Analyse en composantes principales pour les données multispectrales
Produits utilisés : s2_l2a
Mots-clés données utilisées; sentinel-2, analyse; analyse en composantes principales
Aperçu
L’analyse en composantes principales (ACP) est une technique courante de réduction de la dimensionnalité. Elle peut être utilisée pour explorer des modèles dans des données de grande dimension et faciliter l’apprentissage non supervisé.
Les composantes principales sont une série de combinaisons linéaires des variables d’origine, parmi lesquelles la première composante principale représente la plus grande variance au sein d’un ensemble de données. Chaque composante principale suivante représente la variance la plus grande possible et n’est pas corrélée aux composantes précédemment définies.
Cette technique est utile pour comprendre les données Sentinel-2 car les images sont capturées dans 12 bandes spectrales mais seules 3 variables peuvent être visualisées dans une composition RVB. L’ACP peut également être appliquée aux données de séries chronologiques pour étudier les modèles d’évolution temporelle de différents types de couverture terrestre.
Description
Ce cahier présente une analyse en composantes principales pour les données multispectrales Sentinel-2. Les étapes suivantes sont abordées :
Chargement des données multispectrales Sentinel-2.
Application de l’ACP pour transformer et visualiser les données. ***
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Charger des paquets
Importez les packages Python utilisés pour l’analyse.
[1]:
%matplotlib inline
from sklearn.decomposition import PCA
import datacube
import geopandas as gpd
from odc.geo.geom import Geometry
from deafrica_tools.datahandling import load_ard
from deafrica_tools.plotting import rgb
from deafrica_tools.classification import sklearn_flatten, sklearn_unflatten
from deafrica_tools.areaofinterest import define_area
Se connecter au datacube
Connectez-vous au datacube pour que nous puissions accéder aux données de DEAfrica.
[2]:
dc = datacube.Datacube(app='pca')
Paramètres d’analyse
La cellule suivante définit les paramètres qui définissent la zone d’intérêt et la durée de l’analyse. Les paramètres sont
« lat » : la latitude centrale à analyser (par exemple « 6,502 »).
« lon » : la longitude centrale à analyser (par exemple « -1,409 »).
« buffer » : le nombre de degrés carrés à charger autour de la latitude et de la longitude centrales. Pour des temps de chargement raisonnables, définissez cette valeur sur « 0,1 » ou moins.
time: la plage de dates à analyser (par exemple("2017-08-01", "2019-11-01")). Pour des temps de chargement raisonnables, assurez-vous que la plage s’étend sur moins de 3 ans.Plage acceptable de pourcentage de couverture nuageuse pour le granule d’entrée Sentinel-2 (
min_gooddata)Bandes spectrales à explorer
Sélectionnez l’emplacement
Pour définir la zone d’intérêt, deux méthodes sont disponibles :
En spécifiant la latitude, la longitude et la zone tampon. Cette méthode nécessite que vous saisissiez la latitude centrale, la longitude centrale et la valeur de la zone tampon en degrés carrés autour du point central que vous souhaitez analyser. Par exemple, « lat = 10,338 », « lon = -1,055 » et « buffer = 0,1 » sélectionneront une zone avec un rayon de 0,1 degré carré autour du point avec les coordonnées (10,338, -1,055).
By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
Pour utiliser l’une de ces méthodes, vous pouvez décommenter la ligne de code concernée et commenter l’autre. Pour commenter une ligne, ajoutez le symbole "#" avant le code que vous souhaitez commenter. Par défaut, la première option qui définit l’emplacement à l’aide de la latitude, de la longitude et du tampon est utilisée.
Si vous exécutez le bloc-notes pour la première fois, conservez les paramètres par défaut ci-dessous. Cela vous montrera comment fonctionne l’analyse et fournira des résultats significatifs. L’emplacement par défaut est l’estuaire de Betsiboka, à Madagascar.
[3]:
# Set the area of interest
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=-15.92, lon=46.35, buffer=0.1)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
# aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
query = {
'time': ('2020-01', '2020-03'),
'x': lon_range,
'y': lat_range,
'output_crs': 'epsg:6933',
'resolution':(-20,20),
}
# use all non-overlapping 10m and 20m bands
bands = ['blue', 'green', 'red', 'red_edge_1', 'red_edge_2',
'red_edge_3', 'nir_narrow', 'swir_1', 'swir_2']
Chargement des données multispectrales Sentinel-2
Seuls les nuages à forte probabilité sont exclus dans cet exemple, mais cela peut être modifié pour une zone différente.
[4]:
ds = load_ard(dc=dc,
products=['s2_l2a'],
measurements=bands,
min_gooddata=0.98,
group_by='solar_day',
**query)
Using pixel quality parameters for Sentinel 2
Finding datasets
s2_l2a
Counting good quality pixels for each time step
Filtering to 4 out of 18 time steps with at least 98.0% good quality pixels
Applying pixel quality/cloud mask
Loading 4 time steps
[5]:
# visualize data using selected input spectral bands
rgb(ds, bands=['swir_1','nir_narrow','red_edge_1'], index=list(range(len(ds.time))), col_wrap=4)
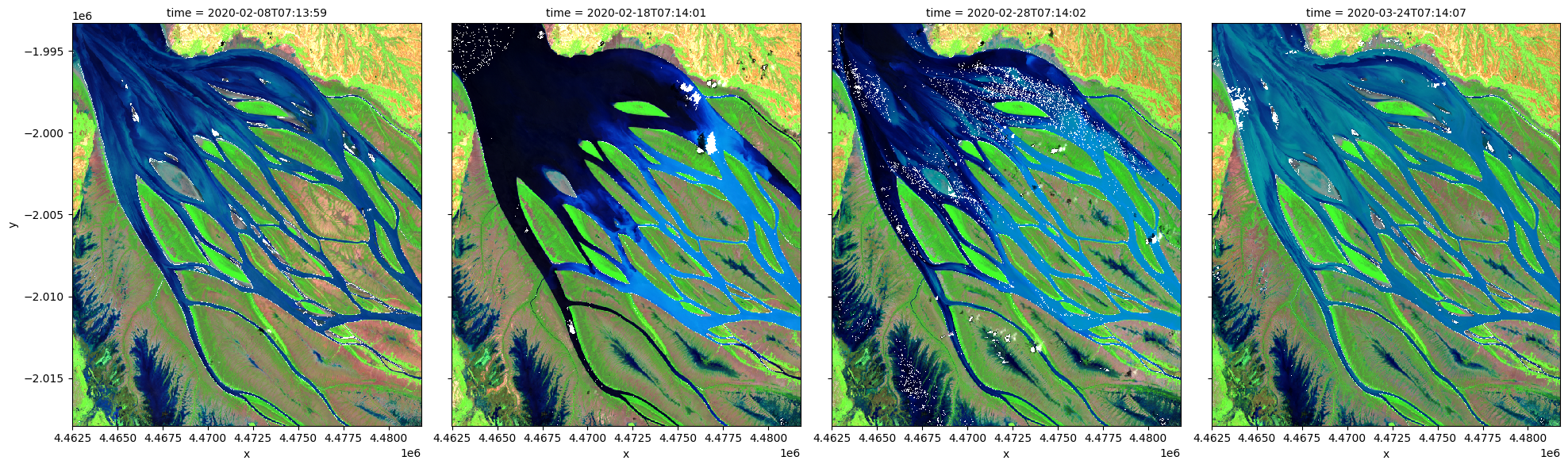
Application de l’ACP pour transformer et visualiser les données
Pour effectuer une PCA, les données sont d’abord transformées en un tableau numpy qui peut être utilisé par sklearn.
[6]:
X = sklearn_flatten(ds)
Un modèle PCA est généré avec 3 composantes principales et ajusté sur les données.
[7]:
pca = PCA(n_components=3)
pca.fit(X)
[7]:
PCA(n_components=3)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
PCA(n_components=3)
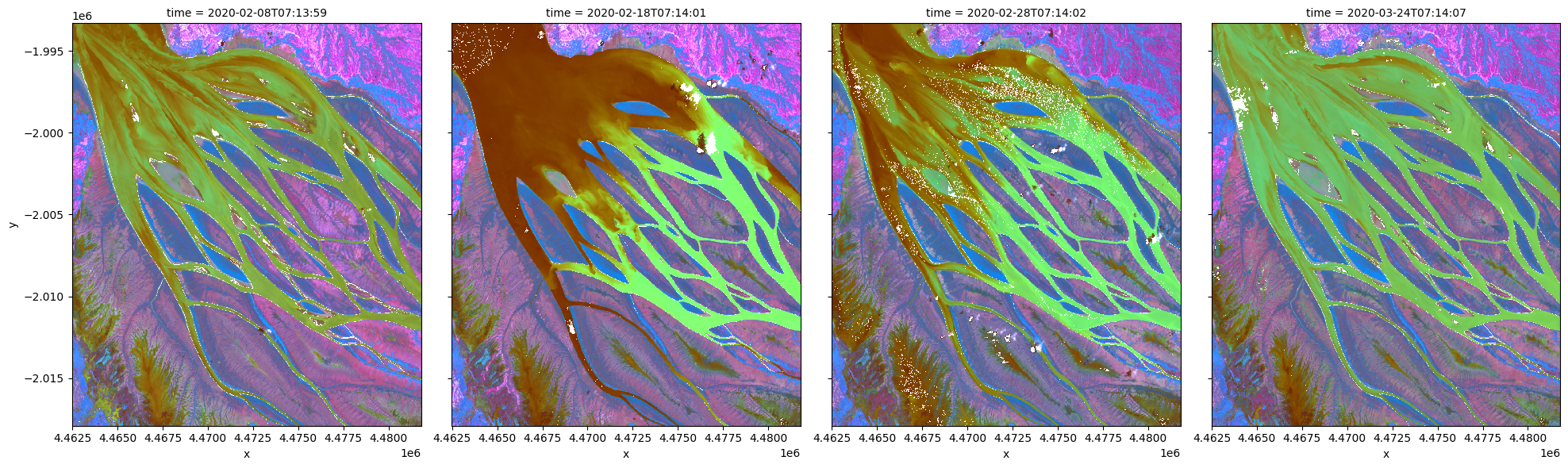
Nous pouvons examiner dans quelle mesure la variance est prise en compte dans chaque composante principale. Dans l’exemple par défaut, la première composante principale représente une variance beaucoup plus élevée que les deux suivantes.
Cette étape peut aider à déterminer si davantage de composants principaux sont nécessaires.
[8]:
print("Relative variance in principal components:", pca.explained_variance_ratio_)
Relative variance in principal components: [0.6299663 0.21186598 0.14486542]
Les données d’entrée peuvent désormais être transformées dans ce nouvel espace de référence et réorganisées dans un ensemble de données xarray compatible avec les données d’entrée.
[9]:
predict = pca.transform(X)
[10]:
out = sklearn_unflatten(predict, ds)
out = out.to_dataset(dim=out.dims[0]).transpose('time','y','x')
Visualiser les résultats de l’ACP
[11]:
rgb(out, bands=[2,1,0], index=list(range(len(out.time))), col_wrap=4)
Informations Complémentaires
Licence : Le code de ce carnet est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>. Les données de Digital Earth Africa sont sous licence Creative Commons par attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact : Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack Open Data Cube <http://slack.opendatacube.org/>`__ ou sur le GIS Stack Exchange en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment ici). Si vous souhaitez signaler un problème avec ce bloc-notes, vous pouvez en déposer un sur Github.
Version de Datacube compatible :
[12]:
print(datacube.__version__)
1.8.20
Dernier test :
[13]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[13]:
'2025-01-15'