Segmentation d’images
Produits utilisés : s2_l2a
Mots clés données utilisées ; sentinel-2, analyse ; apprentissage automatique, apprentissage automatique ; segmentation d’image, méthodes de données ; composites, analyse ; GEOBIA, indice de bande ; NDVI, format de données ; GeoTIFF
Aperçu
Au cours des deux dernières décennies, à mesure que la résolution spatiale des images satellite a augmenté, la télédétection a commencé à passer d’une analyse basée sur les pixels à une analyse d’images basée sur des objets géographiques (GEOBIA), qui vise à regrouper les pixels en objets-images significatifs. Le flux de travail GEOBIA présente deux avantages : d’une part, nous pouvons réduire l’effet « sel et poivre » typique de la classification des pixels ; et d’autre part, nous pouvons augmenter l’efficacité informatique de notre flux de travail en regroupant les pixels en objets moins nombreux, plus grands, mais significatifs. Une revue des tendances émergentes en matière de GEOBIA peut être trouvée dans Chen et al. (2017).
Description
Ce bloc-notes présente une méthode permettant de réaliser une « segmentation d’image », une technique d’analyse d’image courante utilisée pour transformer une image satellite numérique en objets. En bref, la « segmentation d’image <https://en.wikipedia.org/wiki/Image_segmentation>`__ vise à partitionner une image en segments, où chaque segment est constitué d’un groupe de pixels ayant des caractéristiques similaires. Ici, nous utilisons l’algorithme Quickshift, implémenté via le package python scikit-image, pour effectuer la segmentation de l’image.
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Charger des paquets
[1]:
%matplotlib inline
import datacube
import xarray as xr
import numpy as np
import geopandas as gpd
import scipy
import matplotlib.pyplot as plt
from osgeo import gdal
from odc.geo.xr import write_cog
from odc.geo.geom import Geometry
from skimage.segmentation import quickshift
from deafrica_tools.plotting import display_map
from deafrica_tools.areaofinterest import define_area
from deafrica_tools.bandindices import calculate_indices
from deafrica_tools.datahandling import load_ard, mostcommon_crs, array_to_geotiff
Se connecter au datacube
[2]:
dc = datacube.Datacube(app='Image_segmentation')
Paramètres d’analyse
La cellule suivante définit les paramètres qui définissent la zone d’intérêt et la durée de l’analyse. Les paramètres sont
« lat » : la latitude centrale à analyser (par exemple « 6,502 »).
« lon » : la longitude centrale à analyser (par exemple « -1,409 »).
« buffer » : le nombre de degrés carrés à charger autour de la latitude et de la longitude centrales. Pour des temps de chargement raisonnables, définissez cette valeur sur « 0,1 » ou moins.
time: la plage de dates à analyser (par exemple,("2017-08-01", "2019-11-01")). Pour des temps de chargement raisonnables, assurez-vous que la plage s’étend sur moins de 3 ans. Notez que les données Sentinel-2 ne sont disponibles qu’après juillet 2015.
Sélectionnez l’emplacement
Pour définir la zone d’intérêt, deux méthodes sont disponibles :
En spécifiant la latitude, la longitude et la zone tampon. Cette méthode nécessite que vous saisissiez la latitude centrale, la longitude centrale et la valeur de la zone tampon en degrés carrés autour du point central que vous souhaitez analyser. Par exemple, « lat = 10,338 », « lon = -1,055 » et « buffer = 0,1 » sélectionneront une zone avec un rayon de 0,1 degré carré autour du point avec les coordonnées (10,338, -1,055).
By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
Pour utiliser l’une de ces méthodes, vous pouvez décommenter la ligne de code concernée et commenter l’autre. Pour commenter une ligne, ajoutez le symbole "#" avant le code que vous souhaitez commenter. Par défaut, la première option qui définit l’emplacement à l’aide de la latitude, de la longitude et du tampon est utilisée.
[3]:
# Set the area of interest
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=-31.704, lon=18.523, buffer=0.03)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
# aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# x = (lon - buffer, lon + buffer)
# y = (lat + buffer, lat - buffer)
# Create a reusable query
query = {
'x': lon_range,
'y': lat_range,
'time': ('2018-01', '2018-03'),
'resolution': (-30, 30)
}
Afficher l’emplacement sélectionné
[4]:
display_map(x=lon_range, y=lat_range)
[4]:
Charger les données Sentinel-2 à partir du datacube
Nous chargeons ici une série chronologique d’images satellite « Sentinel-2 » via l’API datacube à l’aide de la fonction « load_ard <../Frequently_used_code/Using_load_ard.ipynb> » __. Cela nous fournira des données avec lesquelles travailler.
[5]:
#find the most common UTM crs for the location
output_crs = mostcommon_crs(dc=dc, product='s2_l2a', query=query)
# Load available data
ds = load_ard(dc=dc,
products=['s2_l2a'],
measurements=['red', 'nir_1', 'swir_1', 'swir_2'],
group_by='solar_day',
output_crs=output_crs,
**query)
# Print output data
print(ds)
Using pixel quality parameters for Sentinel 2
Finding datasets
s2_l2a
Applying pixel quality/cloud mask
Loading 35 time steps
/opt/venv/lib/python3.12/site-packages/rasterio/warp.py:387: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix will be returned.
dest = _reproject(
<xarray.Dataset> Size: 25MB
Dimensions: (time: 35, y: 227, x: 195)
Coordinates:
* time (time) datetime64[ns] 280B 2018-01-01T08:42:22 ... 2018-03-3...
* y (y) float64 2kB 6.493e+06 6.493e+06 ... 6.486e+06 6.486e+06
* x (x) float64 2kB 2.623e+05 2.624e+05 ... 2.681e+05 2.682e+05
spatial_ref int32 4B 32734
Data variables:
red (time, y, x) float32 6MB 3.387e+03 2.899e+03 ... 1.366e+03
nir_1 (time, y, x) float32 6MB 4.423e+03 3.662e+03 ... 2.583e+03
swir_1 (time, y, x) float32 6MB 6.469e+03 5.326e+03 ... 3.069e+03
swir_2 (time, y, x) float32 6MB 5.309e+03 4.276e+03 ... 2.153e+03
Attributes:
crs: epsg:32734
grid_mapping: spatial_ref
Combinez les observations dans une image de synthèse statistique sans bruit
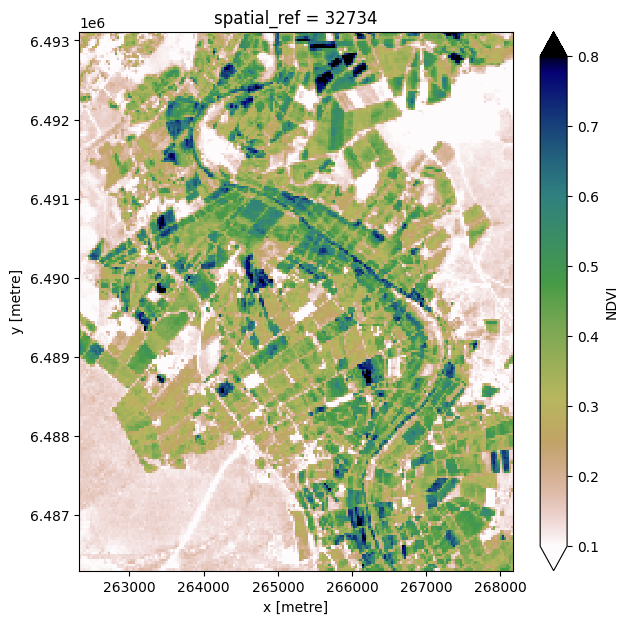
Les images de télédétection individuelles peuvent être affectées par des données bruyantes et incomplètes (par exemple en raison de nuages). Pour produire des images plus nettes que nous pouvons introduire dans l’algorithme de segmentation d’images, nous pouvons créer des images de synthèse, ou « composites », qui combinent plusieurs images en une seule image pour révéler l’apparence « typique » du paysage pendant une certaine période de temps. Dans le code ci-dessous, nous prenons les images satellites bruyantes et incomplètes que nous venons de charger et calculons l”« indice de végétation par différence normalisée (NDVI) » moyen. Le NDVI moyen sera notre entrée dans l’algorithme de segmentation.
Calculer le NDVI moyen
[6]:
# First we calculate NDVI on each image in the timeseries
ndvi = calculate_indices(ds, index='NDVI', satellite_mission='s2')
# For each pixel, calculate the mean NDVI throughout the whole timeseries
ndvi = ndvi.mean(dim='time', keep_attrs=True)
# Plot the results to inspect
ndvi.NDVI.plot(vmin=0.1, vmax=0.8, cmap='gist_earth_r', figsize=(7, 7))
[6]:
<matplotlib.collections.QuadMesh at 0x7fc0105b2960>
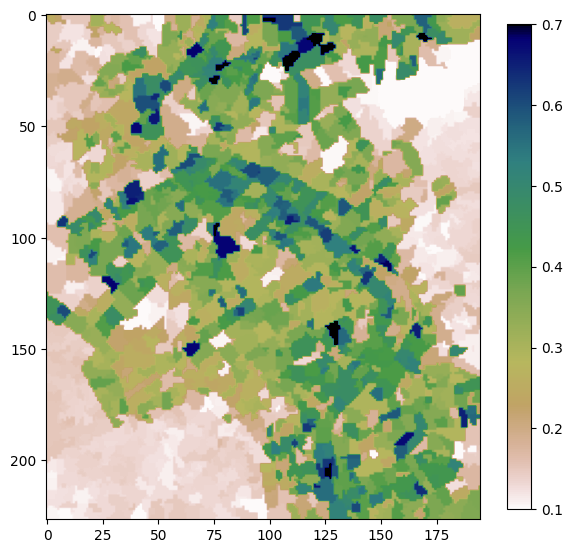
Segmentation Quickshift
En utilisant la fonction quickshift du package python scikit-image, nous allons effectuer une segmentation d’image sur le tableau NDVI moyen. Nous calculons ensuite une moyenne zonale sur chaque segment en utilisant l’ensemble de données d’entrée. Notre dernière étape consiste à exporter nos résultats au format GeoTIFF.
Suivez le lien hypertexte Quickshift ci-dessus pour voir les paramètres d’entrée de l’algorithme, et le lien suivant <https://scikit-image.org/docs/dev/auto_examples/segmentation/plot_segmentations.html>`__ pour une explication de Quickshift et d’autres algorithmes de segmentation dans scikit-image.
[7]:
# Convert our mean NDVI xarray into a numpy array, we need
# to be explicit about the datatype to satisfy quickshift
input_array = ndvi.NDVI.values.astype(np.float64)
[8]:
# Calculate the segments
segments = quickshift(input_array,
kernel_size=1,
convert2lab=False,
max_dist=2,
ratio=1.0)
[9]:
# Calculate the zonal mean NDVI across the segments
segments_zonal_mean_qs = scipy.ndimage.mean(input=input_array,
labels=segments,
index=segments)
[10]:
# Plot to see result
plt.figure(figsize=(7,7))
plt.imshow(segments_zonal_mean_qs, cmap='gist_earth_r', vmin=0.1, vmax=0.7)
plt.colorbar(shrink=0.9)
[10]:
<matplotlib.colorbar.Colorbar at 0x7fc0130cab10>
Exporter le résultat vers GeoTIFF
Consultez ce notebook pour plus d’informations sur l’écriture de GeoTIFF dans un fichier.
[11]:
transform = ds.geobox.transform.to_gdal()
projection = ds.geobox.crs.wkt
# Export the array
array_to_geotiff('segmented_meanNDVI_QS.tif',
segments_zonal_mean_qs,
geo_transform=transform,
projection=projection,
nodata_val=np.nan)
Informations Complémentaires
Licence : Le code de ce carnet est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>. Les données de Digital Earth Africa sont sous licence Creative Commons par attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact : Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack Open Data Cube <http://slack.opendatacube.org/>`__ ou sur le GIS Stack Exchange en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment ici). Si vous souhaitez signaler un problème avec ce bloc-notes, vous pouvez en déposer un sur Github.
Version de Datacube compatible :
[12]:
print(datacube.__version__)
1.8.20
Dernier test :
[13]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[13]:
'2025-01-15'