Working with time in xarray
Products used: s2_l2a
Keywords analysis; time series, data used; sentinel-2, data methods; groupby,:index:data methods; nearest, index:data methods; interpolating, data methods; resampling, data methods; compositing
Background
Time series data is a series of data points usually captured at successively spaced points in time. In a remote-sensing context, time series data is a sequence of discrete satellite images taken at the same area at successive times. Time series analysis uses different methods to extract meaningful statistics, patterns and other characteristics of the data. Time series data and analysis has widespread application ranging from monitoring agricultural crops, natural vegetation change detection, mineral prospectivity mapping, and tidal height modelling.
Description
The xarray Python package provides many useful techniques for dealing with time series data that can be applied to Digital Earth Africa data. This notebook demonstrates how to use xarray techniques to:
Select different time periods of data (e.g. year, month, day) from an
xarray.DatasetUse datetime accessors to extract additional information from a dataset’s
timedimensionSummarise time series data for different time periods using
.groupby()and.resample()Interpolate time series data to estimate landscape conditions at a specific date that the satellite did not observe
For additional information about the techniques demonstrated below, refer to the xarray time series data guide.
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
Load packages
[1]:
%matplotlib inline
import datacube
import matplotlib.pyplot as plt
import numpy as np
import geopandas as gpd
from odc.geo.geom import Geometry
from deafrica_tools.datahandling import load_ard, mostcommon_crs
from deafrica_tools.areaofinterest import define_area
Connect to the datacube
[2]:
dc = datacube.Datacube(app='Working_with_time')
Loading Landsat data
First, we load in around two years’ of Sentinel-2 data, using the load_ard function and filtering for timesteps with at least 95% good-quality pixels.
To define the area of interest, there are two methods available:
By specifying the latitude, longitude, and buffer. This method requires you to input the central latitude, central longitude, and the buffer value in square degrees around the center point you want to analyze. For example,
lat = 10.338,lon = -1.055, andbuffer = 0.1will select an area with a radius of 0.1 square degrees around the point with coordinates (10.338, -1.055).By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
To use one of these methods, you can uncomment the relevant line of code and comment out the other one. To comment out a line, add the "#" symbol before the code you want to comment out. By default, the first option which defines the location using latitude, longitude, and buffer is being used.
[3]:
# Define the location
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=13.94, lon=-16.54, buffer=0.125)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
# aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# Create a reusable query
query = {
'x': lon_range,
'y': lat_range,
'time': ('2018-01', '2019-12'),
'resolution': (-20, 20),
'measurements':['red', 'green', 'blue', 'nir']
}
# Identify the most common projection system in the input query
output_crs = mostcommon_crs(dc=dc, product='s2_l2a', query=query)
# Load available data from Landsat 8 and filter to retain only times
# with at least 95% good data
ds = load_ard(dc=dc,
products=['s2_l2a'],
min_gooddata=0.95,
output_crs=output_crs,
align=(15, 15),
**query)
Using pixel quality parameters for Sentinel 2
Finding datasets
s2_l2a
Counting good quality pixels for each time step
Filtering to 43 out of 172 time steps with at least 95.0% good quality pixels
Applying pixel quality/cloud mask
Loading 43 time steps
Explore xarray data using time
Here we will explore several ways to utilise the time dimension within an xarray.Dataset. This section outlines selecting, summarising and interpolating data at specific times.
Indexing by time
We can select data for an entire year by passing a string to .sel():
[4]:
ds.sel(time='2018')
[4]:
<xarray.Dataset> Size: 455MB
Dimensions: (time: 15, y: 1392, x: 1361)
Coordinates:
* time (time) datetime64[ns] 120B 2018-01-08T11:46:56 ... 2018-12-1...
* y (y) float64 11kB 1.556e+06 1.556e+06 ... 1.528e+06 1.528e+06
* x (x) float64 11kB 3.2e+05 3.2e+05 ... 3.472e+05 3.472e+05
spatial_ref int32 4B 32628
Data variables:
red (time, y, x) float32 114MB 2.254e+03 1.988e+03 ... 1.747e+03
green (time, y, x) float32 114MB 1.502e+03 1.348e+03 ... 1.336e+03
blue (time, y, x) float32 114MB 815.0 742.0 ... 1.016e+03 1.002e+03
nir (time, y, x) float32 114MB 3.789e+03 3.519e+03 ... 2.496e+03
Attributes:
crs: epsg:32628
grid_mapping: spatial_refOr select a single month:
[5]:
ds.sel(time='2018-05')
[5]:
<xarray.Dataset> Size: 30MB
Dimensions: (time: 1, y: 1392, x: 1361)
Coordinates:
* time (time) datetime64[ns] 8B 2018-05-23T11:39:00
* y (y) float64 11kB 1.556e+06 1.556e+06 ... 1.528e+06 1.528e+06
* x (x) float64 11kB 3.2e+05 3.2e+05 ... 3.472e+05 3.472e+05
spatial_ref int32 4B 32628
Data variables:
red (time, y, x) float32 8MB 2.626e+03 2.49e+03 ... 1.988e+03
green (time, y, x) float32 8MB 1.895e+03 1.793e+03 ... 1.542e+03
blue (time, y, x) float32 8MB 1.112e+03 1.08e+03 ... 1.132e+03
nir (time, y, x) float32 8MB 3.536e+03 3.472e+03 ... 2.686e+03
Attributes:
crs: epsg:32628
grid_mapping: spatial_refOr select a range of dates using slice(). This selects all observations between the two dates, inclusive of both the start and stop values:
[6]:
ds.sel(time=slice('2018-06', '2019-01'))
[6]:
<xarray.Dataset> Size: 212MB
Dimensions: (time: 7, y: 1392, x: 1361)
Coordinates:
* time (time) datetime64[ns] 56B 2018-07-22T11:47:38 ... 2019-01-18...
* y (y) float64 11kB 1.556e+06 1.556e+06 ... 1.528e+06 1.528e+06
* x (x) float64 11kB 3.2e+05 3.2e+05 ... 3.472e+05 3.472e+05
spatial_ref int32 4B 32628
Data variables:
red (time, y, x) float32 53MB 2.233e+03 2.212e+03 ... 1.951e+03
green (time, y, x) float32 53MB 1.566e+03 1.525e+03 ... 1.409e+03
blue (time, y, x) float32 53MB 486.0 557.0 ... 1.016e+03 976.0
nir (time, y, x) float32 53MB 3.711e+03 3.922e+03 ... 2.792e+03
Attributes:
crs: epsg:32628
grid_mapping: spatial_refTo select the nearest time to a desired time value, we set it to use a nearest neighbour method, 'nearest'. We have to specify the time using a datetime object, otherwise xarray indexing assumes we are selecting a range, like the ds.sel(time='2018-05') month example above.
Here, we have picked a date at the start of December 2018. 'nearest' will find the observation closest to that date.
[7]:
target_time = np.datetime64('2018-12-01')
ds.sel(time=target_time, method='nearest')
[7]:
<xarray.Dataset> Size: 30MB
Dimensions: (y: 1392, x: 1361)
Coordinates:
time datetime64[ns] 8B 2018-12-09T11:47:28
* y (y) float64 11kB 1.556e+06 1.556e+06 ... 1.528e+06 1.528e+06
* x (x) float64 11kB 3.2e+05 3.2e+05 ... 3.472e+05 3.472e+05
spatial_ref int32 4B 32628
Data variables:
red (y, x) float32 8MB 2.376e+03 2.035e+03 ... 1.987e+03 1.938e+03
green (y, x) float32 8MB 1.61e+03 1.375e+03 ... 1.487e+03 1.416e+03
blue (y, x) float32 8MB 777.0 654.0 970.0 ... 1.051e+03 960.0
nir (y, x) float32 8MB 3.633e+03 3.515e+03 ... 2.866e+03 2.748e+03
Attributes:
crs: epsg:32628
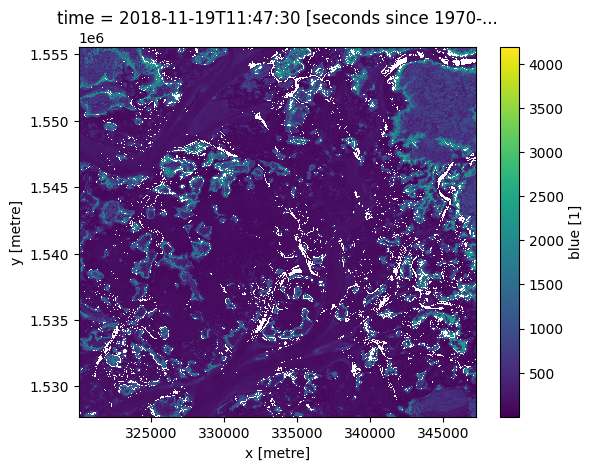
grid_mapping: spatial_refYou can select the closest time before a given time using ffill (forward-fill).
[8]:
previous_time = ds.sel(time=target_time, method='ffill')
previous_time.blue.plot();
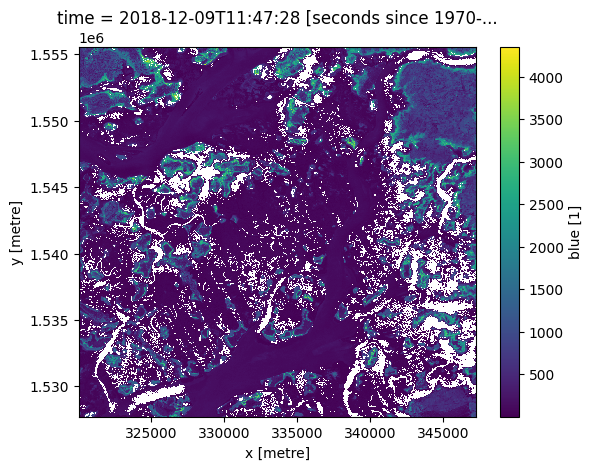
To select the closest time after a given time, use bfill (back-fill).
[9]:
next_time = ds.sel(time=target_time, method='bfill')
next_time.blue.plot()
[9]:
<matplotlib.collections.QuadMesh at 0x7fe3691f6e10>
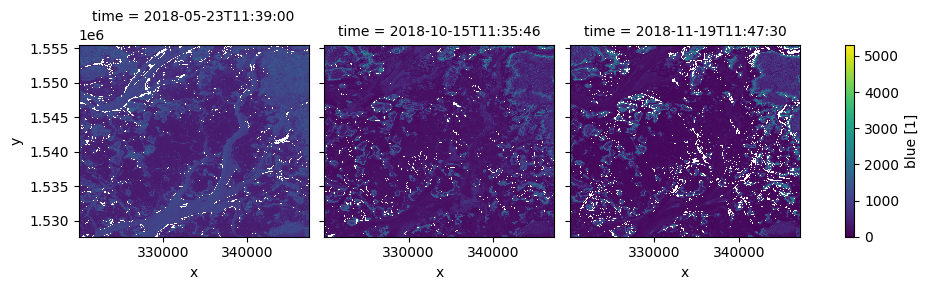
The same methods also work on a list of times:
[10]:
many_times = np.array([
'2018-06-23',
'2018-09-13',
'2018-11-02'
], dtype=np.datetime64)
nearest = ds.sel(time=many_times, method='nearest')
nearest.blue.plot(col='time', vmin=0);
Using the datetime accessor
xarray allows you to easily extract additional information from the time dimension in Digital Earth Africa data. For example, we can get a list of what season each observation belongs to:
[11]:
ds.time.dt.season
[11]:
<xarray.DataArray 'season' (time: 43)> Size: 516B
array(['DJF', 'DJF', 'DJF', 'DJF', 'DJF', 'MAM', 'MAM', 'MAM', 'MAM',
'MAM', 'JJA', 'SON', 'SON', 'DJF', 'DJF', 'DJF', 'DJF', 'DJF',
'DJF', 'MAM', 'MAM', 'MAM', 'MAM', 'MAM', 'MAM', 'MAM', 'MAM',
'MAM', 'MAM', 'MAM', 'MAM', 'MAM', 'MAM', 'JJA', 'JJA', 'JJA',
'SON', 'SON', 'SON', 'SON', 'SON', 'DJF', 'DJF'], dtype='<U3')
Coordinates:
* time (time) datetime64[ns] 344B 2018-01-08T11:46:56 ... 2019-12-2...
spatial_ref int32 4B 32628
Attributes:
units: seconds since 1970-01-01 00:00:00Or the day of the year:
[12]:
ds.time.dt.dayofyear
[12]:
<xarray.DataArray 'dayofyear' (time: 43)> Size: 344B
array([ 8, 8, 23, 48, 53, 63, 68, 73, 93, 143, 203, 288, 323,
343, 348, 3, 18, 43, 53, 68, 73, 83, 83, 98, 98, 103,
108, 108, 118, 123, 133, 143, 148, 158, 183, 188, 273, 293, 303,
328, 333, 353, 358])
Coordinates:
* time (time) datetime64[ns] 344B 2018-01-08T11:46:56 ... 2019-12-2...
spatial_ref int32 4B 32628
Attributes:
units: seconds since 1970-01-01 00:00:00Grouping and resampling by time
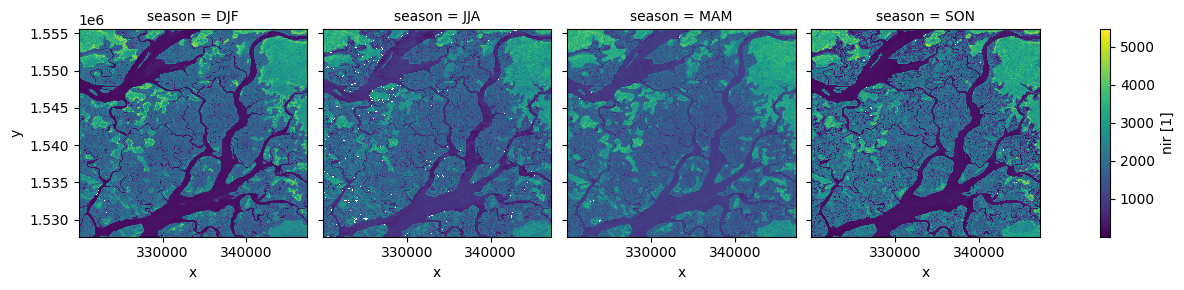
xarray also provides some shortcuts for aggregating data over time. In the example below, we first group our data by season, then take the median of each group. This produces a new dataset with only four observations (one per season).
[13]:
# Group the time series into seasons, and take median of each time period
ds_seasonal = ds.groupby('time.season').median(dim='time')
# Plot the output
ds_seasonal.nir.plot(col='season', col_wrap=4)
plt.show()
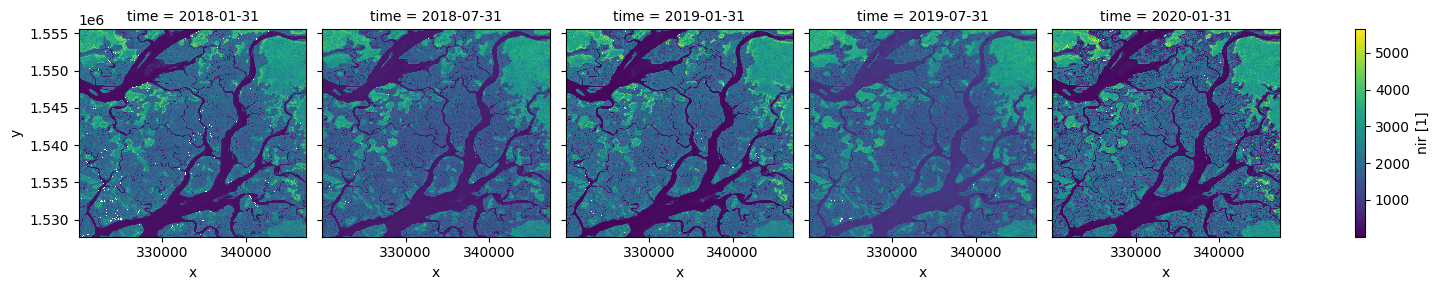
We can also use the .resample() method to summarise our dataset into larger chunks of time. In the example below, we produce a median composite for every 6 months of data in our dataset:
[14]:
# Resample to combine each 6 months of data into a median composite
ds_resampled = ds.resample(time="6m").median()
# Plot the new resampled data
ds_resampled.nir.plot(col="time")
plt.show()
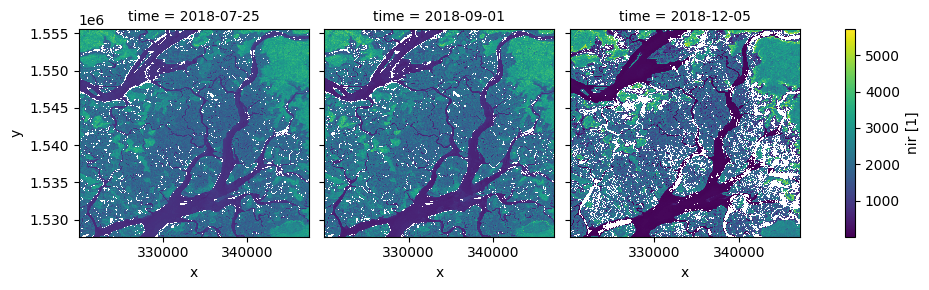
Interpolating new timesteps
Sometimes, we want to return data for specific times/dates that weren’t observed by a satellite. To estimate what the landscape appeared like on certain dates, we can use the .interp() method to interpolate between the nearest two observations.
By default, the interp() method uses linear interpolation (method='linear'). Another useful option is method='nearest', which will return the nearest satellite observation to the specified date(s).
[15]:
# New dates to interpolate data for
new_dates = ['2018-07-25', '2018-09-01', '2018-12-05']
# Interpolate Landsat values for three new dates
ds_interp = ds.interp(time=new_dates)
# Plot the new interpolated data
ds_interp.nir.plot(col='time')
plt.show()
Additional information
License:
The code in this notebook is licensed under the Apache License, Version 2.0.
Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact:
If you need assistance, please post a question on the Open Data Cube Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here). If you would like to report an issue with this notebook, you can file one on
Github.
Compatible datacube version:
[16]:
print(datacube.__version__)
1.8.20
Last Tested:
[17]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[17]:
'2025-01-15'