Integrating external data from a CSV
Products used: ls8_sr
Keywords data used; landsat 8, external data, data methods; interpolation, data used; csv, intertidal, coastal, water
Background
It is often useful to combine external data (e.g. from a CSV or other dataset) with data loaded from Digital Earth Africa. For example, we may want to combine data from a tide or river guage with satellite data to determine water levels at the exact moment each satellite observation was made. This can allow us to manipulate and extract satellite data and obtain additional insights using data from our external source.
Description
This example notebook loads in a time series of external tide modelling data from a CSV, and combines it with satellite data loaded from Digital Earth Africa. This workflow could be applied to any external time series dataset (e.g. river guages, tide guagues, rainfall measurements etc). The notebook demonstrates how to:
Load a time series of Landsat 8 data
Load in external time series data from a CSV
Convert this data to an
xarray.Datasetand link it to each satellite observation by interpolating values at each satellite timestepAdd this new data as a variable in our satellite dataset, and use this to filter satellite imagery to high and low tide imagery
Demonstrate how to swap dimensions between
timeand the newtide_heightvariable
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
Load packages
[1]:
%matplotlib inline
import datacube
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
from odc.geo.geom import Geometry
from deafrica_tools.datahandling import load_ard, mostcommon_crs
from deafrica_tools.areaofinterest import define_area
pd.plotting.register_matplotlib_converters()
Connect to the datacube
[2]:
dc = datacube.Datacube(app='Integrating_external_data')
Loading satellite data
First we load in three years of Landsat 8 data. We will use Msasani Bay in Tanzania for this demonstration, as we have a CSV of tide height data for this location that we wish to combine with satellite data. We load a single band nir which clearly differentiates between water (low values) and land (higher values). This will let us verify that we can use external tide data to identify low and high tide satellite observations.
To define the area of interest, there are two methods available:
By specifying the latitude, longitude, and buffer. This method requires you to input the central latitude, central longitude, and the buffer value in square degrees around the center point you want to analyze. For example,
lat = 10.338,lon = -1.055, andbuffer = 0.1will select an area with a radius of 0.1 square degrees around the point with coordinates (10.338, -1.055).By uploading a polygon as a
GeoJSON or Esri Shapefile. If you choose this option, you will need to upload the geojson or ESRI shapefile into the Sandbox using Upload Files button in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files
in the top left corner of the Jupyter Notebook interface. ESRI shapefiles must be uploaded with all the related files (.cpg, .dbf, .shp, .shx). Once uploaded, you can use the shapefile or geojson to define the area of interest. Remember to update the code to call the file you have uploaded.
To use one of these methods, you can uncomment the relevant line of code and comment out the other one. To comment out a line, add the "#" symbol before the code you want to comment out. By default, the first option which defines the location using latitude, longitude, and buffer is being used.
[3]:
# Set the area of interest
# Method 1: Specify the latitude, longitude, and buffer
aoi = define_area(lat=-6.745, lon=39.261, buffer=0.06)
# Method 2: Use a polygon as a GeoJSON or Esri Shapefile.
# aoi = define_area(vector_path='aoi.shp')
#Create a geopolygon and geodataframe of the area of interest
geopolygon = Geometry(aoi["features"][0]["geometry"], crs="epsg:4326")
geopolygon_gdf = gpd.GeoDataFrame(geometry=[geopolygon], crs=geopolygon.crs)
# Get the latitude and longitude range of the geopolygon
lat_range = (geopolygon_gdf.total_bounds[1], geopolygon_gdf.total_bounds[3])
lon_range = (geopolygon_gdf.total_bounds[0], geopolygon_gdf.total_bounds[2])
# Create a reusable query
query = {
'x': lon_range,
'y': lat_range,
'time': ('2015-01-01', '2017-12-31'),
'measurements': ['nir'],
'resolution': (-30, 30)
}
# Identify the most common projection system in the input query
output_crs = mostcommon_crs(dc=dc, product='ls8_sr', query=query)
# Load Landsat 8 data
ds = load_ard(dc=dc,
products=['ls8_sr'],
output_crs=output_crs,
align=(15, 15),
group_by='solar_day',
**query)
print(ds)
Using pixel quality parameters for USGS Collection 2
Finding datasets
ls8_sr
Applying pixel quality/cloud mask
Re-scaling Landsat C2 data
Loading 65 time steps
<xarray.Dataset> Size: 51MB
Dimensions: (time: 65, y: 443, x: 443)
Coordinates:
* time (time) datetime64[ns] 520B 2015-01-07T07:32:04.385652 ... 20...
* y (y) float64 4kB -7.389e+05 -7.39e+05 ... -7.522e+05 -7.522e+05
* x (x) float64 4kB 5.222e+05 5.222e+05 ... 5.354e+05 5.355e+05
spatial_ref int32 4B 32637
Data variables:
nir (time, y, x) float32 51MB nan nan nan ... 0.006718 0.006443
Attributes:
crs: epsg:32637
grid_mapping: spatial_ref
Integrating external data
Load in a CSV of external data with timestamps
In the code below, we aim to take a CSV file of external data (in this case, half-hourly tide heights for a location in Msasani Bay, Tanzania for a five year period between 2014 and 2018 generated using the OTPS TPXO8 tidal model), and link this data back to our satellite data timeseries.
We can load the existing tide height data using the pandas module which we imported earlier. The data has a column of time values, which we will set as the index column (roughly equivelent to a dimension in xarray).
[4]:
tide_data = pd.read_csv('../Supplementary_data/Integrating_external_data/msasani_bay_-6.749102_39.261819_2014-2018_tides.csv',
parse_dates=['time'],
index_col='time')
tide_data.head()
[4]:
| tide_height | |
|---|---|
| time | |
| 2014-01-01 00:00:00 | 1.798 |
| 2014-01-01 00:30:00 | 1.885 |
| 2014-01-01 01:00:00 | 1.867 |
| 2014-01-01 01:30:00 | 1.743 |
| 2014-01-01 02:00:00 | 1.521 |
Link external data to satellite data
Now that we have the tide height data, we need to estimate the tide height for each of our satellite images. We can do this by interpolating between the data points we do have (hourly measurements) to get an estimated tide height for the exact moment each satellite image was taken.
The code below generates an xarray.Dataset with the same number of timesteps as the original satellite data. The dataset has a single variable tide_height that gives the estimated tide hight for each observation:
[5]:
# First, we convert the data to an xarray dataset so we can analyse it
# in the same way as our satellite data
tide_data_xr = tide_data.to_xarray()
# We want to convert our hourly tide heights to estimates of exactly how
# high the tide was at the time that each satellite image was taken. To
# do this, we can use `.interp` to 'interpolate' a tide height for each
# satellite timestamp:
satellite_tideheights = tide_data_xr.interp(time=ds.time)
# Print the output xarray object
print(satellite_tideheights)
<xarray.Dataset> Size: 1kB
Dimensions: (time: 65)
Coordinates:
* time (time) datetime64[ns] 520B 2015-01-07T07:32:04.385652 ... 20...
spatial_ref int32 4B 32637
Data variables:
tide_height (time) float64 520B -1.401 -1.382 -0.7692 ... -0.2992 -0.3579
Now we have our tide heights in xarray format that matches our satellite data, we can add this back into our satellite dataset as a new variable:
[6]:
# We then want to put these values back into the Landsat dataset so
# that each image has an estimated tide height:
ds['tide_height'] = satellite_tideheights.tide_height
We can now plot tide heights for our satellite data:
[7]:
# Plot the resulting tide heights for each Landsat image:
ds.tide_height.plot()
plt.show()
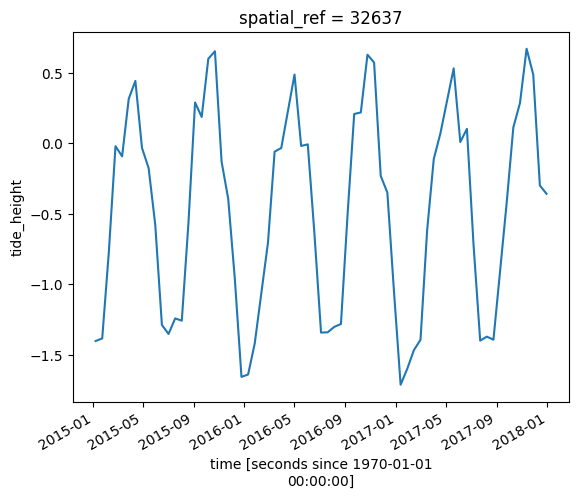
Filtering by external data
Now that we have a new variable tide_height in our dataset, we can use xarray indexing methods to manipulate our data using tide heights (e.g. filter by tide to select low or high tide images):
[8]:
# Select a subset of low tide images (tide less than -1.0 m)
low_tide_ds = ds.sel(time = ds.tide_height < -1.0)
# Select a subset of high tide images (tide greater than 0.1 m)
high_tide_ds = ds.sel(time = ds.tide_height > 0.1)
We can plot the median of the filtered images for low and high tide to examine the difference between them. Taking the median allows us to view a cloud-free image.
For the low-tide images:
[9]:
# Compute the median of all low tide images to produce a single cloud free image.
low_tide_composite = low_tide_ds.median(dim='time', skipna=True, keep_attrs=False)
# Plot the median low tide image
low_tide_composite.nir.plot(robust=True)
plt.title('Low tide')
plt.show()
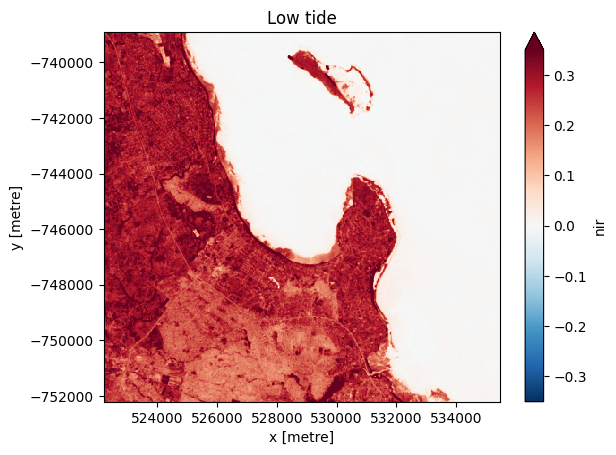
and for the high-tide images:
[10]:
# Compute the median of all high tide images to produce a single cloud free image.
high_tide_composite = high_tide_ds.median(dim='time', skipna=True, keep_attrs=False)
# Plot the median high tide image
high_tide_composite.nir.plot(robust=True)
plt.title('High tide')
plt.show()
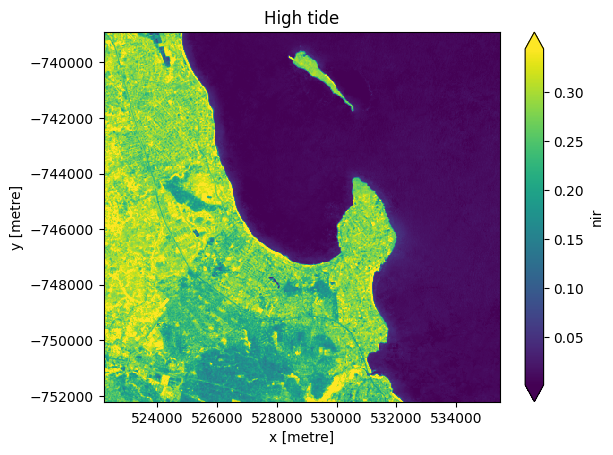
Note that many tidal flat areas in the low-tide image (blue-green) now appear inundated by water (dark blue/purple) in the high-tide image.
Swapping dimensions based on external data
By default, xarray uses time as one of the main dimensions in the dataset (in addition to x and y). Now that we have a new tide_height variable, we can change this to be an actual dimension in the dataset in place of time. This enables additional more advanced operations, such as calculating rolling statistics or aggregating by tide_heights.
In the example below, you can see that the dataset now has three dimensions (tide_height, x and y). The dimension time is no longer a dimension in the dataset.
[11]:
print(ds.swap_dims({'time': 'tide_height'}))
<xarray.Dataset> Size: 51MB
Dimensions: (tide_height: 65, y: 443, x: 443)
Coordinates:
time (tide_height) datetime64[ns] 520B 2015-01-07T07:32:04.385652...
* y (y) float64 4kB -7.389e+05 -7.39e+05 ... -7.522e+05 -7.522e+05
* x (x) float64 4kB 5.222e+05 5.222e+05 ... 5.354e+05 5.355e+05
spatial_ref int32 4B 32637
* tide_height (tide_height) float64 520B -1.401 -1.382 ... -0.2992 -0.3579
Data variables:
nir (tide_height, y, x) float32 51MB nan nan ... 0.006718 0.006443
Attributes:
crs: epsg:32637
grid_mapping: spatial_ref
Additional information
License: The code in this notebook is licensed under the Apache License, Version 2.0. Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact: If you need assistance, please post a question on the Open Data Cube Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here). If you would like to report an issue with this notebook, you can file one on
Github.
Compatible datacube version:
[12]:
print(datacube.__version__)
1.8.20
Last Tested:
[13]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[13]:
'2025-01-15'