Opérations paresseuses
Dans cette section, vous chargerez les données de manière différée, visualiserez le graphique des tâches pendant le chargement des données et utiliserez .compute() pour calculer une nouvelle bande NDVI à l’aide des bandes rouge et nir.
Charger des paquets
[1]:
import datacube
import matplotlib.pyplot as plt
from deafrica_tools.dask import create_local_dask_cluster
from deafrica_tools.plotting import rgb, display_map
/usr/local/lib/python3.8/dist-packages/geopandas/_compat.py:112: UserWarning: The Shapely GEOS version (3.8.0-CAPI-1.13.1 ) is incompatible with the GEOS version PyGEOS was compiled with (3.10.3-CAPI-1.16.1). Conversions between both will be slow.
warnings.warn(
Connexion au datacube
[2]:
dc = datacube.Datacube(app='Step2')
Chargement différé des données
[3]:
lazy_data = dc.load(product='gm_s2_annual',
measurements=['blue','green','red','nir'],
x=(31.90, 32.00),
y=(30.49, 30.40),
time=('2021-01-01', '2021-12-31'),
dask_chunks={'time':1,'x':500, 'y':500})
lazy_data
[3]:
<xarray.Dataset>
Dimensions: (time: 1, y: 994, x: 965)
Coordinates:
* time (time) datetime64[ns] 2021-07-02T11:59:59.999999
* y (y) float64 3.713e+06 3.713e+06 ... 3.703e+06 3.703e+06
* x (x) float64 3.078e+06 3.078e+06 ... 3.088e+06 3.088e+06
spatial_ref int32 6933
Data variables:
blue (time, y, x) uint16 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
green (time, y, x) uint16 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
red (time, y, x) uint16 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
nir (time, y, x) uint16 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_refAffichage du graphique des tâches
[4]:
lazy_data.red.data.visualize()
[4]:
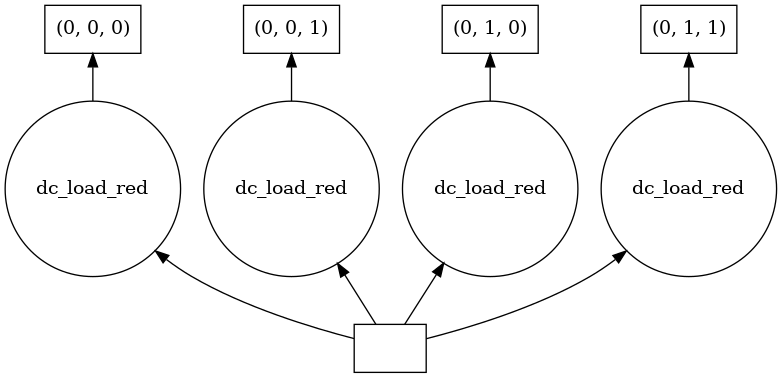
En demandant une petite partie de la bande rouge, nous pouvons utiliser .visualize() pour nous montrer d’où proviennent les données dans l’ensemble de données.
[5]:
extract_from_red = lazy_data.red[:, 100:200, 100:200]
extract_from_red.data.visualize()
[5]:
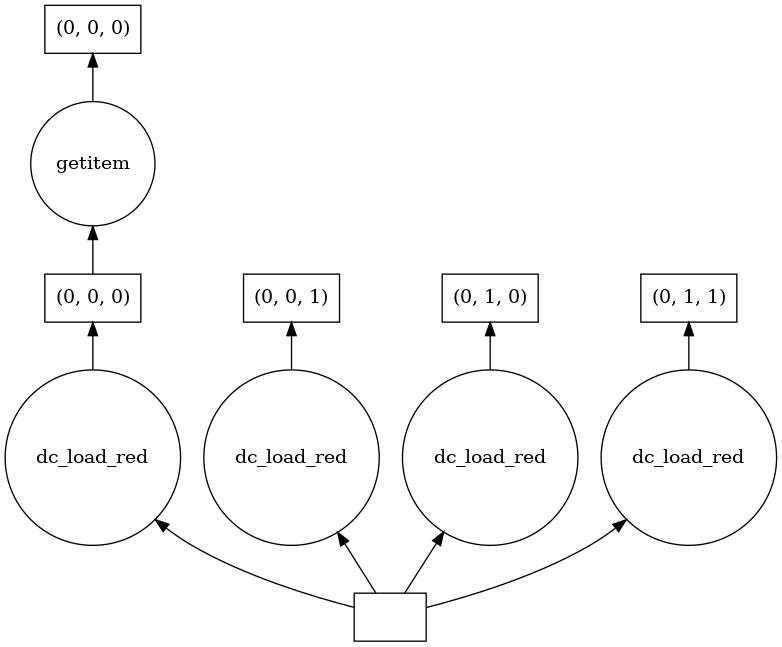
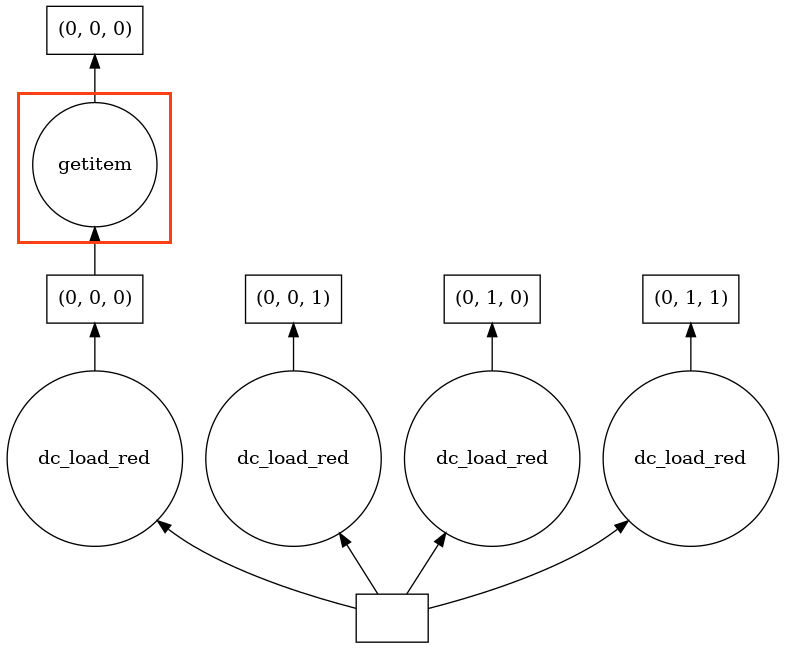
La nouvelle tâche « getitem » a été ajoutée au graphique des tâches, Dask a tracé l’opération à travers le graphique pour trouver uniquement la petite partie pertinente de la bande rouge que nous avons demandée.
Plusieurs tâches à l’aide de .compute()
Dans cette section, vous allez enchaîner plusieurs étapes pour calculer une nouvelle bande pour le tableau de données. À l’aide des bandes rouge et nir, nous allons calculer l’indice de végétation par différence normalisée (NDVI).
[6]:
# calcualte NDVI using red and nir bands from array
band_diff = lazy_data.nir - lazy_data.red
band_sum = lazy_data.nir + lazy_data.red
# added ndvi dask array to the lazy_data dataset
lazy_data['ndvi'] = band_diff / band_sum
[7]:
# return the dataset
lazy_data
[7]:
<xarray.Dataset>
Dimensions: (time: 1, y: 994, x: 965)
Coordinates:
* time (time) datetime64[ns] 2021-07-02T11:59:59.999999
* y (y) float64 3.713e+06 3.713e+06 ... 3.703e+06 3.703e+06
* x (x) float64 3.078e+06 3.078e+06 ... 3.088e+06 3.088e+06
spatial_ref int32 6933
Data variables:
blue (time, y, x) uint16 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
green (time, y, x) uint16 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
red (time, y, x) uint16 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
nir (time, y, x) uint16 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
ndvi (time, y, x) float64 dask.array<chunksize=(1, 500, 500), meta=np.ndarray>
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref[8]:
lazy_data.ndvi.data.visualize()
[8]:
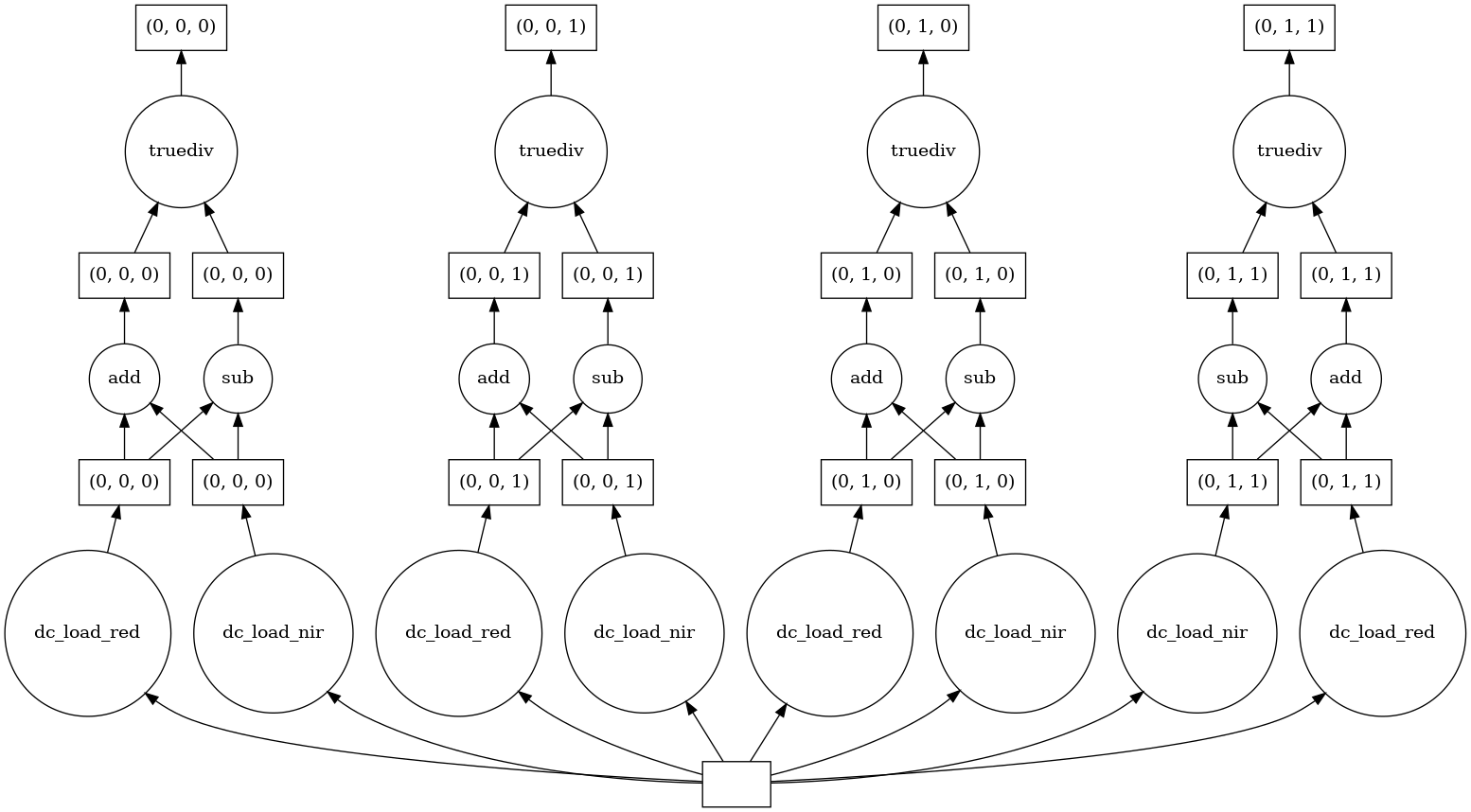
En visualisant le graphique des tâches, nous pouvons maintenant voir l’équation NDVI se dérouler à l’aide des bandes rouges et nir.
[9]:
ndvi_compute = lazy_data.ndvi.compute()
ndvi_compute
[9]:
<xarray.DataArray 'ndvi' (time: 1, y: 994, x: 965)>
array([[[0.21233616, 0.22875197, 0.20402869, ..., 0.42343153,
0.43450479, 0.44335088],
[0.18732949, 0.17376331, 0.1571875 , ..., 0.42226188,
0.42863595, 0.42960126],
[0.14910835, 0.13579444, 0.13274021, ..., 0.4057494 ,
0.40607127, 0.40859978],
...,
[0.08340284, 0.08749299, 0.0806496 , ..., 0.07265774,
0.0716137 , 0.07172075],
[0.07943476, 0.08121411, 0.07702721, ..., 0.07300463,
0.07278139, 0.07266811],
[0.0769853 , 0.07870933, 0.07785888, ..., 0.07255089,
0.07342045, 0.07429341]]])
Coordinates:
* time (time) datetime64[ns] 2021-07-02T11:59:59.999999
* y (y) float64 3.713e+06 3.713e+06 ... 3.703e+06 3.703e+06
* x (x) float64 3.078e+06 3.078e+06 ... 3.088e+06 3.088e+06
spatial_ref int32 6933Tracé du NDVI
[10]:
# formatting the figure
fig , axis = plt.subplots(1, 1, figsize=(6, 6))
axis.set_aspect('equal')
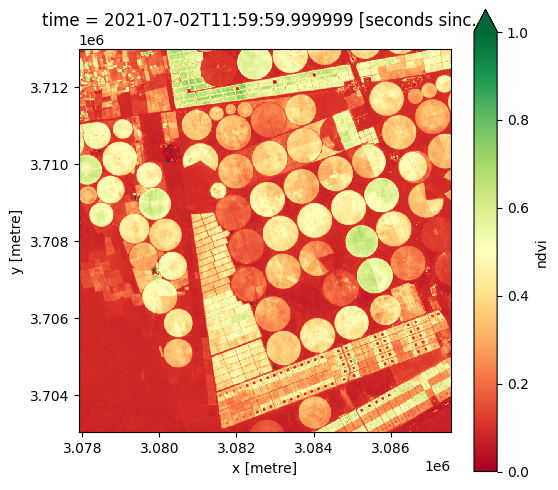
ndvi_compute.plot(ax= axis, cmap='RdYlGn', vmin=0, vmax=1)
[10]:
<matplotlib.collections.QuadMesh at 0x7facd03da8e0>
Concepts clés
Dask charge uniquement les données requises/utilisées par l’opération finale de la chaîne, les graphiques de tâches sont utilisés pour visualiser d’où proviennent les données requises
Les graphiques de tâches sont une représentation visuelle de la série d’étapes nécessaires à l’exécution d’une opération de chargement.
Les rectangles en bas du graphique sont des entrées de base de données qui représentent les blocs qui doivent être lus pour charger les données
Les cercles au-dessus des rectangles sont des opérations individuelles qui effectueront la lecture, il y en a un pour chaque bloc
Les index sont situés tout en haut des blocs qui composent le tableau final
Dans ce tutoriel, nous avons utilisé
.compute()pour calculer le NDVI et conserver spécifiquement la variable de données ndvi sous forme de tableau Dask dans lazy_load xarray.datasetndvi_compute=lazy_data.compute()chargera les données en mémoire pourndvi_compute, maislazy_datarestera paresseux
Informations complémentaires
Opérations paresseuses
En plus de diviser les données en morceaux plus petits qui tiennent dans la mémoire, Dask présente un autre avantage : il peut suivre la manière dont vous souhaitez travailler avec les données et, à partir de là, effectuer uniquement les opérations nécessaires ultérieurement.
Graphiques de tâches
Les graphiques de tâches représentent visuellement la série d’étapes nécessaires à l’exécution d’une opération de chargement. Les graphiques de tâches se lisent de bas en haut (voir ci-dessous) :
Les rectangles en bas du graphique sont des entrées de base de données qui représentent les fichiers qui doivent être lus pour charger les données
Les cercles au-dessus des rectangles sont des commandes de chargement individuelles qui effectueront la lecture, il y en a une pour chaque bloc
Les flèches représentent les fichiers qui doivent être lus pour chaque opération
Les index sont situés tout en haut des blocs qui composent le tableau final
Ajout de tâches
Avant de demander le chargement des données à l’aide de Dask, les tâches peuvent être enchaînées avant le chargement. Il s’agit d’une méthode avantageuse car seules les données requises par l’opération finale sont chargées.
Interprétation du graphique des tâches
Dans l’exemple ci-dessus, nous avons renvoyé des graphiques de tâches à deux points différents de chargement des données.
Demande d’une petite partie de la bande rouge : ce qui entraîne l’ajout de la nouvelle tâche « getitem », car c’est là que réside la petite partie de la bande rouge que nous avons demandée
Enchaînement des opérations pour calculer le NDVI : cela a entraîné l’exécution de « add » et « sub » sur chaque bande avant la division « truediv »
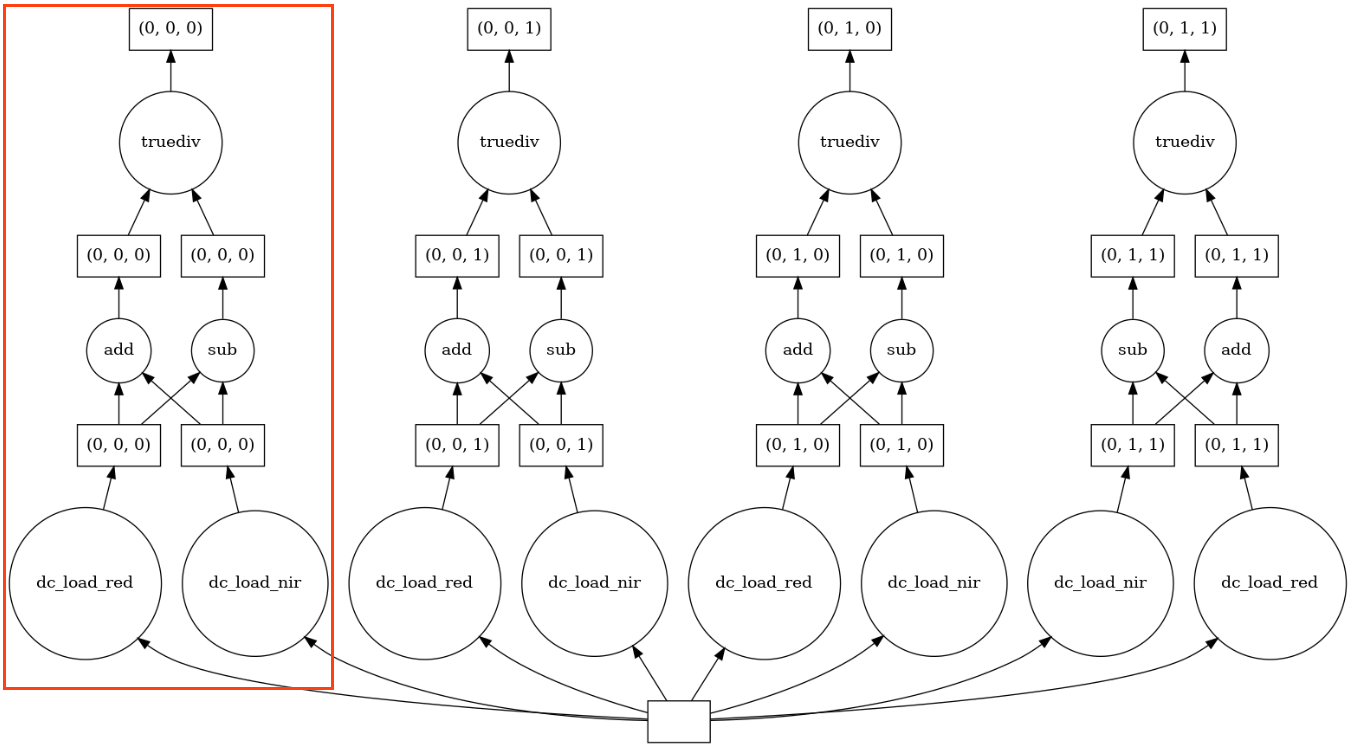
Nous pouvons voir comment chaque segment de sortie est indépendant des autres. Cela permet de calculer chaque segment sans avoir à charger toutes les bandes en mémoire en même temps.