Modèles numériques d’élévation
Produits utilisés : dem_cop_30, dem_cop_90, dem_srtm, dem_srtm_deriv
Mots-clés : :index: “données utilisées ; Copernicus DEM 30 m”, :index: “données utilisées ; Copernicus DEM 90 m”, :index: “données utilisées ; modèle d’élévation de 1 seconde”, :index: “données utilisées ; dérivées du modèle d’élévation de 1 seconde”, données utilisées ; ERA5, :index: “ensembles de données ; dem_cop_30”, :index: “ensembles de données ; dem_cop_90”, :index: “ensembles de données ; dem_srtm”, :index: “ensembles de données ; dem_srtm_deriv”
Aperçu
Digital Elevation MLes modèles DEM (DEM) fournissent des informations sur la topographie du sol nu, c’est-à-dire l’élévation indépendamment de la couverture terrestre telle que les bâtiments/arbres. Les DEM sont souvent dérivés de sources de données de détection et de télémétrie par lumière (LiDAR). Les DEM sont utilisés dans plusieurs applications telles que la compréhension de la façon dont les variables climatiques changent avec la topographie.
Détails importants :
Il existe quatre produits DEM disponibles dans l’Open Data Cube. Les produits Copernicus <https://spacedata.copernicus.eu/web/cscda/dataset-details?articleId=394198>`__ proviennent de l’Agence spatiale européenne (ESA) et les produits Shuttle Radar Topography Mission (SRTM) <https://www.usgs.gov/centers/eros/science/usgs-eros-archive-digital-elevation-shuttle-radar-topography-mission-srtm-1-arc?qt-science_center_objects=0#qt-science_center_objects>`__ proviennent de l’United States Geological Survey (USGS) :
Copernicus DEM 30 m : « dem_cop_30 », données d’élévation à une résolution de 30 m
Copernicus DEM 90 m : « dem_cop_90 », données d’élévation à une résolution de 90 m
DEM SRTM : « dem_srtm », données d’élévation à 1 seconde d’arc (~ 30 m)
Dérivés DEM SRTM : « dem_srtm_deriv », dérivés du DEM à 1 seconde d’arc qui incluent :
Pente (pourcentage) ; il s’agit du taux de changement d’altitude, donc mathématiquement parlant, c’est la première dérivée/dérivée principale de l’altitude.
Planéité du fond de vallée multi-résolution (MrVBF) ; cela permet d’identifier les fonds de vallée (zones de dépôt). Les valeurs zéro indiquent un terrain érodé et les valeurs ≥ 1 indiquent des zones de dépôt progressivement plus grandes.
Planéité du sommet des crêtes multi-résolution (MrRTF) ; complémentaire de MrVBF, les valeurs zéro indiquent les zones escarpées ou basses, et les valeurs ≥ 1 indiquent des zones progressivement plus grandes de terrain plat et élevé.
Pour plus de détails sur la façon dont ces mesures ont été calculées, consultez le référentiel de dérivés DEM <https://github.com/digitalearthafrica/dem-derivative>`__
Description
Dans ce bloc-notes, nous allons charger le DEM Copernicus 30 m et les dérivés DEM en utilisant dc.load(). Ensuite, nous effectuons une courte analyse d’exemple.
Les sujets abordés comprennent :
Inspection du produit DEM disponible dans le datacube
Utilisation de la fonction « dc.load() » pour charger des données DEM
Tracé du DEM et des dérivés
Un exemple d’analyse qui compare la température à haute et basse altitude
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Charger des paquets
[1]:
%matplotlib inline
import datacube
import numpy as np
import xarray as xr
import matplotlib.pyplot as plt
from deafrica_tools.plotting import display_map
from deafrica_tools.load_era5 import load_era5
from odc.geo.xr import xr_reproject
Se connecter au datacube
[2]:
dc = datacube.Datacube(app="DEM")
Liste des mesures
Le tableau ci-dessous répertorie les produits et mesures disponibles pour les jeux de données DEM indexés dans le datacube de DE Africa. Nous pouvons voir que les trois premiers produits contiennent une seule mesure d’élévation, exprimée en mètres au-dessus du niveau de la mer. Le produit dérivé comprend le pourcentage de pente, la planéité multi-résolution du fond de vallée (mrvbf) et la planéité multi-résolution du sommet de crête (mrrtf).
[3]:
product_name = ['dem_cop_30', 'dem_cop_90', 'dem_srtm', 'dem_srtm_deriv']
dc_measurements = dc.list_measurements()
dc_measurements.loc[product_name].drop('flags_definition', axis=1)
[3]:
| name | dtype | units | nodata | aliases | add_offset | scale_factor | ||
|---|---|---|---|---|---|---|---|---|
| product | measurement | |||||||
| dem_cop_30 | elevation | elevation | float32 | 1 | NaN | NaN | NaN | NaN |
| dem_cop_90 | elevation | elevation | float32 | 1 | NaN | NaN | NaN | NaN |
| dem_srtm | elevation | elevation | int16 | metre | -32768.0 | NaN | NaN | NaN |
| dem_srtm_deriv | mrvbf | mrvbf | int16 | 1 | -32768.0 | NaN | NaN | NaN |
| mrrtf | mrrtf | int16 | 1 | -32768.0 | NaN | NaN | NaN | |
| slope | slope | float32 | 1 | -9999.0 | NaN | NaN | NaN |
Paramètres d’analyse
« lat », « lon » : la latitude et la longitude centrales à analyser (par exemple, -3,0674, 37,355).
« buffer » : le nombre de degrés carrés à charger autour de la latitude et de la longitude centrales. Pour des temps de chargement raisonnables, définissez cette valeur sur 0,1 ou moins.
« résolution » : nous utilisons ici 30 m pour le produit « dem_cop_30 ».
[4]:
lat, lon = -3.0674, 37.3556 #Mt Kilimanjaro
buffer = 0.3
resolution=(-30, 30)
measurements='elevation'
#convert the lat,lon,buffer into a range
lons = (lon - buffer, lon + buffer)
lats = (lat - buffer, lat + buffer)
Afficher l’emplacement sélectionné
La cellule suivante affichera la zone sélectionnée sur une carte interactive. N’hésitez pas à zoomer et dézoomer pour mieux comprendre la zone que vous allez analyser. En cliquant sur n’importe quel point de la carte, vous découvrirez les coordonnées de latitude et de longitude de ce point.
[5]:
display_map(x=lons, y=lats)
[5]:
Charger les données DEM de Copernicus 30 m
Lorsqu’un produit est reprojeté dans un SCR et/ou une résolution différents, la nouvelle grille de pixels peut différer des pixels d’entrée d’origine en termes de taille, de nombre et d’alignement. Il est donc nécessaire d’appliquer une règle de « rééchantillonnage » spatial qui alloue les valeurs des pixels d’entrée dans la nouvelle grille de pixels.
Par défaut, « dc.load() » rééchantillonne les valeurs de pixels à l’aide du rééchantillonnage du « voisin le plus proche », qui attribue à chaque nouveau pixel la valeur du pixel d’entrée le plus proche. Selon le type de données et l’analyse en cours d’exécution, ce choix peut ne pas être le plus approprié (par exemple pour des données continues telles que l’altitude). Le paramètre « resampling » dans « dc.load() » vous permet de choisir une méthode de rééchantillonnage personnalisée parmi les options suivantes :
"nearest", "cubic", "bilinear", "cubic_spline", "lanczos",
"average", "mode", "gauss", "max", "min", "med", "q1", "q3"
Pour les modèles numériques d’élévation, toutes les données chargées doivent être rééchantillonnées à l’aide du rééchantillonnage « bilinéaire »**. L’interpolation bilinéaire calcule la valeur d’une cellule raster en sortie en faisant la moyenne des valeurs des quatre centres de cellules d’entrée les plus proches. Cette moyenne pondérée est ajustée en fonction de la distance de chaque cellule d’entrée par rapport au centre de la cellule de sortie. Cette méthode produit une surface plus lisse par rapport à la technique du voisin le plus proche.
[6]:
#set up daatcube query object
query = {
'x': lons,
'y': lats,
'resolution':resolution,
'output_crs': 'epsg:6933',
'measurements':measurements,
'resampling': "bilinear"
}
#load the dem 30 m product
ds = dc.load(product="dem_cop_30", **query).squeeze()
print(ds)
<xarray.Dataset> Size: 20MB
Dimensions: (y: 2549, x: 1931)
Coordinates:
* y (y) float64 20kB -3.529e+05 -3.529e+05 ... -4.293e+05
* x (x) float64 15kB 3.575e+06 3.575e+06 ... 3.633e+06 3.633e+06
time datetime64[ns] 8B 2000-01-01T12:00:00
spatial_ref int32 4B 6933
Data variables:
elevation (y, x) float32 20MB 1.147e+03 1.147e+03 ... 852.9 856.0
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
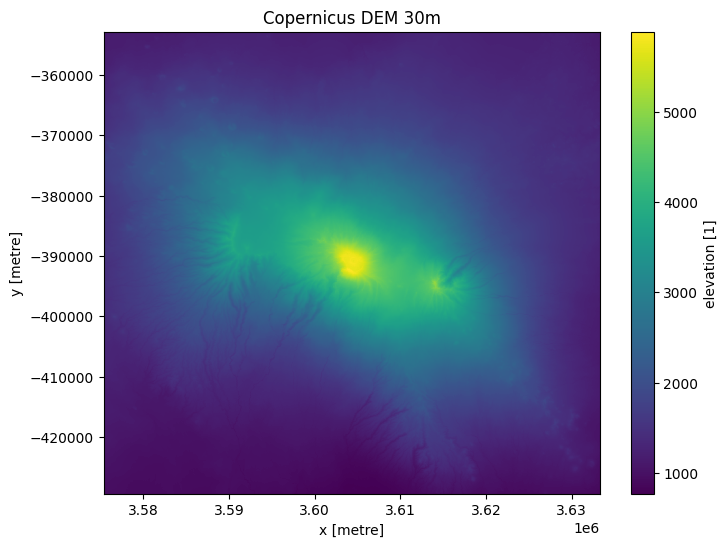
Élévation de la parcelle
Nous pouvons générer un graphique basique de l’élévation ci-dessous. Le sommet du mont Kilimandjaro est à 5 895 m.
[7]:
ds.elevation.plot(figsize=(8,6))
plt.title('Copernicus DEM 30m');
Charger les dérivés DEM
Nous pouvons maintenant charger l’ensemble de données dérivées avec les mêmes paramètres, à l’exception des mesures.
[8]:
# We just need to change the measurements parameter, lats, lon, crs etc. can remain the same.
measurements=['mrvbf', 'mrrtf', 'slope']
query = {
'x': lons,
'y': lats,
'resolution':resolution,
'output_crs': 'epsg:6933',
'measurements':measurements,
'resampling': "bilinear"
}
ds_deriv = dc.load(product="dem_srtm_deriv", **query).squeeze()
print(ds_deriv)
<xarray.Dataset> Size: 39MB
Dimensions: (y: 2549, x: 1931)
Coordinates:
* y (y) float64 20kB -3.529e+05 -3.529e+05 ... -4.293e+05
* x (x) float64 15kB 3.575e+06 3.575e+06 ... 3.633e+06 3.633e+06
time datetime64[ns] 8B 2000-01-01T12:00:00
spatial_ref int32 4B 6933
Data variables:
mrvbf (y, x) int16 10MB 2 1 0 0 3 4 4 3 3 3 3 ... 1 0 0 0 1 2 2 2 1 1
mrrtf (y, x) int16 10MB 0 0 1 1 0 0 0 0 0 0 1 ... 2 1 0 0 0 0 0 0 0 0
slope (y, x) float32 20MB 7.383 12.15 13.24 ... 4.29 8.271 9.148
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
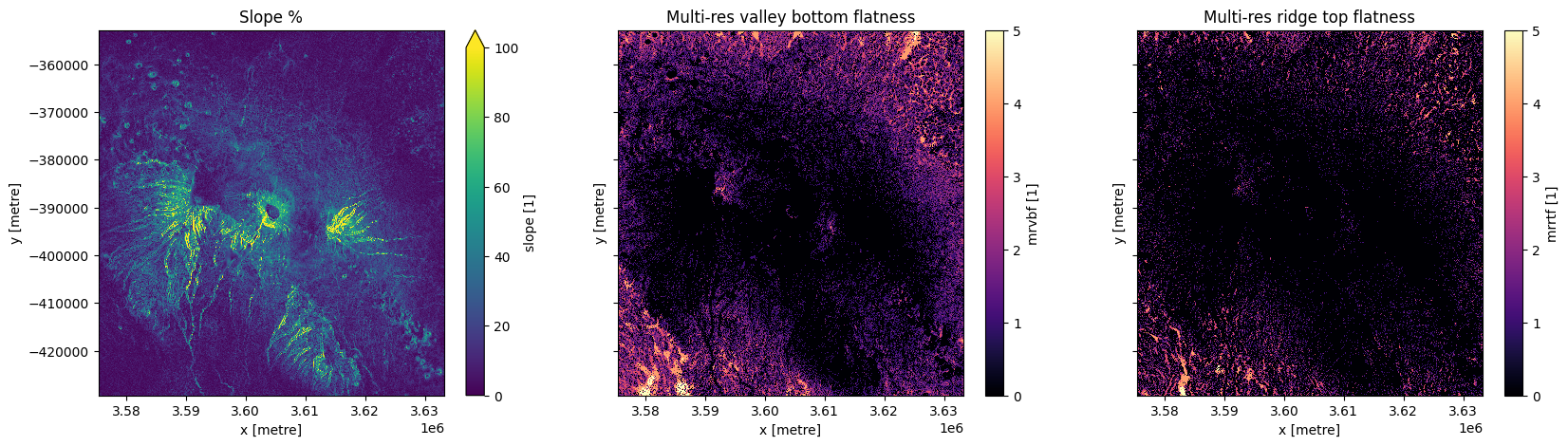
Dérivés de tracé
Le tracé des trois mesures dérivées ci-dessous montre les zones de plus grande pente autour du mont Kilimandjaro. La majeure partie de la montagne a une valeur de 0 pour la planéité du fond de la vallée et de la pointe de la crête, tandis que les zones environnantes sont identifiées comme des vallées et des sommets de crête plats.
[9]:
fig,ax = plt.subplots(1,3, figsize=(20,5), sharey=True)
ds_deriv.slope.plot(ax=ax[0], vmax=100)
ds_deriv.mrvbf.plot(ax=ax[1], cmap='magma')
ds_deriv.mrrtf.plot(ax=ax[2], cmap='magma')
ax[0].set_title('Slope %')
ax[1].set_title('Multi-res valley bottom flatness')
ax[2].set_title('Multi-res ridge top flatness');
Exemple d’analyse : masquage basé sur l’élévation
Nous pouvons utiliser les informations d’altitude pour sélectionner ou masquer des zones à analyser. Dans cet exemple, nous allons comparer les informations climatiques entre les altitudes plus élevées et plus basses des montagnes des Virunga, une chaîne de volcans le long de la frontière entre le Rwanda, la République démocratique du Congo et l’Ouganda.
Ci-dessous, nous avons défini quelques nouveaux paramètres d’analyse :
« lat », « lon » : la latitude et la longitude centrales à analyser pour les montagnes des Virunga (-1,4310, 29,5262).
« buffer » : le nombre de degrés carrés à charger autour de la latitude et de la longitude centrales.
« résolution » : nous utilisons ici 90 m avec le produit « dem_cop_90 » pour des temps de chargement et de calcul plus rapides.
[10]:
lat, lon = -1.4310, 29.5262
buffer = 0.2
resolution=(-90, 90)
measurements='elevation'
#convert the lat,lon,buffer into a range
lons = (lon - buffer, lon + buffer)
lats = (lat - buffer, lat + buffer)
Afficher l’emplacement sélectionné
[11]:
display_map(x=lons, y=lats)
[11]:
Charger le DEM Copernicus 90m
[12]:
query = {
'x': lons,
'y': lats,
'resolution':resolution,
'output_crs': 'epsg:6933',
'measurements':measurements,
'resampling': "bilinear"
}
#load the dem
ds = dc.load(product="dem_cop_90", **query).squeeze() # Using 90 m product for better computation times
[13]:
ds.elevation.plot();
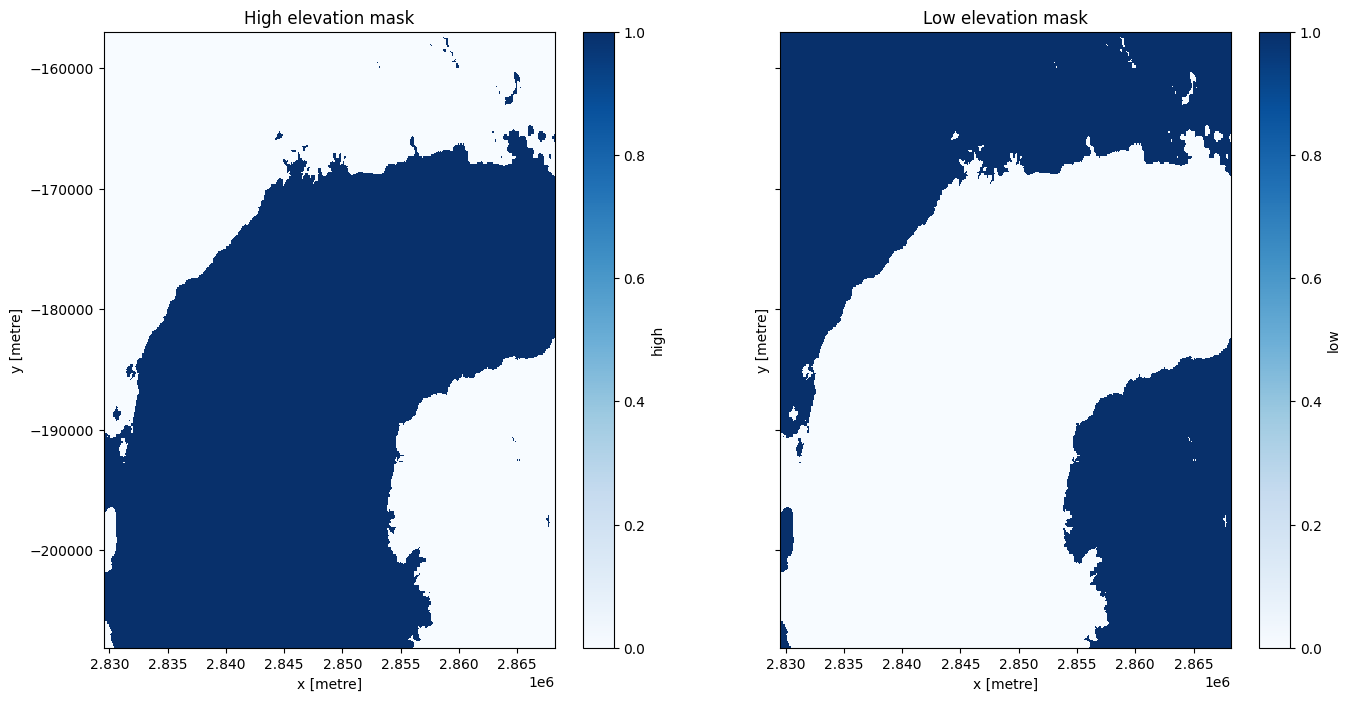
Analyse de masque à haute et basse altitude
Pour cette analyse, nous allons diviser l’ensemble de données en zones situées au-dessus et en dessous de 2 000 m d’altitude. Dans le graphique ci-dessous, nous pouvons voir que cela sépare la chaîne de volcans des plaines environnantes.
[14]:
ds = ds.assign(high=xr.where(ds.elevation >= 2000, 1, 0))
ds = ds.assign(low=xr.where(ds.elevation < 2000, 1, 0))
print(ds)
<xarray.Dataset> Size: 5MB
Dimensions: (y: 568, x: 430)
Coordinates:
* y (y) float64 5kB -1.57e+05 -1.571e+05 ... -2.079e+05 -2.08e+05
* x (x) float64 3kB 2.83e+06 2.83e+06 ... 2.868e+06 2.868e+06
time datetime64[ns] 8B 2000-01-01T12:00:00
spatial_ref int32 4B 6933
Data variables:
elevation (y, x) float32 977kB 1.236e+03 1.235e+03 ... 1.791e+03
high (y, x) int64 2MB 0 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
low (y, x) int64 2MB 1 1 1 1 1 1 1 1 1 1 1 ... 1 1 1 1 1 1 1 1 1 1
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
[15]:
fig, axes = plt.subplots(1, 2, figsize=(16, 8), sharey=True)
ds.high.plot(cmap='Blues', ax=axes[0])
ds.low.plot(cmap='Blues', ax=axes[1])
axes[0].set_title('High elevation mask')
axes[1].set_title('Low elevation mask');
Chargez les données de température et comparez-les entre les altitudes hautes et basses
Nous utiliserons la fonction « load_era5 » pour charger les données de température. Vous trouverez plus d’informations sur le chargement et l’utilisation des données climatiques dans le bloc-notes « Climate_Data_ERA5_AWS Datasets <Climate_Data_ERA5_AWS.ipynb> ».
[16]:
time = time = '2021-01', '2021-03' # first three months of 2021
temp_var = 'air_temperature_at_2_metres'
temp_mean = load_era5(temp_var, lats, lons, time, reduce_func=np.mean, resample='1D').compute()-273.15 # Convert Kelvin to Celsius
Opening ERA5 Zarr dataset...
Variable: air_temperature_at_2_metres
Mapped ERA5 name: 2m_temperature
Time: 2021-01-01 to 2021-03-01
Latitude: -1.631 to -1.231
Longitude: 29.3262 to 29.726200000000006
Selecting time range...
Normalising longitude coordinates...
Selecting AOI...
Subset size: {'time': 1440, 'latitude': 3, 'longitude': 3}
Resampling to 1D using <function mean at 0x7fbd3018b1a0>...
ERA5 loading complete.
Pour effectuer notre calcul, nous devons reprojeter les données climatiques afin qu’elles correspondent aux données d’altitude. Nous utilisons la fonction « xr_reproject » pour ce faire. Plus d’informations sur la reprojection des données du Datacube sont disponibles ici <https://docs.digitalearthafrica.org/en/latest/sandbox/notebooks/Frequently_used_code/Reprojecting_data.html>.
[17]:
temp_mean = temp_mean.odc.assign_crs("EPSG:4326")
temp_mean_reprojected = xr_reproject(temp_mean, ds.odc.geobox, resampling="average")
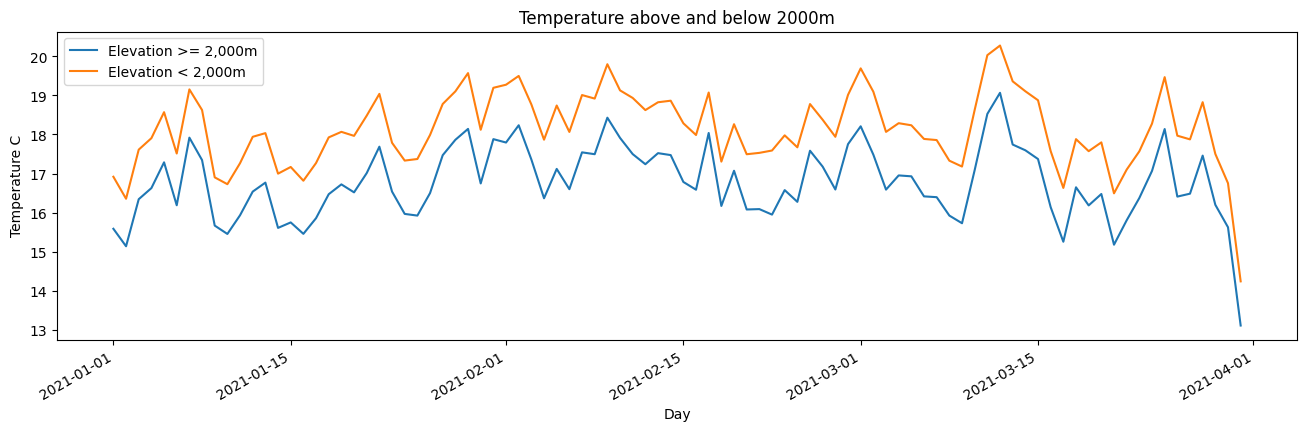
Nous pouvons voir que la température moyenne quotidienne a tendance à être plus basse aux altitudes > 2 000 m pour notre zone d’analyse, selon le produit de réanalyse ERA5.
[18]:
ds = ds.merge(temp_mean_reprojected, ds, compat='override')
ds_high = ds.where(ds.squeeze().high)
high_mean_airtemp = ds_high.air_temperature_at_2_metres.mean(['x','y'])
ds_low = ds.where(ds.squeeze().low)
low_mean_airtemp = ds_low.air_temperature_at_2_metres.mean(['x','y'])
ds_high.air_temperature_at_2_metres.mean(['x','y']).plot(figsize = (16,4), label='Elevation >= 2,000m');
ds_low.air_temperature_at_2_metres.mean(['x','y']).plot(label='Elevation < 2,000m');
plt.legend();
plt.xlabel('Day');
plt.ylabel('Temperature C')
plt.title('Temperature above and below 2000m');
Informations Complémentaires
Licence : Le code de ce carnet est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>. Les données de Digital Earth Africa sont sous licence Creative Commons par attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact : Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack Open Data Cube <http://slack.opendatacube.org/>`__ ou sur le GIS Stack Exchange en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment ici). Si vous souhaitez signaler un problème avec ce bloc-notes, vous pouvez en déposer un sur Github.
Version de Datacube compatible :
[19]:
print(datacube.__version__)
1.9.13
Dernier test :
[20]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[20]:
'2026-04-29'