube API using the load_ard function.
To define the area of interest, there are two methods available:
By specifying the latitude, longitude, and buffer. This method requires you to input the central latitude, central longitude, and the buffer value in square degrees around the center point you want to analyze. For example,
lat = 10.338,lon = -1.055, andbuffer = 0.1will select an area with a radius of 0.1 square degrees around the point with coordinates (10.338, -1.055).By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
To use one of these methods, you can uncomment the relevant line of code and comment out the other one. To comment out a line, add the "#" symbol before the code you want to comment out. By default, the first option which defines the location using latitude, longitude, and buffer is being used.
[3]:
# Set the area of interest
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=14.970, lon=-4.127, buffer=0.075)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
# aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# Create a reusable query
query = {
'x': lon_range,
'y': lat_range,
'time': ('2019'),
'measurements': ['green', 'red', 'blue', 'nir'],
'resolution': (-20, 20),
'group_by': 'solar_day'
}
# Identify the most common projection system in the input query
output_crs = mostcommon_crs(dc=dc, product='s2_l2a', query=query)
# Load available data
ds = load_ard(dc=dc,
products=['s2_l2a'],
output_crs=output_crs,
**query)
# Print output data
print(ds)
Using pixel quality parameters for Sentinel 2
Finding datasets
s2_l2a
Applying pixel quality/cloud mask
Loading 73 time steps
<xarray.Dataset> Size: 790MB
Dimensions: (time: 73, y: 834, x: 811)
Coordinates:
* time (time) datetime64[ns] 584B 2019-01-03T10:56:58 ... 2019-12-2...
* y (y) float64 7kB 1.664e+06 1.664e+06 ... 1.647e+06 1.647e+06
* x (x) float64 6kB 3.707e+05 3.707e+05 ... 3.869e+05 3.869e+05
spatial_ref int32 4B 32630
Data variables:
green (time, y, x) float32 198MB 2.057e+03 2.118e+03 ... 1.66e+03
red (time, y, x) float32 198MB 2.519e+03 2.603e+03 ... 1.727e+03
blue (time, y, x) float32 198MB 1.408e+03 1.505e+03 ... 742.0 838.0
nir (time, y, x) float32 198MB 3.623e+03 3.664e+03 ... 4.147e+03
Attributes:
crs: epsg:32630
grid_mapping: spatial_ref
Plot timesteps in true colour
To visualise the data, use the pre-loaded rgb utility function to plot a true colour image for a series of timesteps. White areas indicate where clouds or other invalid pixels in the image have been masked.
The code below will plot four timesteps of the time series we just loaded.
[4]:
# Set the timesteps to visualise
timesteps = [1, 3, -3, -1]
# Generate RGB plots at each timestep
rgb(ds, index=timesteps)

Median composites
One of the key reasons for generating a composite is to replace pixels classified as clouds with realistic values from the available data. This results in an image that doesn’t contain any clouds. In the case of a median composite, each pixel is selected to have the median (or middle) value out of all possible values.
Care should be taken when using these composites for analysis, since the relationships between spectral bands are not preserved. These composites are also affected by the timespan they’re generated over. For example, the median pixel in a single season may be different to the median value for the whole year.
Generating a single composite from all data
To generate a single median composite, we use the xarray.median method, specifying 'time' as the dimension to compute the median over.
[5]:
# Compute a single median from all data
ds_median = ds.median('time')
# View the resulting median
rgb(ds_median, bands=['red', 'green', 'blue'])

Generating multiple composites based on length of time
Rather than using all the data to generate a single median composite, it’s possible to use the xarray.resample method to group the data into smaller time-spans and generate medians for each of these. Some resampling options are
'nD'- number of days (e.g.'7D'for seven days)'nM'- number of months (e.g.'6M'for six months)'nY'- number of years (e.g.'2Y'for two years)
If the area is particularly cloudy during one of the time-spans, there may still be masked pixels that appear in the median. This will be true if that pixel is always masked.
[6]:
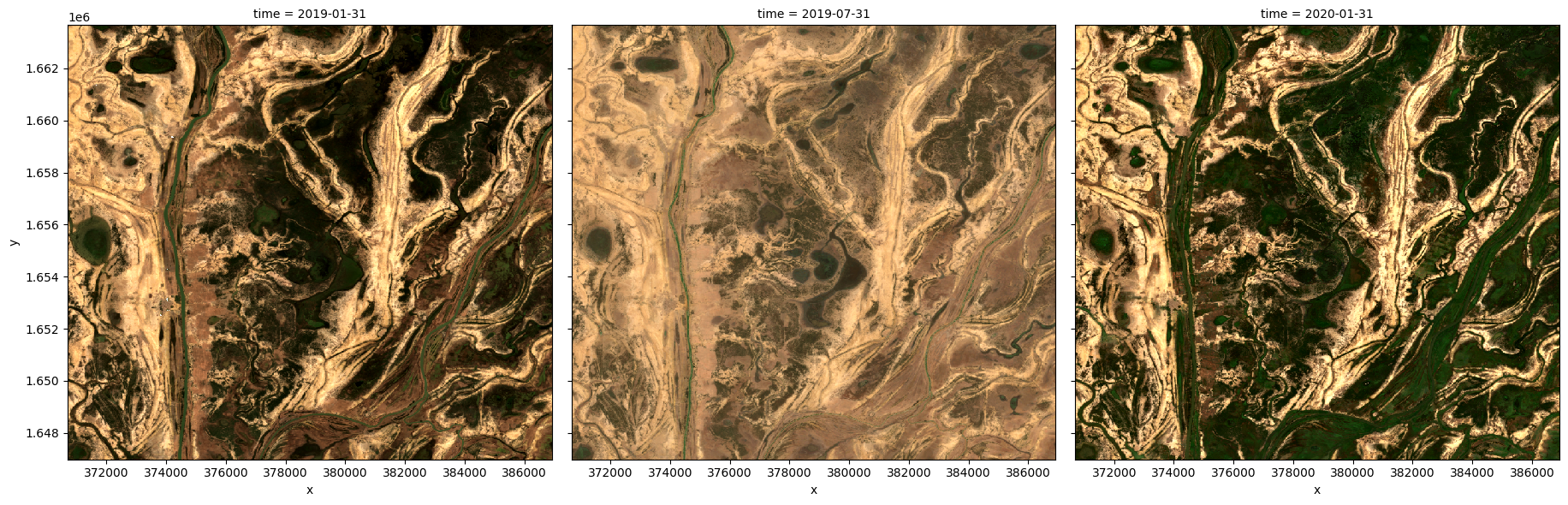
# Generate a median by binning data into six-monthly time-spans
ds_resampled_median = ds.resample(time='6M').median('time')
# View the resulting medians
rgb(ds_resampled_median, bands=['red', 'green', 'blue'], col='time')
<string>:7: FutureWarning: 'M' is deprecated and will be removed in a future version. Please use 'ME' instead of 'M'.
Group By
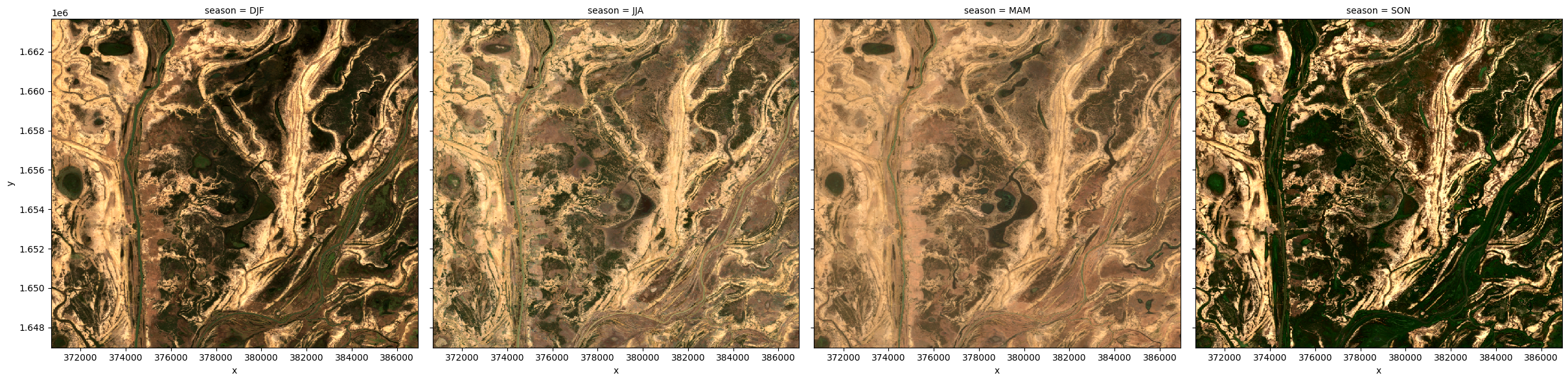
Similar to resample, grouping works by looking at part of the date, but ignoring other parts. For instance, 'time.month' would group together all January data together, no matter what year it is from.
Some examples are:
'time.day'- groups by the day of the month (1-31)'time.dayofyear'- groups by the day of the year (1-365)'time.week'- groups by week (1-52)'time.month'- groups by the month (1-12)'time.season'- groups into 3-month seasons:'DJF'December, Jaunary, February'MAM'March, April, May'JJA'June, July, August'SON'September, October, November
'time.year'- groups by the year
[7]:
# Generate a median by binning data into six-monthly time-spans
ds_groupby_season = ds.groupby('time.season').median()
# View the resulting medians
rgb(ds_groupby_season, bands=['red', 'green', 'blue'], col='season')
Mean composites
Mean composites involve taking the average value for each pixel, rather than the middle value as is done for a median composite. Unlike the median, the mean composite can contain pixel values that were not part of the original dataset. Care should be taken when interpreting these images, as extreme values (such as unmasked cloud) can strongly affect the mean.
Generating a single composite from all data
To generate a single mean composite, we use the xarray.mean method, specifying 'time' as the dimension to compute the mean over.
Note: If there are no valid values for a given pixel, you may see the warning:
RuntimeWarning: Mean of empty slice. The composite will still be generated, but may have blank areas.
[8]:
# Compute a single mean from all data
ds_mean = ds.mean('time')
# View the resulting mean
rgb(ds_mean, bands=['red', 'green', 'blue'])

Generating multiple composites based on length of time
As with the median composite, it’s possible to use the xarray.resample method to group the data into smaller time-spans and generate means for each of these. See the previous section for some example resampling time-spans.
Note: If you get the warning RuntimeWarning: Mean of empty slice, this just means that for one of your groups there was at least one pixel that contained all nan values.
[9]:
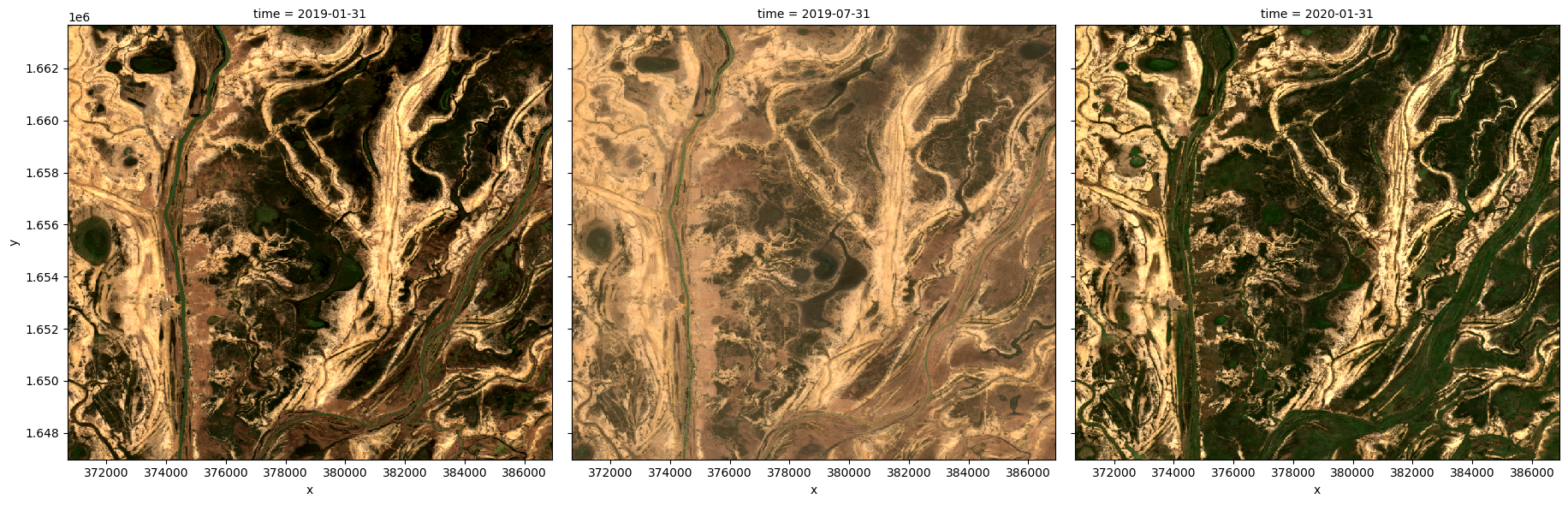
# Generate a mean by binning data into six-monthly time-spans
ds_resampled_mean = ds.resample(time='6M').mean('time')
# View the resulting medians
rgb(ds_resampled_mean, bands=['red', 'green', 'blue'], col='time')
<string>:7: FutureWarning: 'M' is deprecated and will be removed in a future version. Please use 'ME' instead of 'M'.
Minimum and maximum composites
These composites can be useful for identifying extreme behaviour in a collection of satellite images.
For example, comparing the maximum and minimum composites for a given band index could help identify areas that take on a wide range of values, which may indicate areas that have high variability over the time-line of the composite.
To demonstrate this, we start by calculating the normalised difference vegetation index (NDVI) for our data, which can then be used to generate the maximum and minimum composites.
[10]:
# Start by calculating NDVI
ds = calculate_indices(ds, index='NDVI', satellite_mission='s2')
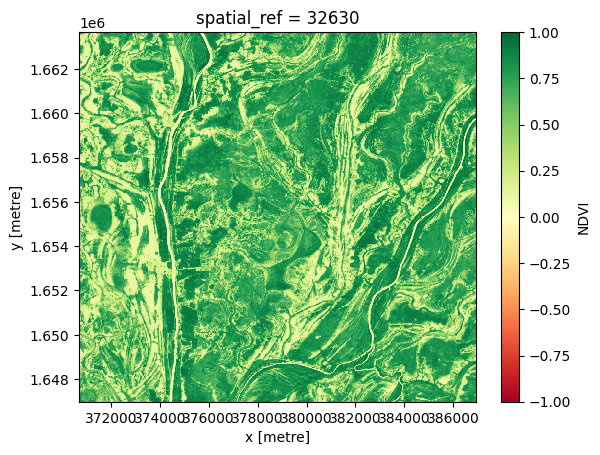
Maximum composite
To generate a single maximum composite, we use the xarray.max method, specifying 'time' as the dimension to compute the maximum over.
[11]:
# Compute the maximum composite
ds_max = ds.NDVI.max('time')
# View the resulting composite
ds_max.plot(vmin=-1, vmax=1, cmap='RdYlGn');
Minimum composite
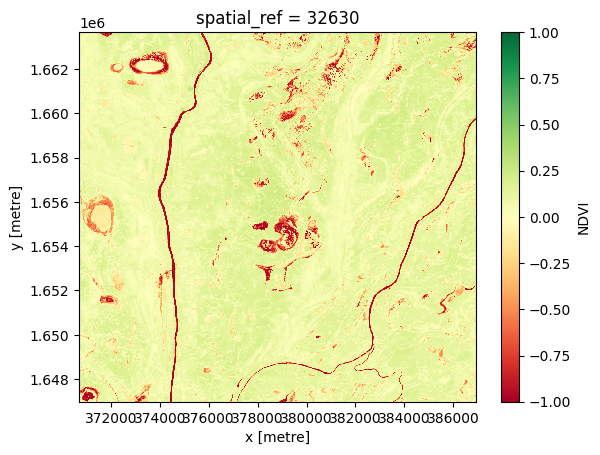
To generate a single minimum composite, we use the xarray.min method, specifying 'time' as the dimension to compute the minimum over.
[12]:
# Compute the minimum composite
ds_min = ds.NDVI.min('time')
# View the resulting composite
ds_min.plot(vmin=-1, vmax=1, cmap='RdYlGn');
Nearest-time composites
To get an image at a certain time, often there is missing data, due to clouds and other masking. We can fill in these gaps by using data from surrounding times.
To generate these images, we can use the custom functions first, last and nearest from the deafrica.datahandling module.
You can also use the in-built .first() and .last() methods when doing groupby and resample as described above. They are described in the xarray documentation on grouped data.
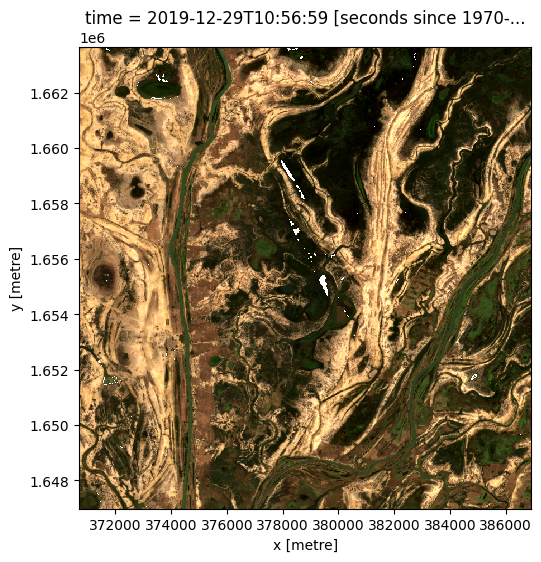
Most-recent composite
Sometime we may want to determine what the landscape looks like by examining the most recent image. If we look at the last image for our dataset, we can see there is some missing data in the center of the last image.
[13]:
# Plot the last image in time
rgb(ds, index=[-1])
We can calculate how much of the data is missing in this most recent image
[14]:
last_blue_image = ds.blue.isel(time=-1)
precent_valid_data = float(last_blue_image.count() / last_blue_image.size) * 100
print(f"The last image contains {precent_valid_data:.2f}% data.")
The last image contains 99.79% data.
In order to fill in the gaps and produce a complete image showing the most-recent satellite acquistion for every pixel, we can run the last function on one of the arrays.
[15]:
last_blue = last(ds.blue, dim='time')
last_blue.plot();

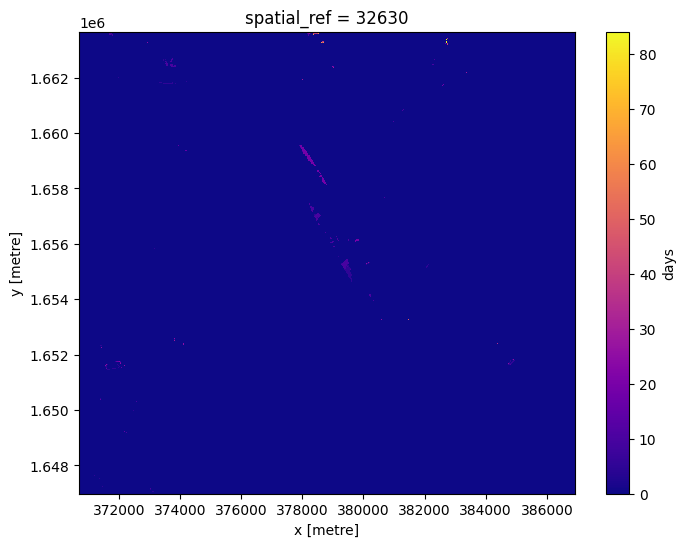
To see how recent each pixel is, we can compare the age of the pixels with the latest value we have.
Here we can see that most pixels were from the last time slice, although there are some that were much older.
[16]:
# Identify lastest time in our data
last_time = last_blue.time.max()
# Compare the timestamps and convert them to number of days for plotting.
num_days_old = (last_time - last_blue.time).dt.days
num_days_old.plot(cmap='plasma', size=6);
We can run this method on all of the bands. However we only want pixels that have data in every band. On the edges of a satellite pass, some bands don’t have data.
To get rid of pixels with missing data, we will convert the dataset to an array, and select only those pixels with data in all bands.
[17]:
#Convert to array
da = ds.to_array(dim='variable')
#create a mask where data has no-data
no_data_mask = da.isnull().any(dim='variable')
#mask out regions where there is no-data
da = da.where(~no_data_mask)
Now we can run the last function on the array, then turn it back into a dataset.
[18]:
da_latest = last(da, dim='time')
ds_latest = da_latest.to_dataset(dim='variable').drop_dims('variable')
# View the resulting composite
rgb(ds_latest, bands=['red', 'green', 'blue'])

Before and after composites
Often it is useful to view images before and after an event, to see the change that has occured.
To generate a composite on either side of an event, we can split the dataset along time.
We can then view the composite last image before the event, and the composite first image after the event.
[19]:
# Dates here are inclusive. Use None to not set a start or end of the range.
before_event = slice(None, '2019-06-01')
after_event = slice('2019-06-03', None)
# Select the time period and run the last() or first() function on every band.
da_before = last(da.sel(time=before_event), dim='time')
da_after = first(da.sel(time=after_event), dim='time')
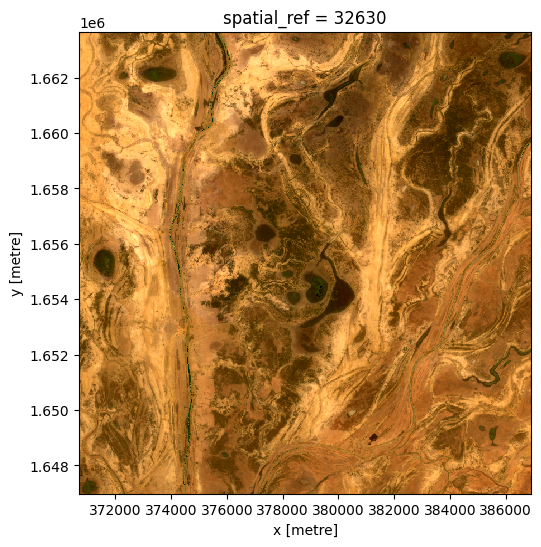
The composite image before the event, up to 2019-06-01:
[20]:
ds_before = da_before.to_dataset(dim='variable').drop_dims('variable')
rgb(ds_before, bands=['red', 'green', 'blue'])
The composite image after the event, from 2019-06-03:
[21]:
ds_after = da_after.to_dataset(dim='variable').drop_dims('variable')
rgb(ds_after, bands=['red', 'green', 'blue'])
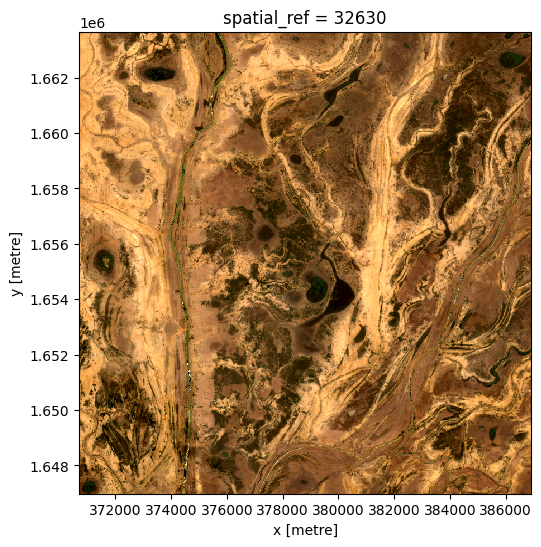
Nearest time composite
Sometimes we just want the closest availible data to a particular point in time. This composite will take values from before or after the specified time to find the nearest observation.
[22]:
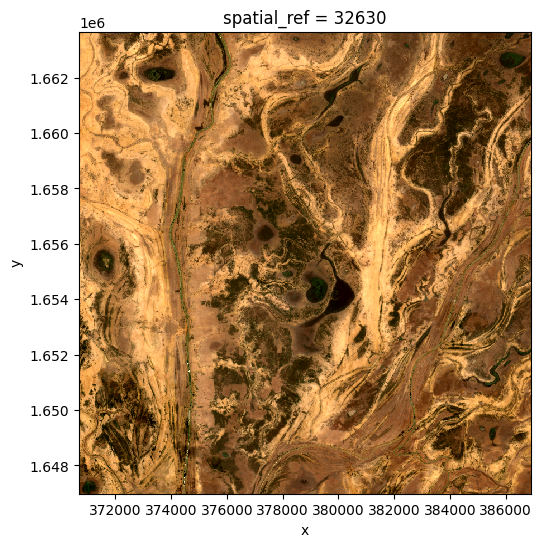
da_nearest = nearest(da, dim='time', target='2019-06-03')
ds_nearest = da_nearest.to_dataset(dim='variable').drop_dims('variable')
rgb(ds_nearest, bands=['red', 'green', 'blue'])
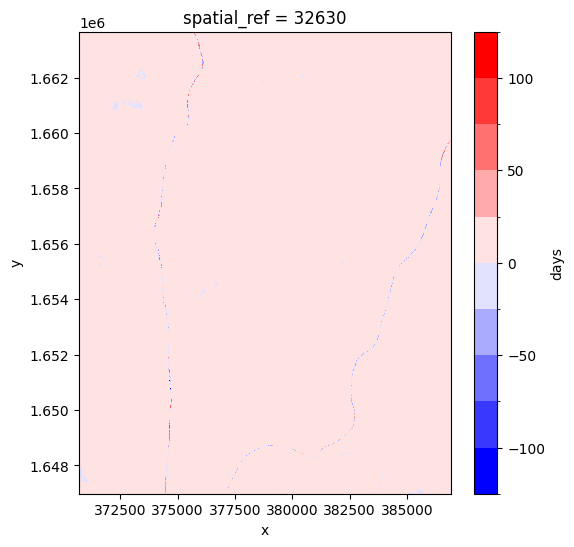
By looking at the time for each pixel, we can see if the pixel was taken from before or after the target time.
[23]:
target_datetime = da_nearest.time.dtype.type('2019-06-03')
# calculate different in times and convert to number of days
num_days_different = (da_nearest.time.min(dim='variable') - target_datetime).dt.days
num_days_different.plot(cmap='bwr', levels=11, figsize=(6,6));
Additional information
License: The code in this notebook is licensed under the Apache License, Version 2.0. Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact: If you need assistance, please post a question on the Open Data Cube Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here). If you would like to report an issue with this notebook, you can file one on
Github.
Compatible datacube version:
[24]:
print(datacube.__version__)
1.8.20
Last Tested:
[25]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[25]:
'2025-01-15'