Climatologie NDVI
Produits utilisés : ndvi_climatology_ls
Mots-clés : données utilisées ; climatologie ndvi
Aperçu
La climatologie fait référence aux conditions moyennes sur une longue période de temps, généralement supérieure à 30 ans. Le produit Climatologie NDVI de Digital Earth Africa représente l’état de référence moyen à long terme de la végétation pour chaque pixel Landsat sur le continent africain. Les climatologies NDVI moyennes et d’écart type sont disponibles pour chaque mois calendaire sur la base de calculs sur la période 1984-2020. Les climatologies NDVI peuvent être utilisées pour de nombreuses applications, notamment l’identification des extrêmes (anomalies) dans l’état de la végétation, l’identification des changements à long et à court terme dans l’état de la végétation, et comme entrée dans les processus d’apprentissage automatique pour la classification de l’utilisation des terres.
De plus amples détails sur le calcul du produit sont disponibles dans la documentation « Spécifications techniques de climatologie NDVI <https://docs.digitalearthafrica.org/en/latest/data_specs/NDVI_Climatology_specs.html> »__.
Détails importants :
Nom du produit Datacube : « ndvi_climatology_ls »
Mesures
« mean_<month> » : ces mesures montrent le NDVI moyen calculé à partir de toutes les données NDVI disponibles de 1984 à 2020 pour le mois donné.
stddev_<mois>: ces mesures montrent l’écart type des valeurs NDVI de toutes les données NDVI disponibles de 1984 à 2020 pour le mois donné.count_<month>: Ces mesures indiquent le nombre d’observations claires qui entrent dans la création des mesures de moyenne et d’écart type. Il est important de faire preuve de prudence lors de l’application de ce produit à des régions où le nombre d’observations claires est inférieur à environ 20-30. Cela peut souvent être le cas au-dessus de l’Afrique équatoriale en raison de la couverture nuageuse fréquente et de la couverture incohérente de Landsat-5.
Statut : Provisoire
Plage de dates : la dimension temporelle représente les mois calendaires agrégés sur la période 1984-2020.
Résolution spatiale : 30 m
Description
Dans ce bloc-notes, nous allons charger le produit Climatologie NDVI en utilisant dc.load() pour renvoyer la moyenne, l’écart type et le nombre d’observations clair pour chaque mois calendaire. Une dernière section explore un exemple d’analyse utilisant le produit.
Les sujets abordés comprennent :
Inspection du produit Climatologie NDVI et des mesures disponibles dans le datacube.
Utilisation de la fonction native « dc.load() » pour charger la climatologie NDVI.
Inspectez la végétation pérenne et annuelle à l’aide de la moyenne et de l’écart type du NDVI.
Exemple d’analyse : analyser et tracer la phénologie climatologique (moyenne à long terme) des terres cultivées
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Charger des paquets
[1]:
import datacube
import numpy as np
import xarray as xr
import pandas as pd
import matplotlib.pyplot as plt
from odc.ui import with_ui_cbk
from deafrica_tools.plotting import display_map
Se connecter au datacube
[2]:
dc = datacube.Datacube(app='NDVI_clim')
Mesures disponibles
Liste des mesures
Le tableau ci-dessous présente les mesures disponibles dans le produit Climatologie NDVI. Le NDVI moyen, l’écart type du NDVI et le nombre d’observations claires peuvent être chargés pour chaque mois calendaire.
[3]:
product_name = 'ndvi_climatology_ls'
dc_measurements = dc.list_measurements()
dc_measurements.loc[product_name].drop('flags_definition', axis=1)
[3]:
| name | dtype | units | nodata | aliases | |
|---|---|---|---|---|---|
| measurement | |||||
| mean_jan | mean_jan | float32 | 1 | NaN | [MEAN_JAN, mean_january] |
| mean_feb | mean_feb | float32 | 1 | NaN | [MEAN_FEB, mean_february] |
| mean_mar | mean_mar | float32 | 1 | NaN | [MEAN_MAR, mean_march] |
| mean_apr | mean_apr | float32 | 1 | NaN | [MEAN_APR, mean_april] |
| mean_may | mean_may | float32 | 1 | NaN | [MEAN_MAY] |
| mean_jun | mean_jun | float32 | 1 | NaN | [MEAN_JUN, mean_june] |
| mean_jul | mean_jul | float32 | 1 | NaN | [MEAN_JUL, mean_july] |
| mean_aug | mean_aug | float32 | 1 | NaN | [MEAN_AUG, mean_august] |
| mean_sep | mean_sep | float32 | 1 | NaN | [MEAN_SEP, mean_september] |
| mean_oct | mean_oct | float32 | 1 | NaN | [MEAN_OCT, mean_october] |
| mean_nov | mean_nov | float32 | 1 | NaN | [MEAN_NOV, mean_november] |
| mean_dec | mean_dec | float32 | 1 | NaN | [MEAN_DEC, mean_december] |
| stddev_jan | stddev_jan | float32 | 1 | NaN | [STDDEV_JAN, stddev_january] |
| stddev_feb | stddev_feb | float32 | 1 | NaN | [STDDEV_FEB, stddev_feburary] |
| stddev_mar | stddev_mar | float32 | 1 | NaN | [STDDEV_MAR, stddev_march] |
| stddev_apr | stddev_apr | float32 | 1 | NaN | [STDDEV_APR, stddev_april] |
| stddev_may | stddev_may | float32 | 1 | NaN | [STDDEV_MAY] |
| stddev_jun | stddev_jun | float32 | 1 | NaN | [STDDEV_JUN, stddev_june] |
| stddev_jul | stddev_jul | float32 | 1 | NaN | [STDDEV_JUL, stddev_july] |
| stddev_aug | stddev_aug | float32 | 1 | NaN | [STDDEV_AUG, stddev_august] |
| stddev_sep | stddev_sep | float32 | 1 | NaN | [STDDEV_SEP, stddev_september] |
| stddev_oct | stddev_oct | float32 | 1 | NaN | [STDDEV_OCT, stddev_october] |
| stddev_nov | stddev_nov | float32 | 1 | NaN | [STDDEV_NOV, stddev_november] |
| stddev_dec | stddev_dec | float32 | 1 | NaN | [STDDEV_DEC, stddev_december] |
| count_jan | count_jan | int16 | 1 | -999.0 | [COUNT_JAN, count_january] |
| count_feb | count_feb | int16 | 1 | -999.0 | [COUNT_FEB, count_february] |
| count_mar | count_mar | int16 | 1 | -999.0 | [COUNT_MAR, count_march] |
| count_apr | count_apr | int16 | 1 | -999.0 | [COUNT_APR, count_april] |
| count_may | count_may | int16 | 1 | -999.0 | [COUNT_MAY] |
| count_jun | count_jun | int16 | 1 | -999.0 | [COUNT_JUN, count_june] |
| count_jul | count_jul | int16 | 1 | -999.0 | [COUNT_JUL, count_july] |
| count_aug | count_aug | int16 | 1 | -999.0 | [COUNT_AUG, count_august] |
| count_sep | count_sep | int16 | 1 | -999.0 | [COUNT_SEP, count_september] |
| count_oct | count_oct | int16 | 1 | -999.0 | [COUNT_OCT, count_october] |
| count_nov | count_nov | int16 | 1 | -999.0 | [COUNT_NOV, count_november] |
| count_dec | count_dec | int16 | 1 | -999.0 | [COUNT_DEC, count_december] |
Paramètres d’analyse
Cette section définit les paramètres d’analyse, notamment :
« lat, lon, buffer » : latitude/longitude centrales et taille de la fenêtre d’analyse pour la zone d’intérêt
résolution: la résolution en pixels à utiliser pour charger lendvi_climatology_ls. La résolution native du produit est de 30 mètres, soit(-30,30)car le produit est dérivé de Landsat.
L’emplacement par défaut est une région de culture du Cap occidental, en Afrique du Sud, où un système d’irrigation le long d’une rivière est entouré de cultures pluviales.
[4]:
lat, lon = -34.0602, 20.2800 # capetown
buffer = 0.08
resolution=(-30, 30)
#join lat, lon, buffer to get bounding box
lon_range = (lon - buffer, lon + buffer)
lat_range = (lat + buffer, lat - buffer)
Afficher l’emplacement sélectionné
La cellule suivante affichera la zone sélectionnée sur une carte interactive. N’hésitez pas à zoomer et dézoomer pour mieux comprendre la zone que vous allez analyser. En cliquant sur n’importe quel point de la carte, vous découvrirez les coordonnées de latitude et de longitude de ce point.
[5]:
display_map(lon_range, lat_range)
[5]:
Charger les données
Ci-dessous, nous utilisons la fonction « dc.load » pour charger toutes les mesures sur la région spécifiée ci-dessus.
[6]:
# load data
ndvi_clim = dc.load(
product="ndvi_climatology_ls",
resolution=resolution,
x=lon_range,
y=lat_range,
progress_cbk=with_ui_cbk(),
)
print(ndvi_clim)
<xarray.Dataset>
Dimensions: (time: 1, y: 567, x: 515)
Coordinates:
* time (time) datetime64[ns] 2002-07-02T11:59:59.999999
* y (y) float64 -4.091e+06 -4.091e+06 ... -4.108e+06 -4.108e+06
* x (x) float64 1.949e+06 1.949e+06 ... 1.964e+06 1.964e+06
spatial_ref int32 6933
Data variables: (12/36)
mean_jan (time, y, x) float32 0.4916 0.4292 0.4075 ... 0.1989 0.2001
mean_feb (time, y, x) float32 0.5281 0.4745 0.4531 ... 0.222 0.2238
mean_mar (time, y, x) float32 0.4731 0.416 0.3949 ... 0.2116 0.2121
mean_apr (time, y, x) float32 0.5536 0.5103 0.5034 ... 0.2504 0.2526
mean_may (time, y, x) float32 0.6418 0.6385 0.6137 ... 0.4022 0.3982
mean_jun (time, y, x) float32 0.6343 0.6148 0.6111 ... 0.5 0.5278 0.5339
... ...
count_jul (time, y, x) int16 30 30 30 30 30 31 33 ... 31 31 31 31 31 31
count_aug (time, y, x) int16 29 29 29 29 29 29 30 ... 23 23 23 23 23 23
count_sep (time, y, x) int16 33 33 33 33 33 33 33 ... 32 32 32 32 31 31
count_oct (time, y, x) int16 32 32 32 33 33 33 32 ... 30 30 30 31 31 31
count_nov (time, y, x) int16 36 36 36 36 37 37 37 ... 30 30 31 31 31 31
count_dec (time, y, x) int16 37 38 38 38 38 38 37 ... 35 35 35 34 35 35
Attributes:
crs: epsg:6933
grid_mapping: spatial_ref
Tracé de la climatologie NDVI
Mesures du magasin
Comme cet ensemble de données contient de nombreuses mesures, il est plus facile de les stocker dans une liste et d’y accéder selon nos besoins lors du traçage, etc., plutôt que de saisir chaque mesure
[7]:
measurements = [i for i in ndvi_clim.data_vars]
mean_bands = measurements[0:12]
std_bands = measurements[12:24]
count_bands = measurements[24:36]
Ajouter une dimension temporelle aux climatologies
L’ajout d’une dimension temporelle à l’ensemble de données en concaténant les mois ensemble nous permet de créer rapidement des tracés ou de calculer des statistiques ket sans parcourir des ensembles de données séparés.
Remarque importante : la date « 2002 » n’a pas de sens, il s’agit simplement du point médian entre 1984 et 2020, la plage sur laquelle les climatologies ont été calculées.
[8]:
months = ['01','02','03','04','05','06','07','08','09','10','11','12']
arrs_mean = []
arrs_std = []
arrs_count = []
for m,s,c,i in zip(mean_bands, std_bands, count_bands, months):
#index out the different types of measurements
xx_mean=ndvi_clim[m]
xx_std=ndvi_clim[s]
xx_count=ndvi_clim[c]
#add a time dimension corresponding to the right month
time = pd.date_range(np.datetime64('2002-'+i+'-15'), periods=1)
xx_mean['time'] = time
xx_std['time'] = time
xx_count['time'] = time
#append to lists
arrs_count.append(xx_count)
arrs_mean.append(xx_mean)
arrs_std.append(xx_std)
#concatenate into 3D data array along time dimension
ndvi_mean = xr.concat(arrs_mean, dim='time').rename('NDVI_Climatology_Mean')
ndvi_std = xr.concat(arrs_std, dim='time').rename('NDVI_Climatology_Std')
ndvi_count = xr.concat(arrs_count, dim='time').rename('NDVI_Climatology_Count')
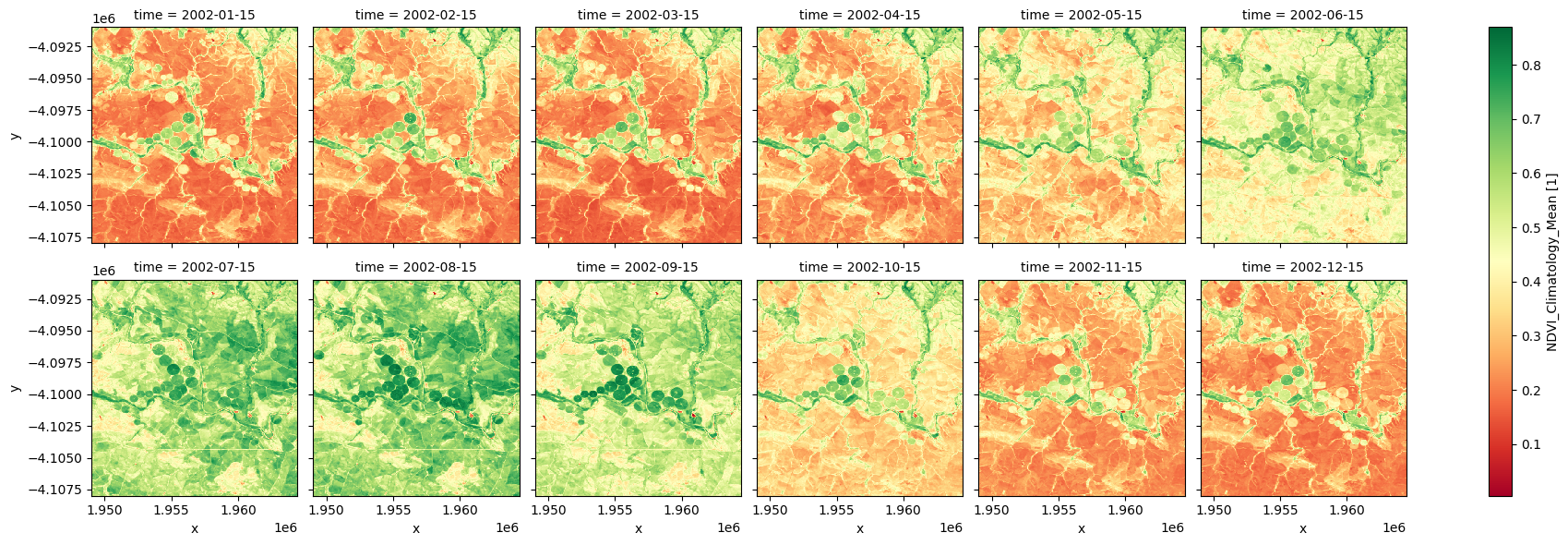
Graphique à facettes de la climatologie moyenne NDVI
Les graphiques ci-dessous montrent qu’en moyenne, les champs irrigués autour de la rivière et la végétation riveraine sont plus durablement verts tout au long de l’année, tandis que les régions de cultures pluviales sont vertes pendant les mois d’hiver de juin, juillet, août et septembre.
[9]:
ndvi_mean.plot.imshow(col='time', col_wrap=6, cmap="RdYlGn");
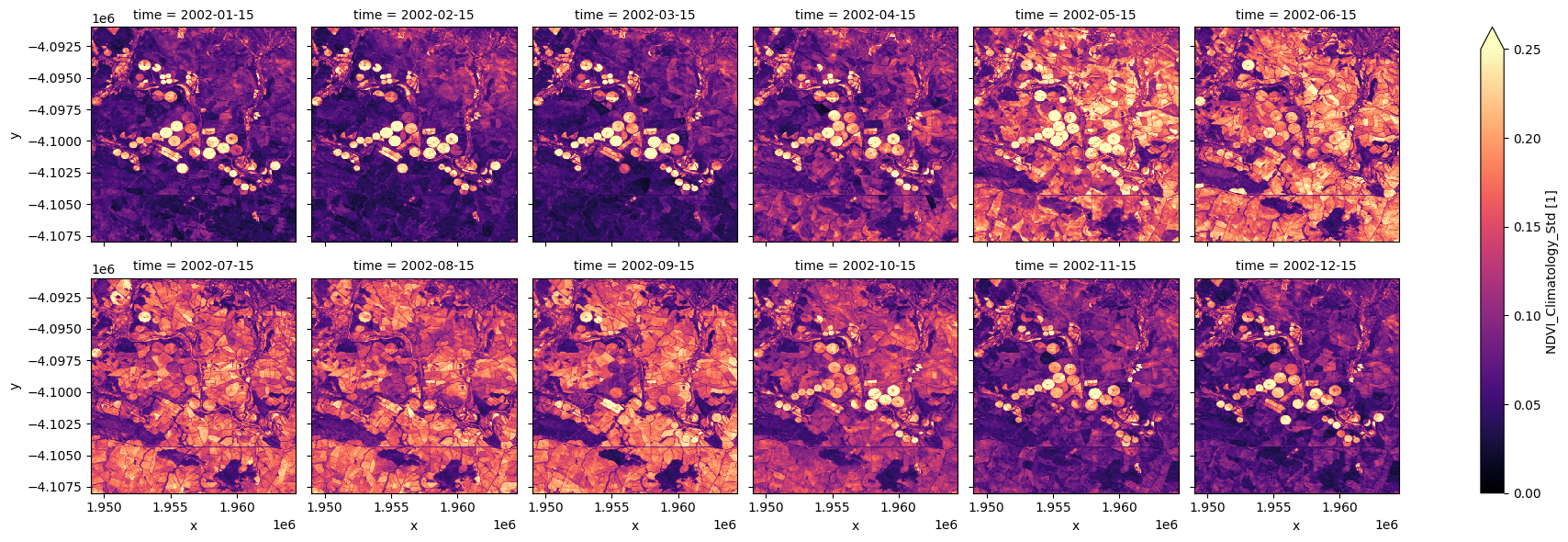
Graphique à facettes de l’écart type NDVI climatologique
Notez que les régions irriguées ont tendance à montrer une plus grande variabilité que les autres pixels. En permettant de distinguer les classes de terres agricoles et d’autres types de végétation, cela pourrait constituer une bonne entrée pour les méthodes de classification de l’utilisation des terres telles que le seuillage ou des approches d’apprentissage automatique plus complexes.
[10]:
ndvi_std.plot.imshow(col='time', col_wrap=6, cmap="magma", vmax=0.25);
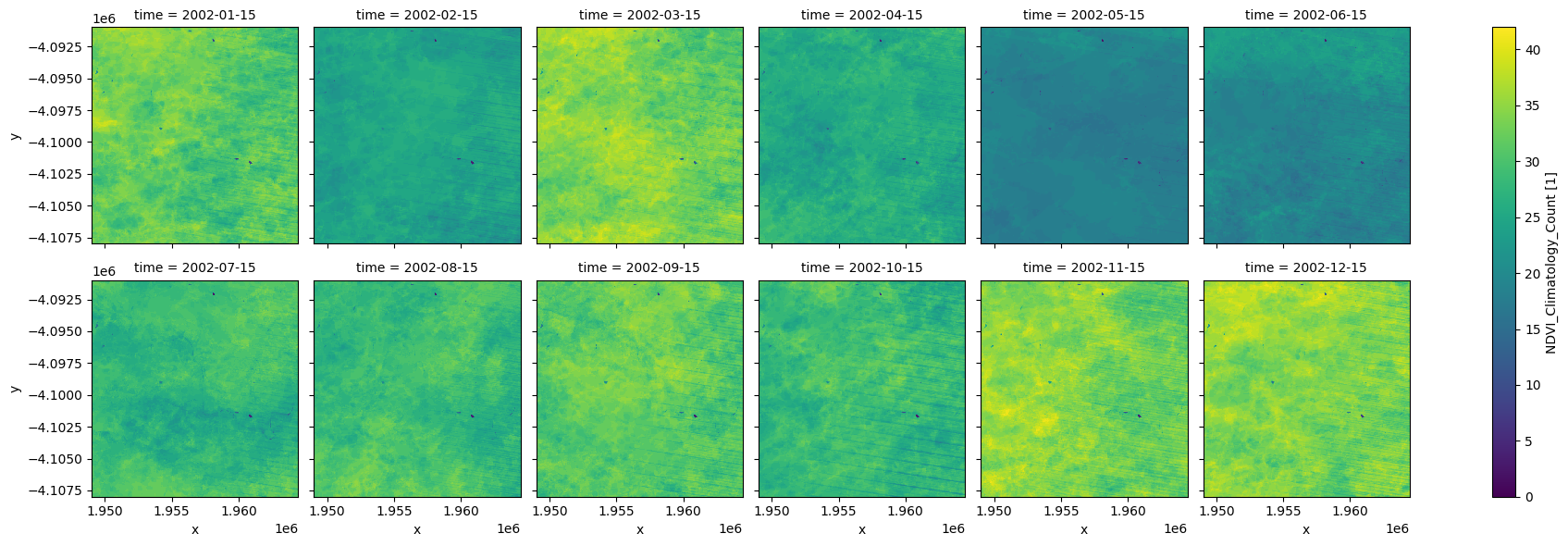
Graphique à facettes du nombre clair
Nous pouvons utiliser ces graphiques pour comprendre combien d’observations entrent dans les calculs de climatologie. Ci-dessous (dans l’exemple par défaut), nous pouvons voir que pendant les mois les plus secs, il y a environ 25 à 35 observations (sur la période de 37 ans de la climatologie), tandis que pendant les mois d’hiver, il y en a environ 20. Dans ce cas, comme le nombre d’observations est relativement faible pour les mois d’hiver, nous devons être prudents lorsque nous utilisons la climatologie pendant ces mois. Dans cet exemple spécifique, les mesures de moyenne et d’écart type tracées ci-dessus semblent correctes, probablement parce que la région se trouve à une latitude plus élevée et n’est donc pas aussi affectée par les nuages. Si cette région se trouvait sous les tropiques, l’ensemble de données pourrait être de moins bonne qualité.
[11]:
ndvi_count.plot.imshow(col='time', col_wrap=6, cmap="viridis");
Exemple d’analyse : phénologie climatologique des terres cultivées
Nous pouvons utiliser le produit climatologique NDVI pour générer des modèles phénologiques moyens à long terme pour des régions, des paysages ou des types de végétation spécifiques. En limitant notre analyse de la zone ci-dessus à un masque de culture, nous pouvons étudier la phénologie moyenne à long terme des terres cultivées.
[12]:
#import deafrica's phenology function
from deafrica_tools.temporal import xr_phenology
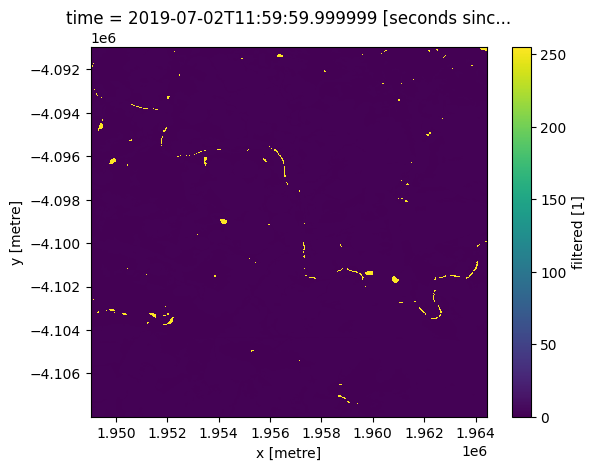
Charger l’ensemble de données cropmask pour la région
[13]:
cm = dc.load(product="crop_mask",
measurements='filtered',
resampling='nearest',
like=ndvi_clim.geobox).filtered.squeeze()
cm.plot.imshow();
Masquer les ensembles de données avec le masque de recadrage
[14]:
ndvi_mean_crop = ndvi_mean.where(cm)
ndvi_std_crop = ndvi_std.where(cm)
Tracer la courbe phénologique
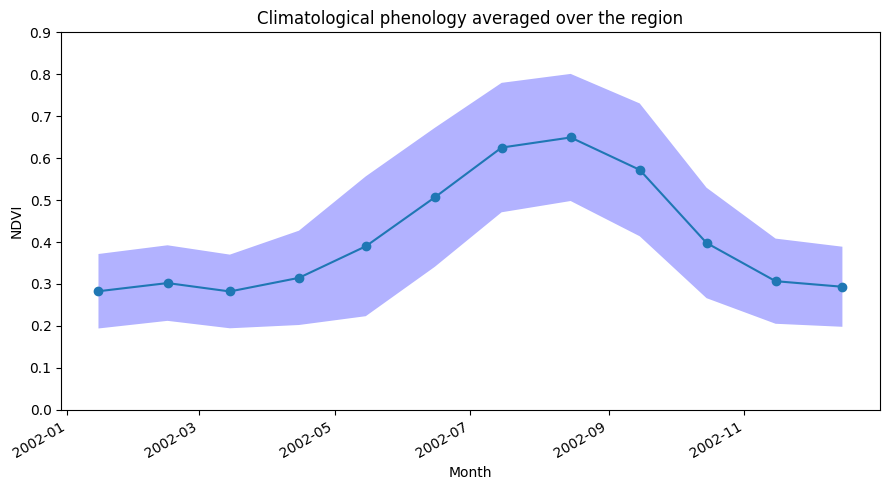
Ci-dessous, nous résumons les ensembles de données spatialement en prenant la moyenne sur les dimensions « x » et « y », ce qui nous laissera avec la tendance moyenne au fil du « temps » pour la région que nous avons chargée.
Lorsque nous traçons la courbe phénologique ci-dessous, nous ajouterons +- 1 écart type autour de la courbe moyenne pour indiquer, en moyenne, dans quelle mesure les tendances varient autour de la moyenne à long terme.
À partir du graphique phénologique, nous pouvons conclure que la croissance des cultures commence généralement vers mai et se poursuit jusqu’à la récolte vers octobre.
[15]:
ndvi_mean_crop_line = ndvi_mean_crop.mean(['x','y'])
ndvi_std_crop_line = ndvi_std_crop.mean(['x','y'])
#upper and lower boundaries
ndvi_std_upper = ndvi_mean_crop_line+ndvi_std_crop_line
ndvi_std_lower = ndvi_mean_crop_line-ndvi_std_crop_line
Tracer la courbe phénologique moyenne, avec une enveloppe d’écart type de +-1
[16]:
ndvi_mean_crop_line.plot(figsize=(9,5), marker='o')
plt.fill_between(
ndvi_mean_crop_line.time.values,
ndvi_std_upper.values,
ndvi_std_lower.values,
facecolor="blue",
alpha=0.3,
)
plt.ylim(0,0.9)
plt.title('Climatological phenology averaged over the region')
plt.xlabel('Month')
plt.ylabel('NDVI')
plt.tight_layout()
Phénologie climatologique par pixel
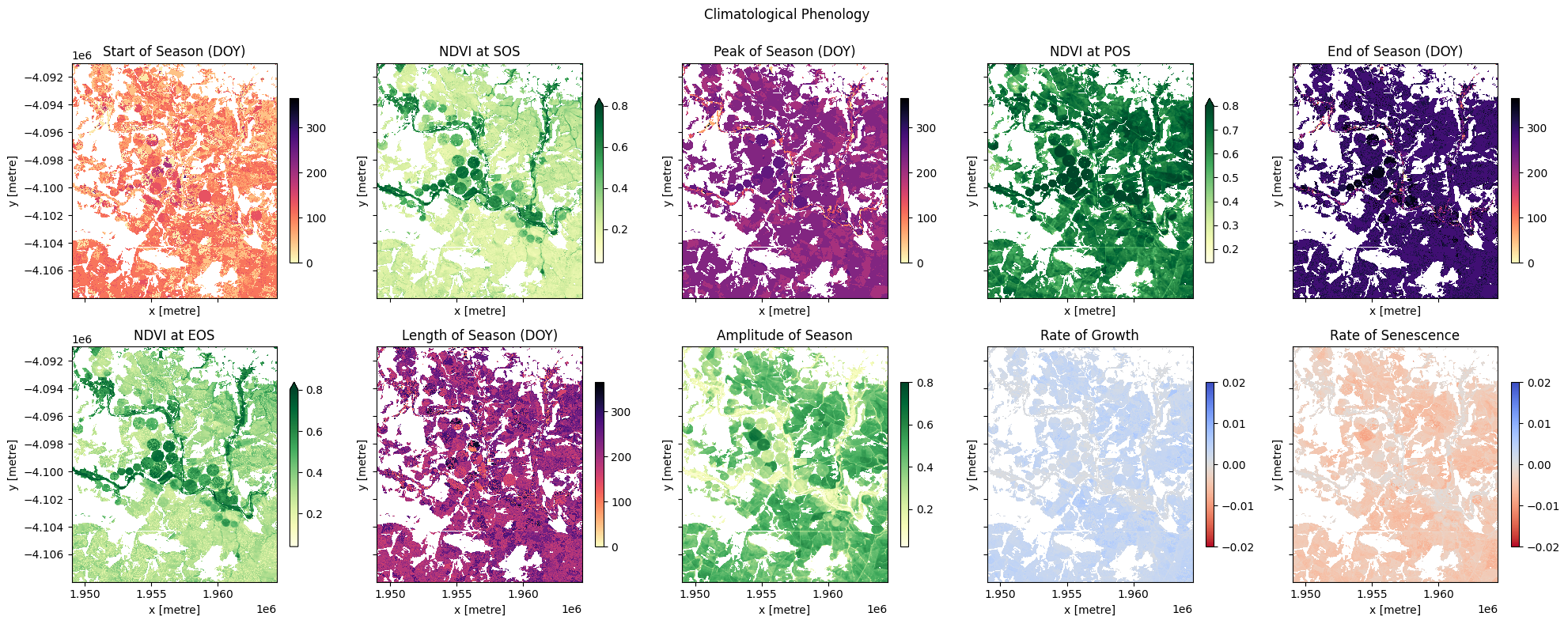
Après avoir tracé la phénologie climatologique moyenne spatiale, nous pouvons maintenant utiliser la fonction DE Africa « xr_phenology » pour calculer la phénologie typique de chaque pixel de l’ensemble de données.
Cette fonction calcule les statistiques phénologiques clés exprimées en jour de l’année (DOY) à :
Début de saison (SOS),
Haute saison (POS),
Fin de saison (EOS).
Il fournit également des valeurs NDVI (v) pour les périodes ci-dessus (par exemple vSOS pour la valeur NDVI au début de la saison) et d’autres variables, notamment :
À travers : valeur NDVI minimale de la saison,
LOS : Durée de la saison,
AOS : Amplitude de saison (différence entre les valeurs NDVI de base et maximale),
ROG : Taux de verdissement,
ROS : Taux de sénescence.
Remarque importante : n’oubliez pas que ce produit est mensuel (et non quotidien), donc le DOY correspond simplement au milieu du mois lorsque le NDVI atteint son pic, par exemple (nous avons défini la dimension temporelle comme étant le 15 de chaque mois dans la section « Ajout de la dimension temporelle » ci-dessus).
[17]:
#calculate per-pixel phenology
phen = xr_phenology(ndvi_mean_crop, method_eos='median', method_sos='median', verbose=False)
#mask again with crop-mask
phen = phen.where(cm)
print(phen)
<xarray.Dataset>
Dimensions: (y: 567, x: 515)
Coordinates:
* y (y) float64 -4.091e+06 -4.091e+06 ... -4.108e+06 -4.108e+06
* x (x) float64 1.949e+06 1.949e+06 ... 1.964e+06 1.964e+06
spatial_ref int32 6933
time datetime64[ns] 2019-07-02T11:59:59.999999
Data variables:
SOS (y, x) datetime64[ns] NaT NaT NaT ... 2002-02-15 2002-02-15
POS (y, x) datetime64[ns] NaT NaT NaT ... 2002-08-15 2002-08-15
EOS (y, x) datetime64[ns] NaT NaT NaT ... 2002-10-15 2002-11-15
Trough (y, x) float32 nan nan nan nan ... 0.1941 0.1952 0.1989 0.2001
vSOS (y, x) float32 nan nan nan nan ... 0.2217 0.221 0.222 0.2238
vPOS (y, x) float32 nan nan nan nan ... 0.7151 0.7131 0.7291 0.7375
vEOS (y, x) float32 nan nan nan nan ... 0.3536 0.3585 0.3682 0.2471
LOS (y, x) float32 nan nan nan nan ... 242.0 242.0 242.0 273.0
AOS (y, x) float32 nan nan nan nan ... 0.5209 0.518 0.5302 0.5374
ROG (y, x) float32 nan nan nan nan ... 0.002719 0.002801 0.002838
ROS (y, x) float32 nan nan nan ... -0.005813 -0.005916 -0.005331
Attributes:
grid_mapping: spatial_ref
Phénologie du tracé par pixel
[18]:
# set up figure
fig, ax = plt.subplots(nrows=2,
ncols=5,
figsize=(20, 8),
sharex=True,
sharey=True)
# set colorbar size
cbar_size = 0.7
# set aspect ratios
for a in fig.axes:
a.set_aspect('equal')
# start of season
phen.SOS.dt.dayofyear.plot.imshow(ax=ax[0, 0],
cmap='magma_r',
vmax=365,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 0].set_title('Start of Season (DOY)')
phen.vSOS.plot.imshow(ax=ax[0, 1],
cmap='YlGn',
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 1].set_title('NDVI at SOS')
# peak of season
phen.POS.dt.dayofyear.plot.imshow(ax=ax[0, 2],
cmap='magma_r',
vmax=365,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 2].set_title('Peak of Season (DOY)')
phen.vPOS.plot.imshow(ax=ax[0, 3],
cmap='YlGn',
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 3].set_title('NDVI at POS')
# end of season
phen.EOS.dt.dayofyear.plot.imshow(ax=ax[0, 4],
cmap='magma_r',
vmax=365,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 4].set_title('End of Season (DOY)')
phen.vEOS.plot.imshow(ax=ax[1, 0],
cmap='YlGn',
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 0].set_title('NDVI at EOS')
# Length of Season
phen.LOS.plot.imshow(ax=ax[1, 1],
cmap='magma_r',
vmax=365,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 1].set_title('Length of Season (DOY)')
# Amplitude
phen.AOS.plot.imshow(ax=ax[1, 2],
cmap='YlGn',
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 2].set_title('Amplitude of Season')
# rate of growth
phen.ROG.plot.imshow(ax=ax[1, 3],
cmap='coolwarm_r',
vmin=-0.02,
vmax=0.02,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 3].set_title('Rate of Growth')
# rate of Sensescence
phen.ROS.plot.imshow(ax=ax[1, 4],
cmap='coolwarm_r',
vmin=-0.02,
vmax=0.02,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 4].set_title('Rate of Senescence')
plt.suptitle('Climatological Phenology')
plt.tight_layout();
Informations Complémentaires
Licence : Le code de ce carnet est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>. Les données de Digital Earth Africa sont sous licence Creative Commons par attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact : Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack Open Data Cube <http://slack.opendatacube.org/>`__ ou sur le GIS Stack Exchange en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment ici). Si vous souhaitez signaler un problème avec ce bloc-notes, vous pouvez en déposer un sur Github.
Version de Datacube compatible :
[19]:
print(datacube.__version__)
1.8.15
Dernier test :
[20]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[20]:
'2024-03-18'