Monitoring chlorophyll-a in African waterbodies
Products used: s2_l2a
Keywords: data used; sentinel 2, band index; MNDWI, band index; NDCI, analysis; change monitoring, water quality
Background
Inland waterbodies are essential for supporting human life, both through the supply of drinking water and the support of agriculture and aquaculture. Such waterbodies can be contaminated by urban pollutants from the communities living nearby, causing health issues for people and animals. While the health of waterbodies can be monitored from the ground through sampling, satellite imagery can complement this. One particular event that is related to poor water quality is the presence of algal blooms. Specifically, waters with high levels of nutrients from fertilizers, sewage or urban runoff can host large algal blooms. However, there needs to be a well-understood and tested way to link satellite observations to the presence of algal blooms.
Sentinel-2 use case
Algal blooms are associated with the presence of chlorophyll-a in waterbodies. Mishra and Mishra (2012) developed the normalised difference chlorophyll index (NDCI), which serves as a qualitative indicator for the concentration of clorophyll-a on the surface of a waterbody. The index requires information from a specific part of the infrared specturm, known as the ‘red edge’. This is captured as part of Sentinel-2’s 13 spectral bands, making it possible to measure the NDCI with Sentinel-2.
Description
In this example, we measure the NDCI for Lake Bosomtwe, which is getting affected by the pollution as mentioned in the Background section. This is combined with information about the size of the waterbody, which is used to build a helpful visualisation of how the water-level and presence of chlorophyll-a changes over time. The worked example takes users through the code required to:
Load cloud-free Sentinel-2 images for an area of interest.
Compute indices to measure the presence of water and clorophyll-a.
Generate informative visualisations to identify the presence of clorophyll-a.
Some caveats
The NDCI is currently treated as an experimental index for Sentinel-2 sensors, as futher work is needed to calibrate and validate how well the index relates to the presence of clorophyll-a.
It is also important to remember that algal blooms will usually result in increased values of the NDCI, but not all NDCI increases will be from algal blooms. For example, there may be seasonal fluctuations in the amount of clorophyll-a in a waterbody.
Further validation work is required to understand how shallow water and atmospheric effects affect the NDCI, and its use in identifying high concentrations of clorophyll-a.
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
After finishing the analysis, return to the “Analysis parameters” cell, modify some values (e.g. choose a different location or time period to analyse) and re-run the analysis. There are additional instructions on modifying the notebook at the end.
Load packages
Load key Python packages and supporting functions for the analysis.
[1]:
%matplotlib inline
import datacube
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import geopandas as gpd
import sys
import xarray as xr
import warnings
warnings.filterwarnings("ignore")
from odc.geo.geom import Geometry
from deafrica_tools.spatial import xr_rasterize
from deafrica_tools.plotting import display_map, rgb
from deafrica_tools.datahandling import load_ard, mostcommon_crs
from deafrica_tools.bandindices import calculate_indices
from deafrica_tools.dask import create_local_dask_cluster
from deafrica_tools.areaofinterest import define_area
Set up a Dask cluster
Dask can be used to better manage memory use down and conduct the analysis in parallel. For an introduction to using Dask with Digital Earth Africa, see the Dask notebook.
Note: We recommend opening the Dask processing window to view the different computations that are being executed; to do this, see the Dask dashboard in DE Africa section of the Dask notebook.
To use Dask, set up the local computing cluster using the cell below.
[2]:
create_local_dask_cluster()
Client
Client-dea766b6-3752-11f1-927a-66901f7a1b9b
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34857/status |
Cluster Info
LocalCluster
1b142241
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34857/status | Workers: 1 |
| Total threads: 4 | Total memory: 26.21 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-d865b351-99a5-4fe0-ae00-a308558e90ee
| Comm: tcp://127.0.0.1:36423 | Workers: 0 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34857/status | Total threads: 0 |
| Started: Just now | Total memory: 0 B |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:45477 | Total threads: 4 |
| Dashboard: /user/mpho.sadiki@digitalearthafrica.org/proxy/34299/status | Memory: 26.21 GiB |
| Nanny: tcp://127.0.0.1:46243 | |
| Local directory: /tmp/dask-scratch-space/worker-pyqa_vbn | |
2026-04-13 16:10:50,087 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0)->('gt-stack-all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0))
new run_spec: Alias(('all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0)->('getitem-gt-stack-all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0))
old dependencies: {('gt-stack-all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0)}
new dependencies: frozenset({('getitem-gt-stack-all-33a329eb7b1e1eaf675668bc7f54ad0d', 0, 31, 0, 0)})
Connect to the datacube
Activate the datacube database, which provides functionality for loading and displaying stored Earth observation data.
[3]:
dc = datacube.Datacube(app="Chlorophyll_monitoring")
Analysis parameters
The following cell sets the parameters, which define the area of interest and the length of time to conduct the analysis over. The parameters are
lat: The central latitude to analyse (e.g.6.502).lon: The central longitude to analyse (e.g.-1.409).buffer: The number of square degrees to load around the central latitude and longitude. For reasonable loading times, set this as0.1or lower.time: The date range to analyse (e.g.("2017-08-01", "2019-11-01")). For reasonable loading times, make sure the range spans less than 3 years. Note that Sentinel-2 data is only available after July 2015.
Select location
To define the area of interest, there are two methods available:
By specifying the latitude, longitude, and buffer. This method requires you to input the central latitude, central longitude, and the buffer value in square degrees around the center point you want to analyze. For example,
lat = 10.338,lon = -1.055, andbuffer = 0.1will select an area with a radius of 0.1 square degrees around the point with coordinates (10.338, -1.055).Alternatively, you can provide separate buffer values for latitude and longitude for a rectangular area. For example,
lat = 10.338,lon = -1.055, andlat_buffer = 0.1andlon_buffer = 0.08will select a rectangular area extending 0.1 degrees north and south, and 0.08 degrees east and west from the point(10.338, -1.055).For reasonable loading times, set the buffer as
0.1or lower.By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
To use one of these methods, you can uncomment the relevant line of code and comment out the other one. To comment out a line, add the "#" symbol before the code you want to comment out. By default, the first option which defines the location using latitude, longitude, and buffer is being used.
If running the notebook for the first time, keep the default settings below. This will demonstrate how the analysis works and provide meaningful results. The example covers Lake Bosomtwe, one of the largest lakes in Western Africa.
To run the notebook for a different area, make sure Sentinel-2 data is available for the chosen area using the DEAfrica Explorer. Use the drop-down menu to check coverage for s2_l2a.
[4]:
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=-17.9, lon=30.8, buffer=0.04)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
#aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# Set the range of dates for the analysis
time = ("2018-01-01", "2019-12-31")
View the selected location
The next cell will display the selected area on an interactive map. Feel free to zoom in and out to get a better understanding of the area you’ll be analysing. Clicking on any point of the map will reveal the latitude and longitude coordinates of that point.
[5]:
display_map(x=lon_range, y=lat_range)
[5]:
Load and view Sentinel-2 data
The first step in the analysis is to load Sentinel-2 data for the specified area of interest and time range. This uses the pre-defined load_ard utility function. This function will automatically mask any clouds in the dataset, and only return images where more than 80% of the pixels were classified as clear.
Note: This analysis performs calculations that use the on-ground area of each pixel. For this type of analysis, it is recommended that all data be reprojected to an equal area projection, such as EPSG:6933. This is done below by setting the
output_crsparameter to"EPSG:6933".
Please be patient. The data may take a few minutes to load and progress will be indicated by text output. The load is complete when the cell status goes from [*] to [number].
[6]:
# Choose the Sentinel-2 products to load
products = ["s2_l2a"]
# Create a reusable query
query = {
"x": lon_range,
"y": lat_range,
"time": time,
"resolution": (-10, 10),
"measurements": ["red_edge_1",
"red",
"green",
"blue",
"nir_1",
"swir_1",]
}
# Since this analysis calculates pixel areas,
# set the output projection to equal area projection EPSG:6933
output_crs = "EPSG:6933"
# Load available data from Sentinel-2A and -2B and filter to retain only times
# with at least 80% good data
ds = load_ard(dc=dc,
products=products,
min_gooddata=0.9,
output_crs=output_crs,
group_by="solar_day",
dask_chunks={'time':1, 'x':2000, 'y':2000},
**query)
Using pixel quality parameters for Sentinel 2
Finding datasets
s2_l2a
Counting good quality pixels for each time step
/opt/venv/lib/python3.12/site-packages/rasterio/warp.py:385: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix will be returned.
dest = _reproject(
Filtering to 76 out of 146 time steps with at least 90.0% good quality pixels
Applying pixel quality/cloud mask
Returning 76 time steps as a dask array
Once the load is complete, examine the data by printing it in the next cell. The Dimensions argument revels the number of time steps in the data set, as well as the number of pixels in the x (longitude) and y (latitude) dimensions.
[7]:
ds
[7]:
<xarray.Dataset> Size: 1GB
Dimensions: (time: 76, y: 973, x: 773)
Coordinates:
* time (time) datetime64[ns] 608B 2018-01-02T08:07:58 ... 2019-12-2...
* y (y) float64 8kB -2.243e+06 -2.243e+06 ... -2.252e+06 -2.252e+06
* x (x) float64 6kB 2.968e+06 2.968e+06 ... 2.976e+06 2.976e+06
spatial_ref int32 4B 6933
Data variables:
red_edge_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
red (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
green (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
blue (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
nir_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
swir_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refClip the datasets to the shape of the area of interest
A geopolygon represents the bounds and not the actual shape because it is designed to represent the extent of the geographic feature being mapped, rather than the exact shape. In other words, the geopolygon is used to define the outer boundary of the area of interest, rather than the internal features and characteristics.
Clipping the data to the exact shape of the area of interest is important because it helps ensure that the data being used is relevant to the specific study area of interest. While a geopolygon provides information about the boundary of the geographic feature being represented, it does not necessarily reflect the exact shape or extent of the area of interest.
[8]:
#Rasterise the area of interest polygon
aoi_raster = xr_rasterize(gdf=geopolygon_gdf, da=ds, crs=ds.crs)
#Mask the dataset to the rasterised area of interest
ds = ds.where(aoi_raster == 1)
Plot example timestep in true colour
To visualise the data, use the pre-loaded rgb utility function to plot a true colour image for a given time-step.
The settings below will display images for a two time steps, one in November 2017, one in January 2019. White areas indicate where clouds or other invalid pixels in the image have been masked. What are the key differences between the two images?
Feel free to experiement with the values for the initial_timestep and final_timestep variables; re-run the cell to plot the images for the new timesteps. The values for the timesteps can be 0 to n_time - 1 where n_time is the number of timesteps (see the time listing under the Dimensions category in the dataset print-out above).
Note: if the location and time are changed, you may need to change the
intial_timestepandfinal_timestepparameters to view images at similar times of year.
[9]:
# Set the timesteps to visualise
initial_timestep = 3
final_timestep = 28
# Generate RGB plots at each timestep
rgb(ds, index=[initial_timestep, final_timestep],
percentile_stretch=[0.01, 0.99])

Compute band indices
This study measures the presence of water through the modified normalised difference water index (MNDWI) and clorophyll-a through the normalised difference clorophyll index (NDCI).
MNDWI is calculated from the green and shortwave infrared (SWIR) bands to identify water. The formula is
When interpreting this index, values greater than 0 indicate water.
NDCI is calculated from the red edge 1 and red bands to identify water. The formula is
When interpreting this index, high values indicate the presence of clorophyll-a.
Both indices are available through the calculate_indices function, imported from deafrica_tools.bandindices. Here, we use satellite_mission="s2" since we’re working with Sentinel-2 data.
[10]:
# Calculate MNDWI and add it to the loaded data set
ds = calculate_indices(ds, index="MNDWI", satellite_mission="s2")
# Calculate NDCI and add it to the loaded data set
ds = calculate_indices(ds, index="NDCI", satellite_mission="s2")
The MNDWI and NDCI values should now appear as data variables, along with the loaded measurements, in the ds data set. Check this by printing the data set below:
[11]:
ds
[11]:
<xarray.Dataset> Size: 2GB
Dimensions: (time: 76, y: 973, x: 773)
Coordinates:
* time (time) datetime64[ns] 608B 2018-01-02T08:07:58 ... 2019-12-2...
* y (y) float64 8kB -2.243e+06 -2.243e+06 ... -2.252e+06 -2.252e+06
* x (x) float64 6kB 2.968e+06 2.968e+06 ... 2.976e+06 2.976e+06
spatial_ref int32 4B 6933
Data variables:
red_edge_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
red (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
green (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
blue (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
nir_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
swir_1 (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
MNDWI (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
NDCI (time, y, x) float32 229MB dask.array<chunksize=(1, 973, 773), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refBuild summary plot
To get an understanding of how the waterbody has changed over time, the following section builds a plot that uses the MNDWI to measure the rough area of the waterbody, along with the NDCI to track how the concentration of clorophyll-a is changing over time. This could be used to quickly assess the status of a given waterbody.
Set up constants
The number of pixels classified as water (MNDWI > 0) can be used as a proxy for the area of the waterbody if the pixel area is known. Run the following cell to generate the necessary constants for performing this conversion.
[12]:
# Constants for calculating waterbody area
pixel_length = query["resolution"][1] # in metres
m_per_km = 1000 # conversion from metres to kilometres
area_per_pixel = pixel_length**2 / m_per_km**2
Compute the total water area
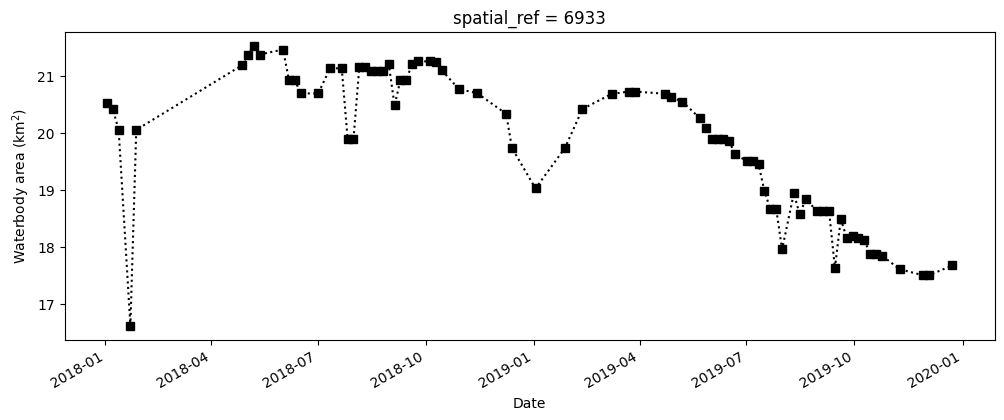
The next cell starts by filtering the data set to only keep the pixels that are classified as water. It then calculates the water area by counting all of the MNDWI pixels in the filtered data set, calculating a rolling median (this helps smooth the results to account for variation from cloud-masking), then multiplies this median count by the area-per-pixel.
Note: We recommend opening the Dask processing window to view the different computations that are being executed; to do this, see the Dask dashboard in DE Africa section of the Dask notebook.
[13]:
# Filter the data to contain only pixels classified as water
ds_waterarea = ds.where(ds.MNDWI > 0.0)
# Ensure time chunk is valid for rolling
ds_waterarea = ds_waterarea.chunk({"time": -1}).persist()
# Calculate the total water area (in km^2)
waterarea = (
ds_waterarea.MNDWI.count(dim=["x", "y"])
.rolling(time=3, center=True, min_periods=1)
.median(skipna=True)
* area_per_pixel
).persist()
# Plot the resulting water area through time
fig, axes = plt.subplots(1, 1, figsize=(12, 4))
waterarea.plot(linestyle=":", marker="s", color="k")
axes.set_xlabel("Date")
axes.set_ylabel("Waterbody area (km$^2$)")
plt.show()
Compute the average NDCI
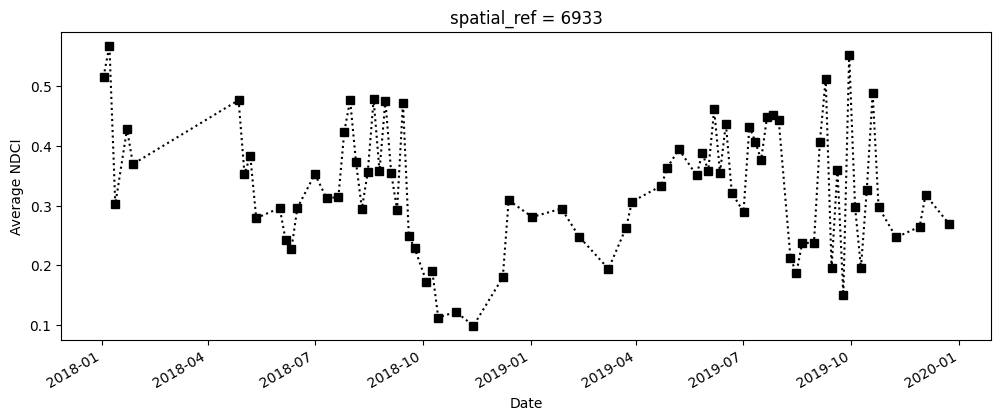
The next cell computes the average NDCI for each time step using the filtered data set. This means that we’re only tracking the NDCI in waterbody areas, and not on any land. To make the summary plot, we calculate NDCI across all pixels; this allows us to track overall changes in NDCI, but doesn’t tell us where the increase occured within the waterbody (this is covered in the next section).
Note: We recommend opening the Dask processing window to view the different computations that are being executed; to do this, see the Dask dashboard in DE Africa section of the Dask notebook.
[14]:
# Calculate the average NDCI
average_ndci = ds_waterarea.NDCI.mean(dim=["x", "y"], skipna=True).persist()
# Plot average NDCI through time
fig, axes = plt.subplots(1, 1, figsize=(12, 4))
average_ndci.plot(linestyle=":", marker="s", color="k")
axes.set_xlabel("Date")
axes.set_ylabel("Average NDCI")
plt.show()
Combine the data to build the summary plot
The cell below combines the total water area and average NDCI time series we generated above into a single summary plot. Notice that Python can be used to build highly-customised plots. If you’re interested, take some time to understand how the plot is built. Otherwise, run the cell to build the plot.
Note: The colour map used below is normalised so that the maximum
NDCIvalue is 0.5, which is thought to correspond to a severe algal bloom event (Mishra and Mishra 2012). The minimumNDCIvalue of -0.1 corresponds to low conentrations of chlorophyll-a. This makes it more straightforward to identify severe algal bloom events in the plot.
[15]:
# Set up the figure
fig, axes = plt.subplots(1, 1, figsize=(12, 4))
# Set the colour map to use and the normalisation. NDCI is plotted on a scale
# of -0.1 to 0.5 so the colour map is normalised to these values
min_ndci_scale = -0.1
max_ndci_scale = 0.5
cmap = plt.get_cmap("cividis")
normal = plt.Normalize(vmin=min_ndci_scale, vmax=max_ndci_scale)
# Store the dates from the data set as numbers for ease of plotting
dates = matplotlib.dates.date2num(ds_waterarea.time.values)
# Add the basic plot to the figure
# This is just a line showing the area of the waterbody over time
axes.plot_date(x=dates, y=waterarea, color="black", linestyle="-", marker="")
# Fill in the plot by looping over the possible threshold values and filling
# the areas that are greater than the threshold
color_vals = np.linspace(0, 1, 100)
threshold_vals = np.linspace(min_ndci_scale, max_ndci_scale, 100)
for ii, thresh in enumerate(threshold_vals):
im = axes.fill_between(dates,
0,
waterarea,
where=(average_ndci >= thresh),
norm=normal,
facecolor=cmap(color_vals[ii]),
alpha=1)
# Add the colour bar to the plot
cax, _ = matplotlib.colorbar.make_axes(axes)
cb2 = matplotlib.colorbar.ColorbarBase(cax, cmap=cmap, norm=normal)
cb2.set_label("NDCI")
# Add titles and labels to the plot
axes.set_xlabel("Date")
axes.set_ylabel("Waterbody area (km$^2$)")
plt.show()
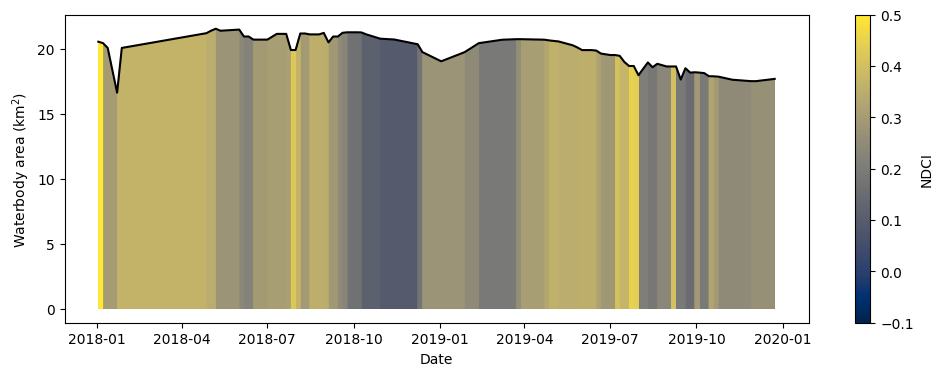
What does the plot reveal about the waterbody? Are there periods that show high NDCI values?
Compare spatial NDCI at two different dates
While the summary plot is useful at a glance it can be interesting to see the full spatial picture at times where the NDCI is low vs. high. The code below defines two useful functions: closest_date will find the date in a list of dates closest to any given date; date_index will return the position of a particular date in a list of dates. These functions are useful for selecting images to compare.
[16]:
def closest_date(list_of_dates, desired_date):
return min(list_of_dates,
key=lambda x: abs(x - np.datetime64(desired_date)))
def date_index(list_of_dates, known_date):
return (np.where(list_of_dates == known_date)[0][0])
Run the cell below to set two dates to compare. Feel free to change the dates to look at the NDCI of the waterbody at different times.
[17]:
# Set the dates to view
date_1 = "2018-10-15"
date_2 = "2018-12-15"
# Compute the closest date available from the data set
closest_date_1 = closest_date(ds.time.values, date_1)
closest_date_2 = closest_date(ds.time.values, date_2)
# Make an xarray containing the closest dates, which is used to select
# the dates from the data set
time_xr = xr.DataArray([closest_date_1, closest_date_2], dims=["time"])
# Plot the NDCI values for pixels classified as water for the two dates.
ds_waterarea.NDCI.sel(time=time_xr).plot.imshow(x="x",
y="y",
col="time",
cmap=cmap,
vmin=min_ndci_scale,
vmax=max_ndci_scale,
col_wrap=2,
robust=True,
figsize=(12, 6))
plt.show()
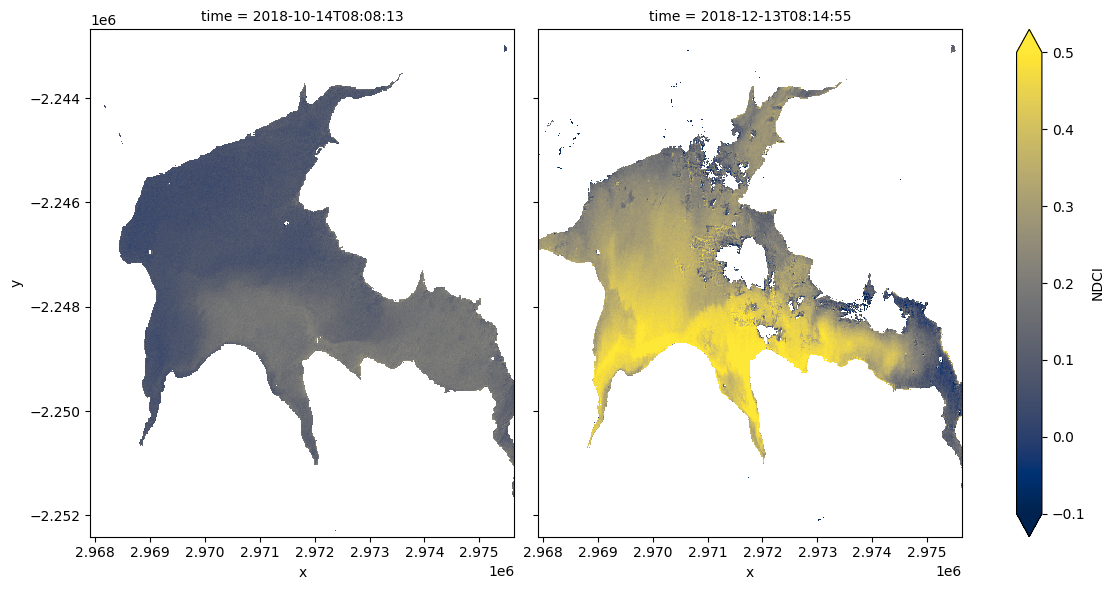
Run the cell below to see the true-colour images for the same dates
[18]:
# Compute the index of the closest dates
closest_date_1_idx = date_index(ds.time.values, closest_date_1)
closest_date_2_idx = date_index(ds.time.values, closest_date_2)
# Make the true colour plots for the closest dates
rgb(ds, index=[closest_date_1_idx, closest_date_2_idx],
percentile_stretch=[0.02, 0.95])
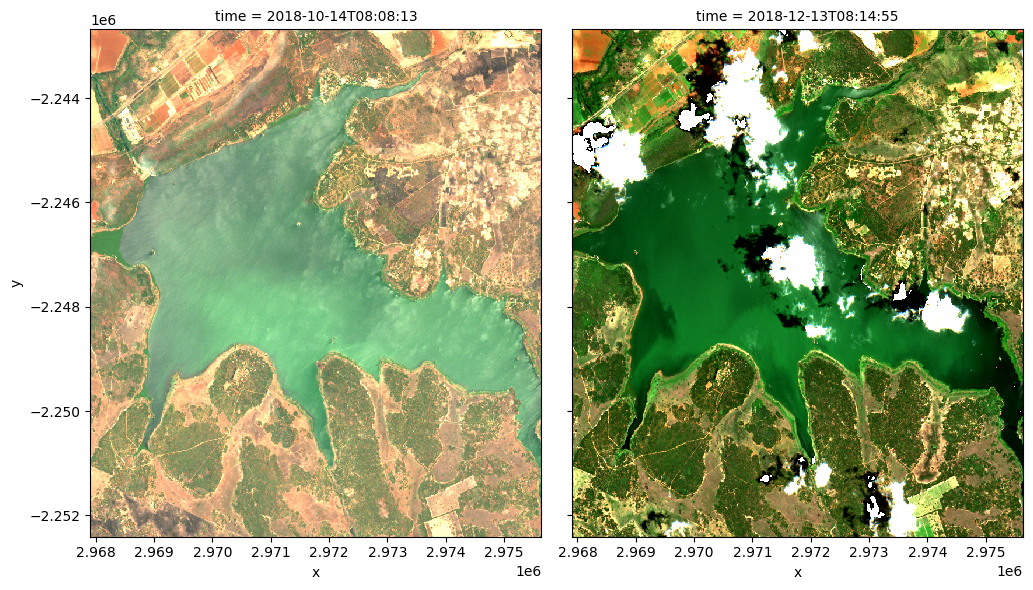
Drawing conclusions
Here are some questions to think about:
How well do increased NDCI values match with what you see in the true-colour images?
When would it be more helpful to use the summary plot vs. the time comparison plot and vice-versa?
What does the water look like in the true-colour image when the NDCI is low-to-medium vs. high?
What other information might you seek if you detected an abnormally high NDCI value?
Next steps
When you are done, return to the “Analysis parameters” section, modify some values (e.g. lat, lon or time) and rerun the analysis. You can use the interactive map in the “View the selected location” section to find new central latitude and longitude values by panning and zooming, and then clicking on the area you wish to extract location values for. You can also use Google maps to search for a location you know, then return the latitude and longitude values by clicking the map.
If you’re going to change the location, you’ll need to make sure Sentinel-2 data is available for the new location, which you can check at the DEAfrica Explorer. Use the drop-down menu to check s2a_l2a coverage.
If you want to look at Weija Reservoir, try the following coordinates over the same time period as the original example:
lat = 5.577
lon = -0.362
Additional information
License The code in this notebook is licensed under the Apache License, Version 2.0.
Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact If you need assistance, please post a question on the DE Africa Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here).
If you would like to report an issue with this notebook, you can file one on Github.
Compatible datacube version
[19]:
print(datacube.__version__)
1.9.13
Last Tested:
[20]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[20]:
'2026-04-13'