Forecasting cropland vegetation condition
Keywords data used; sentinel 2, data used; crop_mask, :index: data methods; forecasting, :index: data methods; autoregression
Background
This notebook conducts time-series forecasting of vegetation condition (NDVI) using SARIMAX, a variation on autoregressive-moving-average (ARMA) models which includes an integrated (I) component to difference the timeseries so it becomes stationary, a seasonal (S) component, and has the capacity to consider exogenous (X) variables.
In this example, we will conduct a forecast on a univariate NDVI timeseries. That is, our forecast will be built on temporal patterns in NDVI. Conversely, multivariate approaches can account for influences of variables such as soil moisture and rainfall.
Description
In this notebook, we generate a NDVI timeseries from Sentinel-2, then use it develop a forecasting algorithm.
The following steps are taken:
Load Sentinel-2 data and calculate NDVI.
Mask NDVI to cropland using the crop mask.
Iterate through SARIMAX parameters and conduct model selection based on cross-validation.
Inspect model diagnostics
Forecast NDVI into the future and visualise the result.
Load packages
Import Python packages that are used for the analysis.
Important note: Scipy has updated and has some incompatibilities with old versions of statsmodels. If the loading packages cell below returns an error, try running pip install statsmodels or pip install statsmodels --upgrade in a code cell, then load the packages again.
[1]:
%matplotlib inline
from itertools import product
import datacube
import numpy as np
import pandas as pd
import geopandas as gpd
import statsmodels.api as sm
import xarray as xr
from datacube import Datacube
from odc.geo.geom import Geometry
from deafrica_tools.spatial import xr_rasterize
from deafrica_tools.bandindices import calculate_indices
from deafrica_tools.dask import create_local_dask_cluster
from deafrica_tools.datahandling import load_ard
from deafrica_tools.plotting import display_map
from matplotlib import pyplot as plt
from statsmodels.tools.eval_measures import rmse
from tqdm.notebook import tqdm
from deafrica_tools.areaofinterest import define_area
Set up a Dask cluster
Dask can be used to better manage memory use down and conduct the analysis in parallel. For an introduction to using Dask with Digital Earth Africa, see the Dask notebook.
Note: We recommend opening the Dask processing window to view the different computations that are being executed; to do this, see the Dask dashboard in DE Africa section of the Dask notebook.
To use Dask, set up the local computing cluster using the cell below.
[2]:
create_local_dask_cluster()
/opt/venv/lib/python3.12/site-packages/distributed/node.py:187: UserWarning: Port 8787 is already in use.
Perhaps you already have a cluster running?
Hosting the HTTP server on port 36459 instead
warnings.warn(
Client
Client-d59ed3b7-d44a-11ef-a9ee-1e01ca941b00
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /user/victoria@kartoza.com/proxy/36459/status |
Cluster Info
LocalCluster
01a14b58
| Dashboard: /user/victoria@kartoza.com/proxy/36459/status | Workers: 1 |
| Total threads: 7 | Total memory: 59.21 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-931a3ae0-a1cb-4fca-b6ff-760875560357
| Comm: tcp://127.0.0.1:35489 | Workers: 1 |
| Dashboard: /user/victoria@kartoza.com/proxy/36459/status | Total threads: 7 |
| Started: Just now | Total memory: 59.21 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:44715 | Total threads: 7 |
| Dashboard: /user/victoria@kartoza.com/proxy/38151/status | Memory: 59.21 GiB |
| Nanny: tcp://127.0.0.1:38883 | |
| Local directory: /tmp/dask-scratch-space/worker-twr95w88 | |
Connect to the datacube
[3]:
dc = datacube.Datacube(app="NDVI_forecast")
Analysis parameters
lat,lon: The central latitude and longitude to analyse. In this example we’ll use an agricultural area in Ethiopia.buffer: The number of square degrees to load around the central latitude and longitude. For reasonable loading times, set this as 0.1 or lower.products: The satellite data to load, in the example we will use Sentinel-2.time_range: The date range to analyse. The longer the date-range, the more data the model has to derive patterns in the NDVI timeseries.freq: The frequency we want to resample the time-series to e.g. for monthly time steps use'1M', for fortinightly use'2W'.forecast_length: The length of time beyond the latest observation in the dataset that we want the model to forecast, expressed in units of resample frequencyfreq. A longerforecast_lengthmeans greater forecast uncertainty.resolution: The pixel resolution (in metres) to use for loading Sentinel-2 data.dask_chunks: How to chunk the datasets to work with dask.
Select location
To define the area of interest, there are two methods available:
By specifying the latitude, longitude, and buffer. This method requires you to input the central latitude, central longitude, and the buffer value in square degrees around the center point you want to analyze. For example,
lat = 10.338,lon = -1.055, andbuffer = 0.1will select an area with a radius of 0.1 square degrees around the point with coordinates (10.338, -1.055).Alternatively, you can provide separate buffer values for latitude and longitude for a rectangular area. For example,
lat = 10.338,lon = -1.055, andlat_buffer = 0.1andlon_buffer = 0.08will select a rectangular area extending 0.1 degrees north and south, and 0.08 degrees east and west from the point(10.338, -1.055).For reasonable loading times, set the buffer as
0.1or lower.By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
To use one of these methods, you can uncomment the relevant line of code and comment out the other one. To comment out a line, add the "#" symbol before the code you want to comment out. By default, the first option which defines the location using latitude, longitude, and buffer is being used.
[4]:
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=8.5593, lon=40.6975, buffer=0.04)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
#aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
[5]:
# the satellite product to load
products = "s2_l2a"
# Define the time window for defining the model
time_range = ("2017-01-01", "2022-01")
# resample frequency
freq = "1ME"
# number of time-steps to forecast (in units of `freq`)
forecast_length = 6
# resolution of Sentinel-2 pixels
resolution = (-20, 20)
# dask chunk sizes
dask_chunks = {"x": 500, "y": 500, "time": -1}
Display analysis area on an interactive map
[6]:
display_map(lon_range, lat_range)
[6]:
Load the satellite data
Using the parameters we defined above.
[7]:
# set up a datcube query object
query = {
"x": lon_range,
"y": lat_range,
"time": time_range,
"measurements": ["red", "nir"],
"output_crs": "EPSG:6933",
"resolution": resolution,
"resampling": {"fmask": "nearest", "*": "bilinear"},
}
[8]:
# load the satellite data
ds = load_ard(dc=dc, dask_chunks=dask_chunks, products=products, **query)
print(ds)
Using pixel quality parameters for Sentinel 2
Finding datasets
s2_l2a
Applying pixel quality/cloud mask
Returning 767 time steps as a dask array
<xarray.Dataset> Size: 1GB
Dimensions: (time: 767, y: 505, x: 387)
Coordinates:
* time (time) datetime64[ns] 6kB 2017-01-06T07:42:19 ... 2022-01-30...
* y (y) float64 4kB 1.093e+06 1.093e+06 ... 1.083e+06 1.083e+06
* x (x) float64 3kB 3.923e+06 3.923e+06 ... 3.931e+06 3.931e+06
spatial_ref int32 4B 6933
Data variables:
red (time, y, x) float32 600MB dask.array<chunksize=(767, 500, 387), meta=np.ndarray>
nir (time, y, x) float32 600MB dask.array<chunksize=(767, 500, 387), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
[9]:
ds
[9]:
<xarray.Dataset> Size: 1GB
Dimensions: (time: 767, y: 505, x: 387)
Coordinates:
* time (time) datetime64[ns] 6kB 2017-01-06T07:42:19 ... 2022-01-30...
* y (y) float64 4kB 1.093e+06 1.093e+06 ... 1.083e+06 1.083e+06
* x (x) float64 3kB 3.923e+06 3.923e+06 ... 3.931e+06 3.931e+06
spatial_ref int32 4B 6933
Data variables:
red (time, y, x) float32 600MB dask.array<chunksize=(767, 500, 387), meta=np.ndarray>
nir (time, y, x) float32 600MB dask.array<chunksize=(767, 500, 387), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refMask region with DE Africa’s cropland extent map
Load the cropland mask over the region of interest. The default region we’re analysing is in Ethiopia, so we need to load either the crop_mask product which covers the entire African continent, or the crop_mask_eastern product, which cover the countries of Ethiopia, Kenya, Tanzania, Rwanda, and Burundi. If you change the analysis region from the default one, you may need to load a different crop mask - see the docs page to find out more.
[10]:
cm = dc.load(
product="crop_mask",
time=("2019"),
measurements="filtered",
resampling="nearest",
like=ds.geobox,
).filtered.squeeze()
# convert the missing values (255) to NaN
cm = cm.where(cm != 255)
cm.plot.imshow(add_colorbar=False, figsize=(6, 6))
plt.title("Cropland Extent");
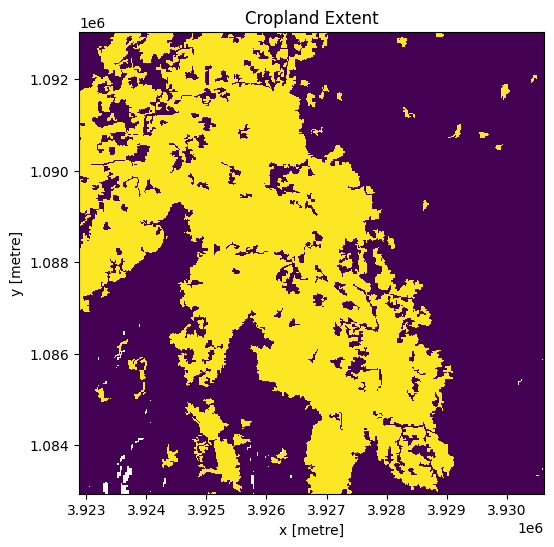
Now we will use the cropland map to mask the regions in the Sentinel-2 data that only have cropping.
[11]:
ds = ds.where(cm == 1)
Clip the datasets to the shape of the area of interest
A geopolygon represents the bounds and not the actual shape because it is designed to represent the extent of the geographic feature being mapped, rather than the exact shape. In other words, the geopolygon is used to define the outer boundary of the area of interest, rather than the internal features and characteristics.
Clipping the data to the exact shape of the area of interest is important because it helps ensure that the data being used is relevant to the specific study area of interest. While a geopolygon provides information about the boundary of the geographic feature being represented, it does not necessarily reflect the exact shape or extent of the area of interest.
[12]:
#Rasterise the area of interest polygon
aoi_raster = xr_rasterize(gdf=geopolygon_gdf, da=ds, crs=ds.crs)
#Mask the dataset to the rasterised area of interest
ds = ds.where(aoi_raster == 1)
Calculate NDVI and clean the time-series
After calculating NDVI, we will smooth and interpolate the data to ensure we are working with a consistent time-series. This is a very important step in the workflow and there are many ways to smooth, interpolate, gap-fill, remove outliers, or curve-fit the data to ensure a consistent time-series. If not using the default example, you may have to define additional methods to those used here.
To do this we take two steps:
Resample the data to monthly time-steps using the mean
Calculate a rolling mean with a window of 4 steps
[13]:
# calculate NDVI
ndvi = calculate_indices(ds, "NDVI", drop=True, satellite_mission="s2")
Dropping bands ['red', 'nir']
[14]:
# resample and smooth
window = 4
ndvi = (
ndvi.resample(time=freq)
.mean()
.rolling(time=window, min_periods=1, center=True)
.mean()
)
Reduce the time-series to one dimension
In this example, we’re generating a forecast on a simple 1D timeseries. This time-series represents the spatially averaged NDVI at each time-step in the series.
In this step, all the calculations above are triggered and the dataset is brought into memory so this step can take a few minutes to complete.
[15]:
ndvi = ndvi.mean(["x", "y"])
ndvi = ndvi.NDVI.compute()
/opt/venv/lib/python3.12/site-packages/rasterio/warp.py:387: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix will be returned.
dest = _reproject(
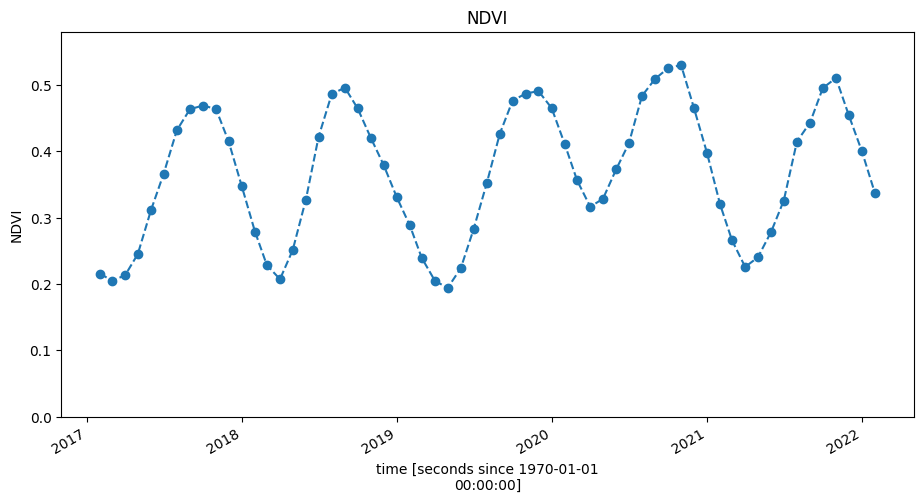
Plot the NDVI timeseries
[16]:
ndvi.plot(figsize=(11, 5), linestyle="dashed", marker="o")
plt.title("NDVI")
plt.ylim(0, ndvi.max().values + 0.05);
Split data and fit a model
Cross-validation is a common method for evaluating model performance. It involves dividing data into a training set on which the model is trained, and test (or validation) set, to which the model is applied to produce predictions which are compared against actual values (that weren’t used in model training).
[17]:
ndvi = ndvi.drop_vars("spatial_ref").to_dataframe()
train_data = ndvi["NDVI"][
: len(ndvi) - 10
] # remove the last ten observations and keep them as test data
test_data = ndvi["NDVI"][len(ndvi) - 10 :]
Iteratively find the best parameters for the SARIMAX model
SARIMAX models are fitted with parameters for both the trend and seasonal components of the timeseries. The parameters can be defined as:
Trend elements
p: Autoregression order. This is the number of immediately preceding values in the series that are used to predict the value at the present time.
d: Difference order. The number of times that differencing is performed is called the difference order.
q: Moving average order. The size of the moving average window.
Seasonal elements are as above, but for the seasonal component of the timeseries.
P
D
Q
We also need to define the length of season.
s: In this case we use 6, which is in units of resample frequency so refers to 6 months.
In the cell below, initial values and a range are given for the parameters above. Using range(0, 3) means the values 0, 1, and 2 are iterated through for each of p, d, q and P, D, Q. This means that there are \(3^2 \times 3^2 = 81\) possible combinations.
[18]:
# Set initial values and some bounds
p = range(0, 3)
d = 1
q = range(0, 3)
P = range(0, 3)
D = 1
Q = range(0, 3)
s = 6
# Create a list with all possible combinations of parameters
parameters = product(p, q, P, Q)
parameters_list = list(parameters)
print("Number of iterations to run:", len(parameters_list))
# Train many SARIMA models to find the best set of parameters
def optimize_SARIMA(parameters_list, d, D, s):
"""
Return an ordered (ascending RMSE) dataframe with parameters,
corresponding AIC, and RMSE.
parameters_list - list with (p, q, P, Q) tuples
d - integration order
D - seasonal integration order
s - length of season
"""
results = []
best_aic = float("inf")
for param in tqdm(parameters_list):
try:
import warnings
warnings.filterwarnings("ignore")
model = sm.tsa.statespace.SARIMAX(
train_data,
order=(param[0], d, param[1]),
seasonal_order=(param[2], D, param[3], s),
).fit(disp=-1)
pred = model.predict(start=len(train_data), end=(len(ndvi) - 1))
error = rmse(pred, test_data)
except:
continue
aic = model.aic
# Save best model, AIC and parameters
if aic < best_aic:
best_model = model
best_aic = aic
best_param = param
results.append([param, model.aic, error])
result_table = pd.DataFrame(results)
result_table.columns = ["parameters", "aic", "error"]
# Sort in ascending order, lower AIC is better
result_table = result_table.sort_values(by="error", ascending=True).reset_index(
drop=True
)
return result_table
Number of iterations to run: 81
Now will will run the function above for every iteration of parameters we have defined. Depending on the number of iterations, this can take a few minutes to run. A progress bar is printed below.
[19]:
# run the function above
result_table = optimize_SARIMA(parameters_list, d, D, s)
Model selection
The root-mean-square error (RMSE) is a common metric used to evaluate model or forecast performance. It is the standard deviation of residuals (difference between forecast and actual value) expressed in units of the variable of interest e.g. NDVI. We can calculate RMSE of our forecast because we withheld some observations as test or validation data.
We can also use either the Akaike information criterion (AIC) or Bayesian information criterion (BIC) for model selection. Both these criteria aim to optimise the trade-off between goodness of fit and model simplicity. We are aiming to find the model that can explain the most variation in the timeseries with the least complexity, as added complexity may lead to overfitting. The BIC penalises additional parameters (greater complexity) more than the AIC.
There are different schools of thought on which criterion to use. A general rule of thumb is that the BIC should be used for inference and interpretation whereas the AIC should be used for prediction. As our goal is prediction (forecasting), we could select the model with the lowest AIC, though this approach is often reserved for when there is no test data available for cross-validation.
The cell below presents the top 15 models based on AIC and the RMSE on the cross-validation.
[20]:
# Sort table by the lowest AIC (Akaike Information Criteria) where the RMSE is low
result_table = result_table.sort_values("aic").sort_values("error")
print(result_table[0:15])
parameters aic error
0 (0, 0, 2, 2) -165.970990 0.017479
1 (2, 2, 0, 1) -204.185850 0.018467
2 (0, 0, 1, 2) -167.675022 0.018694
3 (0, 0, 2, 1) -161.886928 0.019422
4 (0, 1, 1, 1) -185.405325 0.019897
5 (2, 2, 0, 2) -203.090273 0.020219
6 (0, 1, 2, 1) -184.014951 0.020868
7 (2, 2, 2, 2) -198.923767 0.021366
8 (0, 1, 2, 2) -186.460473 0.021840
9 (0, 1, 1, 2) -187.612900 0.023772
10 (2, 1, 1, 2) -198.057996 0.023991
11 (0, 0, 1, 1) -162.146544 0.024082
12 (1, 2, 1, 1) -188.602968 0.027498
13 (2, 1, 1, 1) -190.683099 0.027887
14 (2, 2, 1, 2) -199.563266 0.030304
Select model and predict
In the cell below. We wil select a model from the list above. In this case we’ve selected model 0 as it has the lowest RMSE, though you can select any model by setting the index number in the cell below using the model_sel_index parameter.
[21]:
# selected model
model_sel_index = 0
# store parameters from selected model
p, q, P, Q = result_table.iloc[model_sel_index].parameters
print(result_table.iloc[model_sel_index])
# fit the model with the parameters identified above
best_model = sm.tsa.statespace.SARIMAX(
train_data, order=(p, d, q), seasonal_order=(P, D, Q, s)
).fit(disp=-1)
parameters (0, 0, 2, 2)
aic -165.97099
error 0.017479
Name: 0, dtype: object
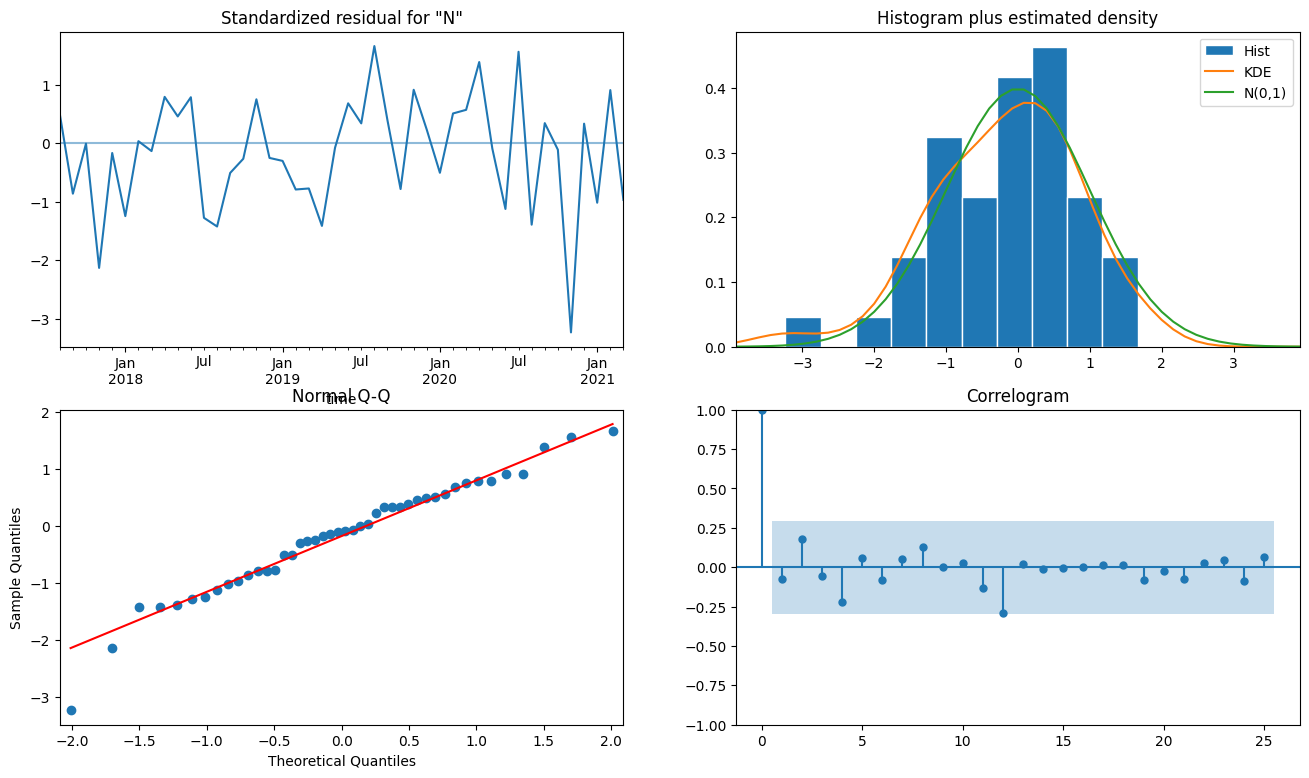
Plot model diagnostics
There are some typical plots we can use to evaluate our model.
Standardised residuals (top-left) The standardised residuals are plotted against x (time) values. This allows us to check that variance (distance of residuals from 0) is constant across time values. There should be no obvious patterns.
Histogram and estimated density (top-right) A kernel density estimation (KDE) is an estimated probability density function fitted on the actual distribution (histogram) of standardised residuals. A normal distribution (N (0,1)) is shown for reference. This plot shows that the distribution of our standardised residuals is close to normally distributed.
Normal quantile-quantile (Q-Q) plot (bottom-left) This plot shows ‘expected’ or ‘theoretical’ quantiles drawn from a normal distribution on the x-axis against quantiles taken from the sample of residuals on the y-axis. If the observations in blue match the 1:1 line in red, then we can conclude that our residuals are normally distributed.
Correlogram (bottom-right) The correlations for lags greater than 0 should not be statistically significant. That is, they should not be outside the blue ribbon.
Note: The Q-Q plot and correlogram generated for model
0show there is some pattern in the residuals. That is, there is remaining variation in the data which the model has not accounted for. You could experiment with different parameter values or model selection in the prior steps to see if this can be addressed.
[22]:
fig = plt.figure(figsize=(16, 9))
fig = best_model.plot_diagnostics(lags=25, fig=fig)
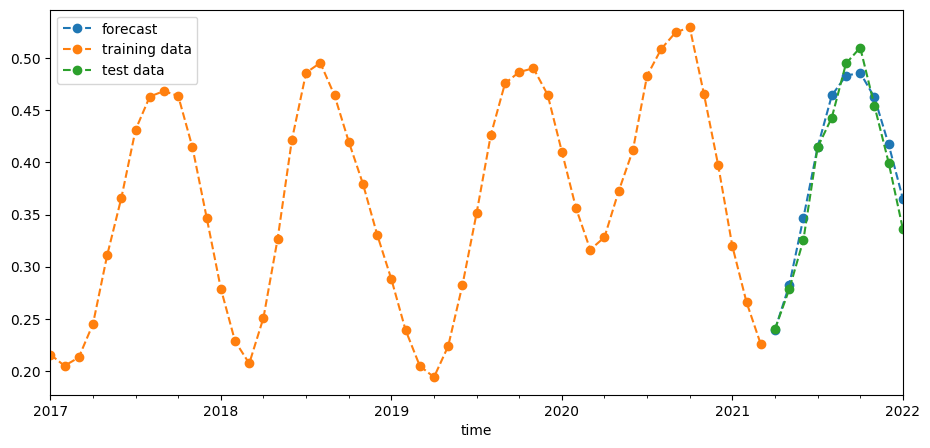
Backtest forecast
We saved the last 10 observations as test data above. Now we can use our model to predict NDVI for those time-steps and compare those predictions with actual values. We can do this visually in the graph below and also quantify the error with the root-mean-square error (RMSE).
[23]:
pred = best_model.predict(start=len(train_data), end=(len(ndvi) - 1))
plt.figure(figsize=(11, 5))
pred.plot(label="forecast", linestyle="dashed", marker="o")
train_data.plot(label="training data", linestyle="dashed", marker="o")
test_data.plot(label="test data", linestyle="dashed", marker="o")
plt.legend(loc="upper left");
Plot the result of our forecast
To forecast NDVI into the future, we’ll run a model on the entire time series so we can include the latest observations. We can see that the forecast uncertainty, expressed as the 95% confidence interval, increases with time.
[24]:
final_model = sm.tsa.statespace.SARIMAX(
ndvi, order=(p, d, q), seasonal_order=(P, D, Q, s)
).fit(disp=-1)
yhat = final_model.get_forecast(forecast_length);
[25]:
fig, ax = plt.subplots(1, 1, figsize=(11, 5))
yhat.predicted_mean.plot(label="NDVI forecast", ax=ax, linestyle="dashed", marker="o")
ax.fill_between(
yhat.predicted_mean.index,
yhat.conf_int()["lower NDVI"],
yhat.conf_int()["upper NDVI"],
alpha=0.2,
)
ndvi[-36:].plot(label="Observaions", ax=ax, linestyle="dashed", marker="o")
plt.legend(loc="upper left");
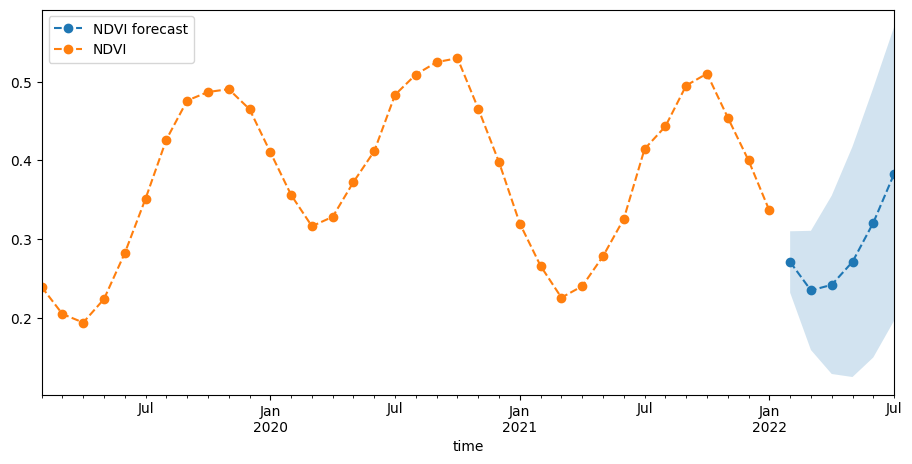
Our forecast looks reasonable in the context of the timeseries above.
Additional information
License The code in this notebook is licensed under the Apache License, Version 2.0.
Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact If you need assistance, please post a question on the DE Africa Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here).
If you would like to report an issue with this notebook, you can file one on Github.
Compatible datacube version
[26]:
print(datacube.__version__)
1.8.20
Last Tested:
[27]:
from datetime import datetime
datetime.today().strftime("%Y-%m-%d")
[27]:
'2025-01-16'