Couverture fractionnée
Produits utilisés : fc_ls, fc_ls_summary_annual, wofs_ls
Mots-clés : datasets; fractional_cover, data used; fc_ls, data used; fc_ls_summary_annual, data used; wofs_ls
Aperçu
Le produit Couverture fractionnaire (FC) fournit des estimations des proportions de végétation verte, de végétation non verte (y compris les arbres à feuilles caduques en automne, l’herbe sèche, etc.) et de sols nus pour chaque pixel Landsat. La couverture fractionnaire fournit des informations précieuses pour toute une gamme d’applications environnementales et agricoles, notamment :
surveillance de l’érosion des sols
modélisation des processus de surface terrestre
pratiques de gestion des terres (par exemple, rotation des cultures, gestion des chaumes, gestion des pâturages)
études de végétation
estimation de la charge de carburant
modélisation des écosystèmes
cartographie de la couverture terrestre
L’algorithme est développé par le « Joint Remote Sensing Research Program <https://www.jrsrp.org.au/> » (JRSRP) et est décrit dans Scarth et al. (2010). Les données de terrain collectées dans toute l’Australie ont été utilisées pour calibrer et valider le modèle de démixage. Vous trouverez plus d’informations sur le produit « ici <http://data.auscover.org.au/xwiki/bin/view/Product+pages/Landsat+Seasonal+Fractional+Cover> ».
Le service DE Africa FC comporte deux volets :
Couverture fractionnaire, estimée à partir de chaque scène Landsat, fournissant des mesures de jours individuels.
Résumé annuel de la couverture fractionnaire (centiles), qui fournit les 10e, 50e et 90e centiles estimés indépendamment pour les fractions de végétation verte, de végétation non verte et de sol nu observées au cours de chaque année civile (du 1er janvier au 31 décembre).
Si la couverture fractionnaire basée sur des scènes peut être utilisée pour étudier les processus dynamiques, les résumés annuels facilitent l’analyse des changements d’une année à l’autre. Les percentiles fournissent des estimations fiables des valeurs de proportion basse, médiane et haute observées pour chaque type de couverture au cours d’une année, qui peuvent être utilisées pour caractériser la couverture terrestre. Avant le calcul des percentiles, les zones de couverture d’eau et de nuages, telles que cartographiées dans la couche d’entités Observations de l’eau depuis l’espace (WOfS), sont exclues.
Référence
Scarth, P, Roder, A et Schmidt, M 2010, « Suivi de la pression de pâturage et interaction climatique - le rôle de la couverture fractionnelle Landsat dans l’analyse des séries chronologiques », Actes de la 15e Conférence australasienne sur la télédétection et la photogrammétrie (ARSPC), du 13 au 17 septembre, Alice Springs, Australie. Alice Springs, NT.
Description
Ce cahier couvrira les sujets suivants :
Inspection des produits et des mesures disponibles dans le datacube
Chargement des données FC pré-générées.
Masque de nuages et d’eau FC avec couches d’entités d’observations de l’eau depuis l’espace (WOfS)
Tracé du FC et du résumé annuel du FC
Inspection des sorties d’erreur de démixage
Réalisation d’un workflow d’analyse simple avec FC
Comprendre et charger les données récapitulatives annuelles du FC.
Interprétation des percentiles récapitulatifs annuels
Commencer
Pour exécuter cette analyse, exécutez toutes les cellules du bloc-notes, en commençant par la cellule « Charger les packages ».
Charger des paquets
Importez les packages Python utilisés pour l’analyse.
[1]:
%matplotlib inline
import datacube
import xarray as xr
import matplotlib.pyplot as plt
from odc.algo import xr_geomedian
from datacube.utils import masking
from deafrica_tools.plotting import rgb, display_map
from deafrica_tools.datahandling import load_ard
Se connecter au datacube
Connectez-vous au datacube pour que nous puissions accéder aux données de DE Africa.
[2]:
dc = datacube.Datacube(app='fractional_cover')
Paramètres d’analyse
Cette section définit les paramètres d’analyse, y compris
« lat, lon, buffer » : latitude/longitude centrales et taille de la fenêtre d’analyse pour la zone d’intérêt
time_period: période de temps à étudieroutput_crs: projection pour le chargement des données ; la résolution de sortie n’est pas définie, donc des résolutions différentes peuvent être utilisées pour Landsat et Sentinel-2
L’emplacement par défaut est une zone le long de la rivière Olifants, en Afrique du Sud.
La résolution par défaut, les étendues spatiales et temporelles sont choisies pour limiter le temps requis pour calculer le FC à partir de la réflectance de surface Sentinel-2.
[3]:
lat, lon = -31.5374, 18.2722 #3.9779, 41.6454
buffer_lat, buffer_lon = 0.03, 0.03
time_period = ('2017-01', '2017-10')
output_crs = 'epsg:6933'
#join lat,lon,buffer to get bounding box
lon_range = (lon - buffer_lon, lon + buffer_lon)
lat_range = (lat + buffer_lat, lat - buffer_lat)
Afficher l’emplacement sélectionné
La cellule suivante affichera la zone sélectionnée sur une carte interactive. N’hésitez pas à zoomer et dézoomer pour mieux comprendre la zone que vous allez analyser. En cliquant sur n’importe quel point de la carte, vous découvrirez les coordonnées de latitude et de longitude de ce point.
[4]:
display_map(lon_range, lat_range)
[4]:
Liste des produits disponibles dans Digital Earth Africa
Nous pouvons utiliser la fonctionnalité « list_products » de Datacube pour inspecter les produits de couverture fractionnée disponibles. Le tableau ci-dessous indique les noms de produits que nous utiliserons pour charger les données.
Notez qu’il existe deux produits distincts. Le produit « fc_ls » donne des pourcentages de couverture fractionnaires à des intervalles de temps quotidiens correspondant aux dates de survol Landsat, tandis que le produit « fc_ls_summary_annual » donne les valeurs des 10e, 50e et 90e percentiles, exprimées en pourcentage, pour chacune des fractions de sol nu, de végétation photosynthétique et de végétation non photosynthétique. Nous explorerons cette idée plus en détail dans les cellules ci-dessous.
[5]:
dc_measurements = dc.list_measurements()
dc_measurements.loc[['fc_ls', 'fc_ls_summary_annual']]
[5]:
| name | dtype | units | nodata | aliases | flags_definition | ||
|---|---|---|---|---|---|---|---|
| product | measurement | ||||||
| fc_ls | bs | bs | uint8 | percent | 255.0 | [bare] | NaN |
| pv | pv | uint8 | percent | 255.0 | [green_veg] | NaN | |
| npv | npv | uint8 | percent | 255.0 | [dead_veg] | NaN | |
| ue | ue | uint8 | 1 | 255.0 | [err] | NaN | |
| fc_ls_summary_annual | pv_pc_10 | pv_pc_10 | uint8 | percent | 255.0 | NaN | NaN |
| pv_pc_50 | pv_pc_50 | uint8 | percent | 255.0 | NaN | NaN | |
| pv_pc_90 | pv_pc_90 | uint8 | percent | 255.0 | NaN | NaN | |
| bs_pc_10 | bs_pc_10 | uint8 | percent | 255.0 | NaN | NaN | |
| bs_pc_50 | bs_pc_50 | uint8 | percent | 255.0 | NaN | NaN | |
| bs_pc_90 | bs_pc_90 | uint8 | percent | 255.0 | NaN | NaN | |
| npv_pc_10 | npv_pc_10 | uint8 | percent | 255.0 | NaN | NaN | |
| npv_pc_50 | npv_pc_50 | uint8 | percent | 255.0 | NaN | NaN | |
| npv_pc_90 | npv_pc_90 | uint8 | percent | 255.0 | NaN | NaN | |
| count_valid | count_valid | int16 | 1 | 255.0 | NaN | NaN | |
| qa | qa | uint8 | 1 | 255.0 | NaN | {'qa': {'bits': [0, 1, 2, 3, 4, 5, 6, 7], 'val... |
Chargement des données de couverture fractionnelle pré-générées
Le FC a été calculé à partir de la réflectance de surface de la collection Landsat 2, à une résolution spatiale de 30 m. Le FC est généré à partir des satellites Landsat 5, 7 et 8. Leurs données sont combinées en un seul produit appelé « fc_ls ».
[6]:
#generate a query object from the analysis parameters
query = {
'time': time_period,
'x': lon_range,
'y': lat_range,
'output_crs': output_crs
}
[7]:
# load all available fc data
fc = dc.load(product='fc_ls',
resolution=(-30, 30),
collection_category='T1',
**query)
print(fc)
<xarray.Dataset>
Dimensions: (time: 46, y: 219, x: 194)
Coordinates:
* time (time) datetime64[ns] 2017-01-02T08:41:12.785718 ... 2017-10...
* y (y) float64 -3.825e+06 -3.825e+06 ... -3.831e+06 -3.831e+06
* x (x) float64 1.76e+06 1.76e+06 1.76e+06 ... 1.766e+06 1.766e+06
spatial_ref int32 6933
Data variables:
bs (time, y, x) uint8 0 0 0 0 0 0 0 ... 255 255 255 255 255 255
pv (time, y, x) uint8 82 82 82 82 82 82 ... 255 255 255 255 255
npv (time, y, x) uint8 22 22 22 22 22 22 ... 255 255 255 255 255
ue (time, y, x) uint8 6 6 6 6 6 6 6 ... 255 255 255 255 255 255
Attributes:
crs: epsg:6933
grid_mapping: spatial_ref
Masque de nuages et d’eau FC avec couches d’entités d’observations de l’eau depuis l’espace (WOfS)
L’algorithme de démixage s’effondre en présence d’eau ou de nuages. La « couche d’entités d’observations de l’eau » peut être utilisée pour exclure ces pixels problématiques. Pour plus d’informations sur le masquage de bits, consultez le bloc-notes « Applying WOfS bitmasking <../Frequently_used_code/Applying_WOfS_bitmasking.ipynb> ».
[8]:
# load WOFLs from the same spatio-temporal extent
wofls = dc.load(product='wofs_ls',
like=fc.geobox, #match extent of fc
time=query['time'],
collection_category='T1')
print(wofls)
<xarray.Dataset>
Dimensions: (time: 46, y: 219, x: 194)
Coordinates:
* time (time) datetime64[ns] 2017-01-02T08:41:12.785718 ... 2017-10...
* y (y) float64 -3.825e+06 -3.825e+06 ... -3.831e+06 -3.831e+06
* x (x) float64 1.76e+06 1.76e+06 1.76e+06 ... 1.766e+06 1.766e+06
spatial_ref int32 6933
Data variables:
water (time, y, x) uint8 64 64 64 64 64 64 64 64 ... 1 1 1 1 1 1 1 1
Attributes:
crs: PROJCS["WGS 84 / NSIDC EASE-Grid 2.0 Global",GEOGCS["WGS 8...
grid_mapping: spatial_ref
Créez un masque de pixels clair (sans nuage) et sec (sans eau)
[9]:
clear_and_dry = masking.make_mask(wofls, dry=True).water
#plot a subset of masks
clear_and_dry.isel(time=[0,1,2,3,4,5]).plot.imshow(col='time',col_wrap=6);

Si nous le souhaitons, nous pouvons conserver la plupart des scènes claires en calculant le nombre de bons pixels par scène et en appliquant un seuil
« min_gooddata » : fraction minimale de bonnes données requises pour qu’une scène (FC ou réflectance de surface) soit conservée
[10]:
#set a good data fraction
min_gooddata = 0.95
#keep only the images that are at least as clear as min_gooddata
good_slice = clear_and_dry.mean(['x','y']) >= min_gooddata
Nous pouvons maintenant appliquer le « masque transparent » et le filtre uniquement aux scènes qui sont pour la plupart exemptes de nuages et d’eau.
[11]:
fc_clear = fc.where(clear_and_dry).isel(time=good_slice)
print(fc_clear)
<xarray.Dataset>
Dimensions: (time: 10, y: 219, x: 194)
Coordinates:
* time (time) datetime64[ns] 2017-01-18T08:41:08.825013 ... 2017-10...
* y (y) float64 -3.825e+06 -3.825e+06 ... -3.831e+06 -3.831e+06
* x (x) float64 1.76e+06 1.76e+06 1.76e+06 ... 1.766e+06 1.766e+06
spatial_ref int32 6933
Data variables:
bs (time, y, x) float32 63.0 64.0 61.0 64.0 ... 64.0 68.0 68.0
pv (time, y, x) float32 2.0 0.0 0.0 2.0 0.0 ... 1.0 7.0 5.0 6.0
npv (time, y, x) float32 34.0 35.0 38.0 33.0 ... 27.0 25.0 25.0
ue (time, y, x) float32 6.0 6.0 6.0 6.0 6.0 ... 5.0 6.0 7.0 7.0
Attributes:
crs: epsg:6933
grid_mapping: spatial_ref
Tracé de la couverture fractionnaire
Nous pouvons représenter graphiquement chaque variable FC dans notre ensemble de données (c’est-à-dire « [“bs”, “pv”, “npv”] ») à l’aide de la fonction « rgb ». Cela créera une vue en fausses couleurs des données où les nuances de vert, de bleu et de rouge représentent des proportions variables de végétation et de couverture de sol nu :
Vert : végétation photosynthétique (verte) (« pv »)
Bleu : végétation non photosynthétique (c’est-à-dire « non verte ») (« npv »)
Rouge : sol nu (
'bs')
Le graphique de droite indique comment la composition des couleurs RVB peut être interprétée.
Dans la zone d’intérêt utilisée ici, les images résultantes montrent des champs agricoles contenant de fortes proportions de couverture végétale verte, entourés de zones dominées par une végétation brune et un sol nu.
[12]:
rgb(fc_clear,
col='time',
bands=['bs','pv','npv'],
col_wrap=5,
size=4)
/usr/local/lib/python3.10/dist-packages/matplotlib/cm.py:478: RuntimeWarning: invalid value encountered in cast
xx = (xx * 255).astype(np.uint8)
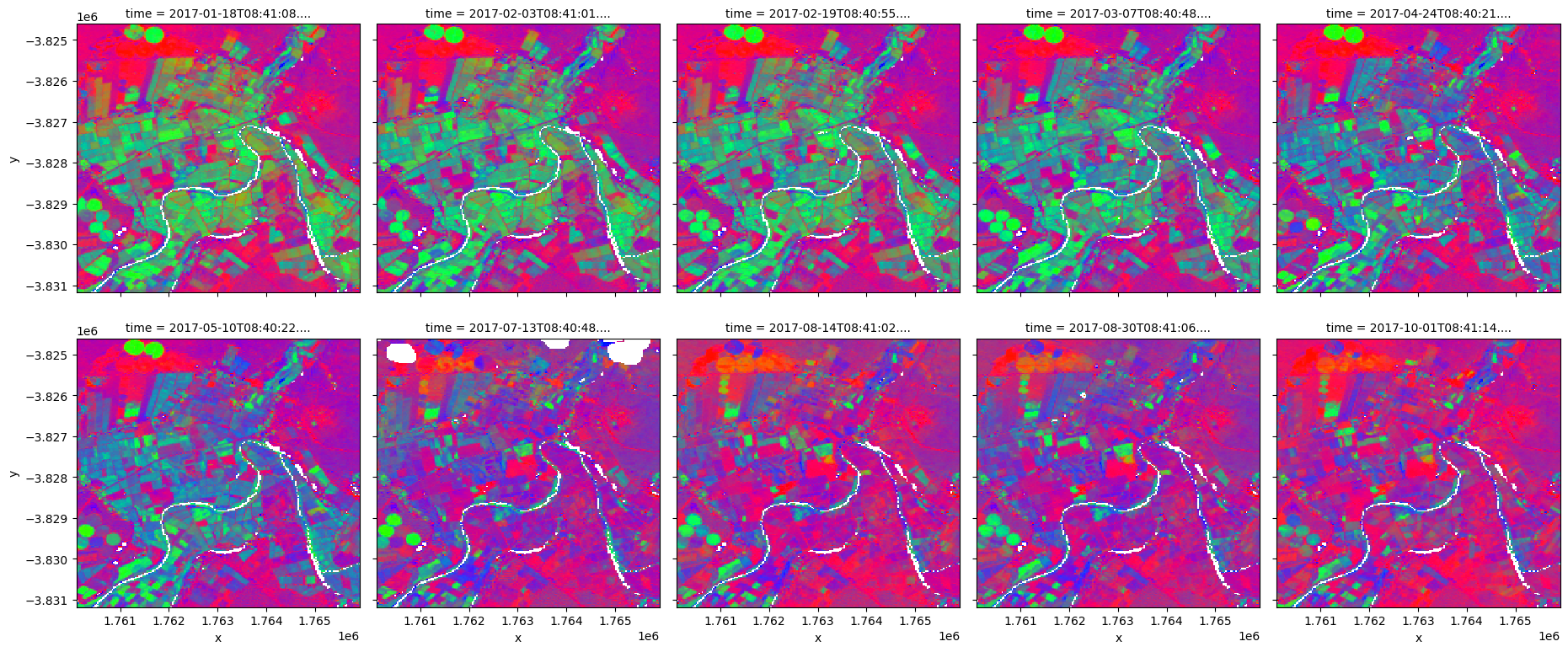
Inspection de l’erreur de démixage
Les valeurs de couverture fractionnelle varient entre 0 et 100 %, mais en raison des incertitudes du modèle et des limites des données d’apprentissage, certaines zones peuvent afficher des valeurs de couverture supérieures à 100 %. Ces zones peuvent être soit exclues, soit traitées comme équivalentes à 100 %.
Nous pouvons également visualiser l’erreur de démixage (ue) pour chacune de nos observations de couverture fractionnaire. Les valeurs d’erreur de démixage élevées (couleurs vives ci-dessous) représentent les zones d’incertitude plus élevée du modèle (par exemple, les zones d’eau, les nuages que nous n’avons pas masqués ou les types/couleurs de sol qui n’étaient pas inclus dans les données d’entraînement du modèle). Ces données peuvent être utiles pour supprimer les pixels incertains d’une analyse.
Dans cet exemple, les pixels humides associés à la rivière et aux pâturages irrigués présentent des erreurs de démixage relativement élevées. Un filtrage supplémentaire peut être effectué en exigeant que la somme des trois fractions soit proche de 100 % et/ou que l’erreur de démixage soit faible. Cependant, ces contraintes seules ne suffisent pas à exclure tous les résultats FC problématiques.
[13]:
# Plot unmixing error using `robust=True` to drop outliers and improve contrast
fc_clear.ue.plot(col='time', robust=True, col_wrap=5, size=4);
Exemple d’application : suivi des changements dans la couverture végétale et le sol nu au fil du temps
La section suivante illustre un flux de travail d’analyse simple basé sur la couverture fractionnaire. Dans cet exemple, nous traiterons nos données FC chargées afin de pouvoir suivre de manière cohérente l’évolution des proportions de végétation verte, de végétation brune et de sol nu au fil du temps.
La première étape consiste à charger FC, puis à masquer l’eau et les nuages, puis à filtrer les images pour qu’elles soient majoritairement claires. Heureusement, nous l’avons déjà fait ci-dessus. Nous imprimerons à nouveau nos données « fc_clear » pour nous rappeler le contenu des jeux de données
[14]:
print(fc_clear)
<xarray.Dataset>
Dimensions: (time: 10, y: 219, x: 194)
Coordinates:
* time (time) datetime64[ns] 2017-01-18T08:41:08.825013 ... 2017-10...
* y (y) float64 -3.825e+06 -3.825e+06 ... -3.831e+06 -3.831e+06
* x (x) float64 1.76e+06 1.76e+06 1.76e+06 ... 1.766e+06 1.766e+06
spatial_ref int32 6933
Data variables:
bs (time, y, x) float32 63.0 64.0 61.0 64.0 ... 64.0 68.0 68.0
pv (time, y, x) float32 2.0 0.0 0.0 2.0 0.0 ... 1.0 7.0 5.0 6.0
npv (time, y, x) float32 34.0 35.0 38.0 33.0 ... 27.0 25.0 25.0
ue (time, y, x) float32 6.0 6.0 6.0 6.0 6.0 ... 5.0 6.0 7.0 7.0
Attributes:
crs: epsg:6933
grid_mapping: spatial_ref
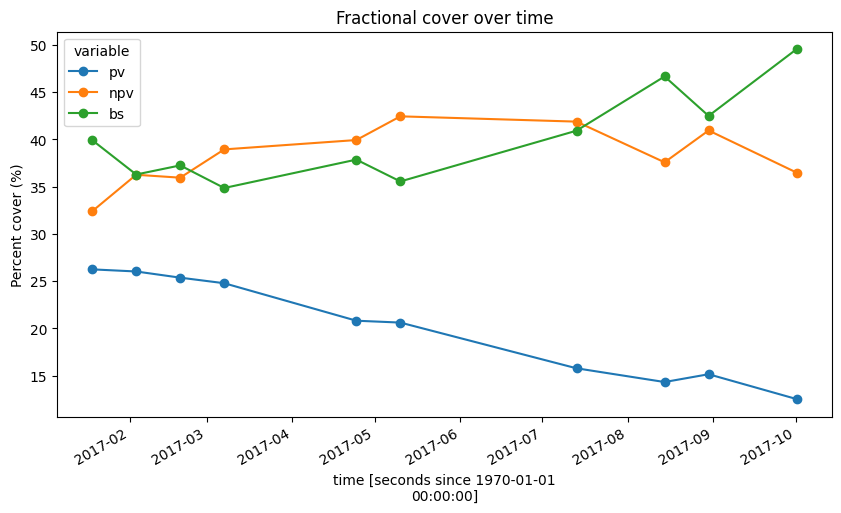
Calcul de la couverture fractionnaire moyenne au fil du temps
Maintenant que nos données FC ont des valeurs nodata et que les pixels de nuages, d’ombre et d’eau sont définis sur NaN, nous pouvons suivre de manière fiable l’évolution des proportions moyennes de végétation verte et brune et de sol nu au fil du temps sur l’ensemble de notre zone d’étude. Nous pouvons ensuite représenter cela sous forme de graphique linéaire, montrant que la végétation verte (pv) a constamment diminué au fil du temps à cet endroit, tandis que le sol nu (bs) a augmenté et que la végétation non photosynthétique (npv) a été relativement stable.
[15]:
# Calculate average fractional cover for `bs`, `pv` and `npv` over time
fc_through_time = fc_clear[['pv', 'npv', 'bs']].mean(dim=['x', 'y'])
# Plot the changing proportions as a line graph
fc_through_time.to_array().plot.line(hue='variable', figsize=(10,5), marker='o')
plt.title('Fractional cover over time')
plt.ylabel('Percent cover (%)');
Comprendre le résumé annuel du FC
Le produit récapitulatif annuel de couverture fractionnaire donne les valeurs de percentiles annuels pour chacune des trois fractions (pv, bs, npv).
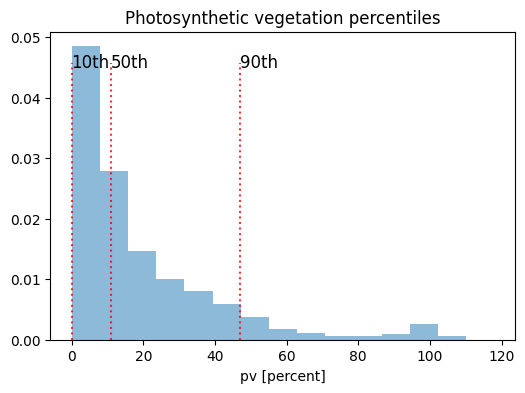
Cette idée est illustrée ci-dessous où nous traçons un histogramme des valeurs de pv pour la zone chargée ci-dessus, avec le % de pv sur l’axe des x et la densité sur l’axe des y. Nous pouvons voir que la distribution est positivement asymétrique car la plupart des valeurs sont comprises entre 0 % et 20 %. Les 10e, 50e et 90e percentiles sont représentés pour démontrer les informations disponibles dans le produit récapitulatif annuel. Dans ce cas, le 10e percentile pour pv est proche de 0 %, le 50e percentile est d’environ 11 % et le 90e percentile est d’environ 47 %.
Omettre les valeurs manquantes de l’ensemble de données
[16]:
fc_clear = fc.where(fc!= 255)
[17]:
fig, ax = plt.subplots(figsize = (6,4))
fc_clear.pv.plot(density = True, alpha = 0.5, bins = 15)
# Calculate percentiles
quant_values = fc_clear.pv.quantile([0.1, 0.5, 0.9])
# [quantile, opacity, length]
quants = [[quant_values[0], 0.8, 0.9], [quant_values[1], 0.8, 0.9], [quant_values[2], 0.8, 0.9]]
# Plot the lines
for i in quants:
ax.axvline(i[0], alpha = i[1], ymax = i[2], linestyle = ":", color = 'r')
ax.text(quant_values[0]-.1, 0.045, "10th", size = 12)
ax.text(quant_values[1]-.1, 0.045, "50th", size = 12)
ax.text(quant_values[2]-.1, 0.045, "90th", size = 12)
plt.title("Photosynthetic vegetation percentiles")
plt.show();
Charger le résumé annuel
Le résumé annuel peut être utilisé pour suivre les changements d’une année à l’autre.
[18]:
fc_summary = dc.load(product='fc_ls_summary_annual',
like=fc.geobox, #match extent of fc
time=('2018','2020'))
print(fc_summary)
<xarray.Dataset>
Dimensions: (time: 3, y: 219, x: 194)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999 ... 2020-07...
* y (y) float64 -3.825e+06 -3.825e+06 ... -3.831e+06 -3.831e+06
* x (x) float64 1.76e+06 1.76e+06 1.76e+06 ... 1.766e+06 1.766e+06
spatial_ref int32 6933
Data variables:
pv_pc_10 (time, y, x) uint8 0 0 0 0 0 0 0 0 0 0 ... 5 10 9 8 6 6 5 5 4 8
pv_pc_50 (time, y, x) uint8 2 3 3 2 4 2 2 3 ... 19 17 13 11 10 11 10 12
pv_pc_90 (time, y, x) uint8 20 17 18 18 17 16 18 ... 26 19 13 17 17 17
bs_pc_10 (time, y, x) uint8 41 43 36 33 42 44 44 ... 30 42 48 49 50 52
bs_pc_50 (time, y, x) uint8 55 56 55 54 56 57 58 ... 38 47 54 55 54 55
bs_pc_90 (time, y, x) uint8 63 64 63 61 63 65 65 ... 45 53 61 59 60 61
npv_pc_10 (time, y, x) uint8 28 28 31 30 28 29 28 ... 35 33 28 24 27 24
npv_pc_50 (time, y, x) uint8 37 39 38 39 39 39 38 ... 44 37 34 34 34 28
npv_pc_90 (time, y, x) uint8 46 49 47 48 45 46 47 ... 53 49 42 39 41 39
count_valid (time, y, x) int16 25 25 26 25 25 25 25 ... 26 27 27 27 28 28
qa (time, y, x) uint8 2 2 2 2 2 2 2 2 2 2 ... 2 2 2 2 2 2 2 2 2 2
Attributes:
crs: PROJCS["WGS 84 / NSIDC EASE-Grid 2.0 Global",GEOGCS["WGS 8...
grid_mapping: spatial_ref
Tracer et interpréter les percentiles récapitulatifs annuels
Pour chaque type de couverture, les 10e, 50e et 90e percentiles sont estimés à partir de toutes les mesures de fractions claires et valides d’une année civile. Comme indiqué ci-dessus, ces percentiles fournissent des estimations des valeurs basses, médianes et élevées d’une distribution qui sont robustes face aux valeurs aberrantes.
L’exemple ci-dessous montre les trois centiles de la fraction de couverture verte, qui peuvent servir de proxy pour la couverture verte minimale, typique et maximale pour une année donnée.
[19]:
fc_summary.isel(time=-1)[['pv_pc_10', 'pv_pc_50', 'pv_pc_90']].to_array(dim='band').plot.imshow(col='band', cmap='Greens', vmin=0, vmax=100, size=8);
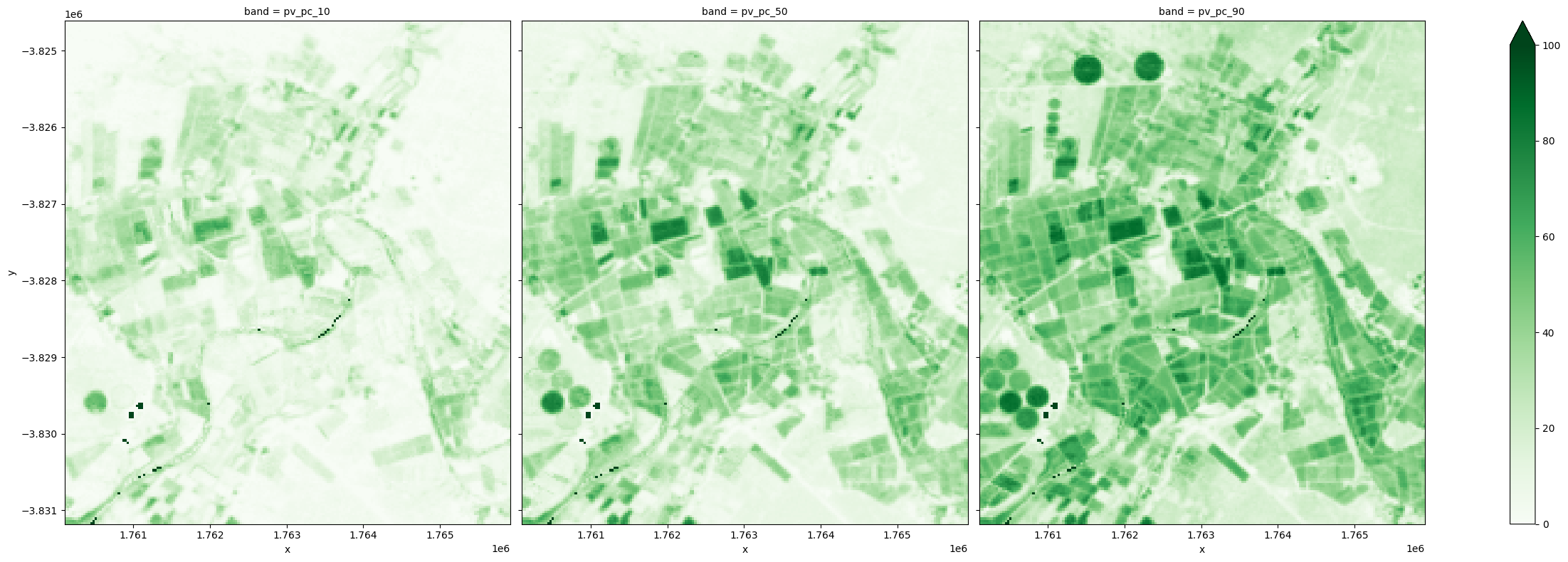
Étant donné que les percentiles sont estimés indépendamment pour les trois types de couverture, les 10e percentiles représentent la limite inférieure des mesures pour les trois couvertures, qui peuvent avoir été observées à différents moments de l’année. De même, les 90e percentiles représentent la limite supérieure des mesures pour les trois couvertures, qui peuvent avoir eu lieu à des moments différents. Ces valeurs de percentiles peuvent être utilisées séparément ou combinées pour comprendre la dynamique de la couverture terrestre.
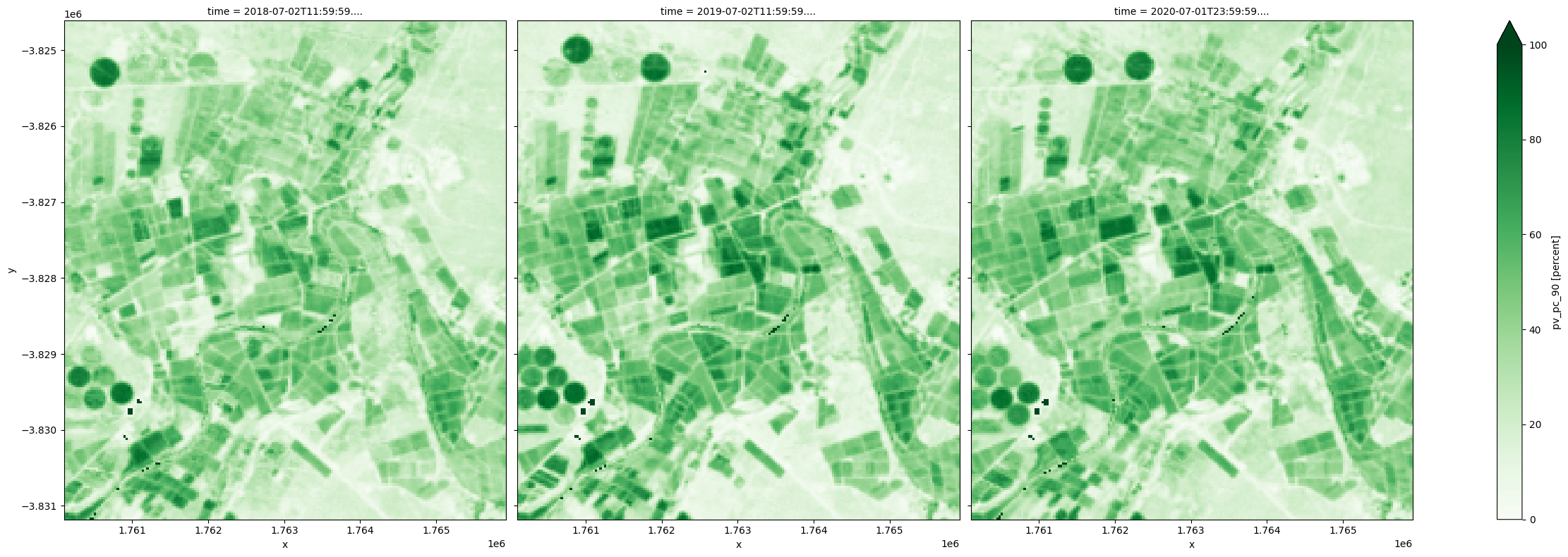
Par exemple, en utilisant le 90e percentile de la valeur actualisée comme indicateur de la fraction de couverture verte maximale observée au cours d’une année, les champs irrigués sont présentés ci-dessous comme ayant atteint la couverture verte maximale la plus élevée de toutes les années.
[20]:
fc_summary['pv_pc_90'].plot.imshow(col='time', cmap='Greens', vmin=0, vmax=100, size=8);
Le 10e percentile BS peut être utilisé comme indicateur de la fraction de sol nu la plus faible observée au cours d’une année.
[21]:
fc_summary['bs_pc_10'].plot.imshow(col='time', cmap='Reds', vmin=0, vmax=100, size=8);
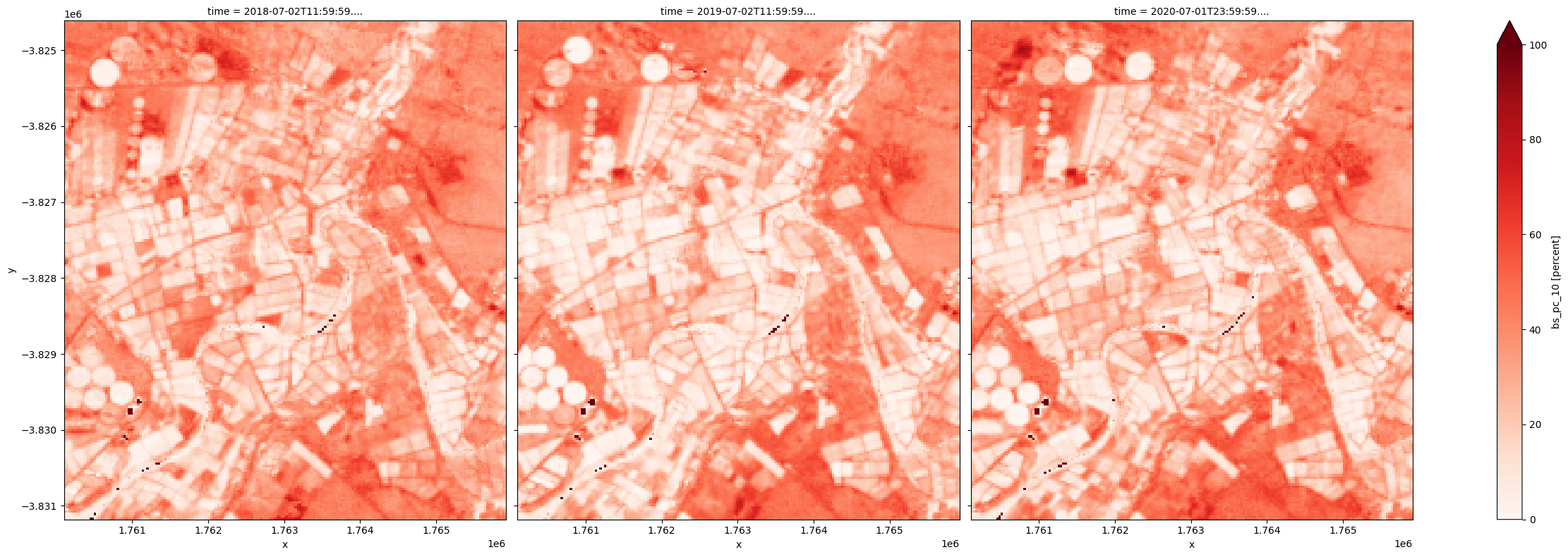
Étant donné qu’à tout moment, les trois couvertures totalisent 100 pour cent, la fraction de sol nu la plus faible peut être utilisée pour obtenir la couverture végétale totale la plus élevée.
[22]:
(100-fc_summary['bs_pc_10']).plot.imshow(col='time', cmap='Greens', vmin=0, vmax=100, size=8);
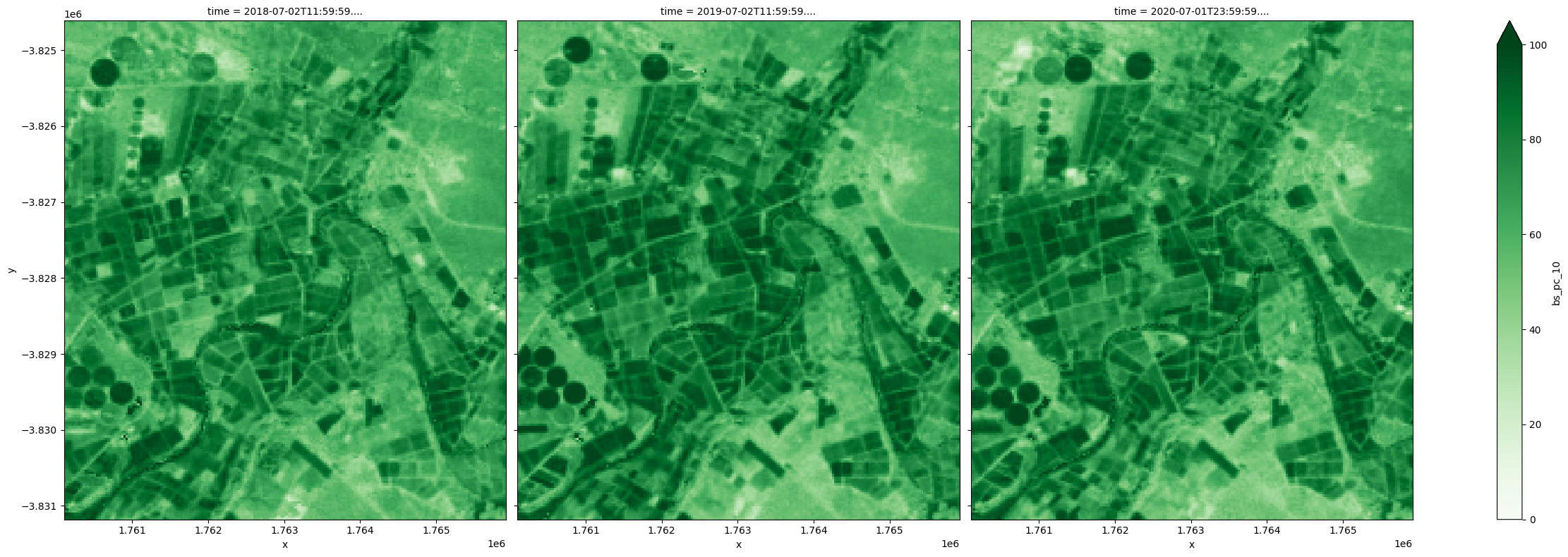
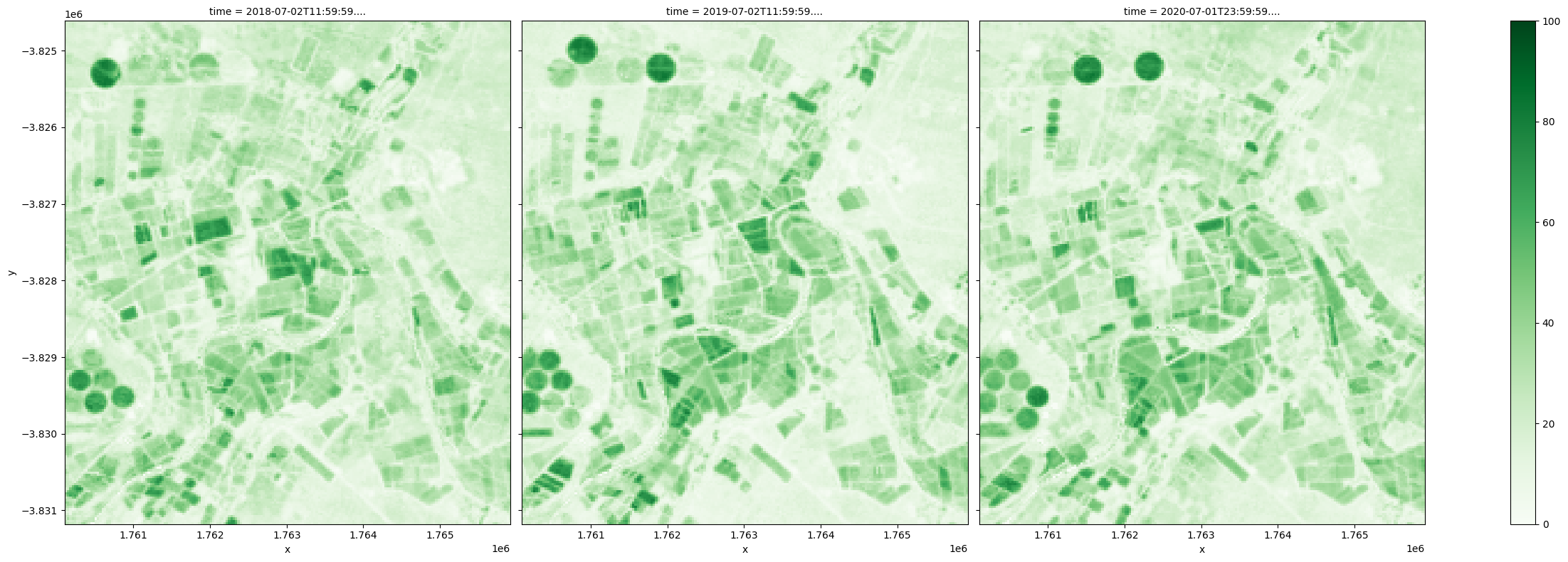
La différence entre les 10e et 90e percentiles fournit une estimation de l’ampleur du changement au cours d’une année. Dans cet exemple, une plus grande variation est observée dans les terres agricoles pour toutes les couvertures et, comme indiqué ci-dessous, les changements les plus significatifs dans la couverture végétale sont observés dans les champs irrigués.
[23]:
(fc_summary['pv_pc_90']-fc_summary['pv_pc_10']).plot.imshow(col='time', cmap='Greens', vmin=0, vmax=100, size=8);
Enfin, une vue représentative du paysage sur une année peut être obtenue en combinant les 50e percentiles, ou les valeurs médianes, pour les trois types de couverture. Les changements d’une année à l’autre peuvent être facilement visualisés, ce qui peut être particulièrement utile pour surveiller la végétation naturelle.
[24]:
rgb(fc_summary,
bands=['bs_pc_50','pv_pc_50','npv_pc_50'],
size=8, col='time');

Informations Complémentaires
Licence : Le code de ce carnet est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>. Les données de Digital Earth Africa sont sous licence Creative Commons par attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact : Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack Open Data Cube <http://slack.opendatacube.org/>`__ ou sur le GIS Stack Exchange en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment ici). Si vous souhaitez signaler un problème avec ce bloc-notes, vous pouvez en déposer un sur Github.
Version de Datacube compatible :
[25]:
print(datacube.__version__)
1.8.15
Dernier test :
[26]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[26]:
'2023-08-11'