Traitement parallèle avec Dask
Produits utilisés : gm_s2_annual
Prérequis : Les utilisateurs de ce notebook doivent avoir une compréhension de base de :
Comment exécuter un Jupyter notebook
Inspection des produits et mesures disponibles en Afrique DE <02_Products_and_measurements.ipynb>`__
Comment charger des données depuis DE Africa <03_Loading_data.ipynb>`__
Comment tracer les données chargées
Comment exécuter une analyse de base <05_Basic_analysis.ipynb>`__
Mots-clés guide du débutant ; traitement parallèle, traitement parallèle ; dask, traitement parallèle ; guide du débutant, données utilisées ; géomédiane Landsat 8, paquet python ; dask
Aperçu
Dask est un outil utile pour travailler sur des analyses de grande envergure (dans l’espace ou dans le temps) car il divise les données en morceaux gérables qui peuvent être facilement stockés en mémoire. Il peut également utiliser plusieurs cœurs de calcul pour accélérer les calculs. Cela présente de nombreux avantages pour les analyses, qui seront abordés dans ce bloc-notes.
Description
Ce bloc-notes explique comment activer Dask dans le cadre du chargement des données, ce qui peut vous permettre d’analyser des zones plus vastes et des périodes plus longues sans planter l’environnement DE Africa, tout en accélérant potentiellement vos calculs.
Les sujets abordés dans ce carnet incluent :
La différence entre la commande de chargement standard et le chargement avec Dask.
Activation de Dask et du tableau de bord Dask.
Définition des tailles de blocs pour le chargement des données.
Chargement de données avec Dask.
Enchaîner les opérations avant de charger des données et comprendre les graphiques de tâches.
Commencer
Pour exécuter cette introduction à Dask, exécutez toutes les cellules du bloc-notes en commençant par la cellule « Charger les packages ». Pour obtenir de l’aide sur l’exécution des cellules du bloc-notes, reportez-vous au bloc-notes Jupyter Notebooks.
Charger des paquets
La cellule ci-dessous importe le package « datacube », qui inclut déjà la fonctionnalité Dask. Le package « deafrica_tools » donne accès à des fonctions de support utiles dans le module « dask », en particulier la fonction « create_local_dask_cluster ».
[1]:
import datacube
from deafrica_tools.dask import create_local_dask_cluster
Se connecter au datacube
L’étape suivante consiste à se connecter à la base de données datacube. L’objet datacube « dc » résultant peut alors être utilisé pour charger des données. Le paramètre « app » est un nom unique utilisé pour identifier le bloc-notes qui n’a aucun effet sur l’analyse.
[2]:
dc = datacube.Datacube(app="08_parallel_processing_with_dask")
Charge standard
Par défaut, la bibliothèque « datacube » n’utilisera pas Dask lors du chargement des données. Cela signifie que lorsque « dc.load() » est utilisé, toutes les données relatives à la requête de chargement seront demandées et chargées en mémoire.
Pour des zones très vastes ou des périodes de temps longues, cela peut provoquer le blocage du notebook Jupyter.
Pour plus d’informations sur l’utilisation de dc.load(), consultez le bloc-notes Chargement de données à partir de DE Africa. Ci-dessous, nous montrons un exemple de chargement standard :
[3]:
data = dc.load(product='gm_s2_annual',
measurements=['red', 'green', 'blue'],
x=(24, 25.5),
y=(-21.5, -20),
time=("2018-01-01", "2018-12-31"))
data
[3]:
<xarray.Dataset>
Dimensions: (time: 1, y: 17925, x: 14473)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 1083 1139 1208 1219 ... 1585 1687 1641 1596
green (time, y, x) uint16 900 934 992 1001 ... 1102 1176 1154 1131
blue (time, y, x) uint16 668 701 753 761 774 ... 686 727 766 759 726
Attributes:
crs: epsg:6933
grid_mapping: spatial_refActivation de Dask
L’une des principales caractéristiques de Dask est qu’il peut tirer parti de plusieurs cœurs de processeur pour accélérer les calculs, ce que l’on appelle le calcul distribué. Cela est utile dans les situations où vous devez effectuer de nombreux calculs sur de grands ensembles de données.
Pour configurer le calcul distribué avec Dask, vous devez d’abord configurer un client Dask à l’aide de la fonction ci-dessous :
[ ]:
create_local_dask_cluster()
Une impression devrait apparaître, affichant des informations sur le « Client » et le « Cluster ». Pour l’instant, nous sommes plus intéressés par le lien hypertexte après l’en-tête Tableau de bord :, qui devrait ressembler à /user/<email>/proxy/8787/status, où <email> est votre e-mail pour DE Africa Sandbox.
Ce lien vous permet de visualiser la progression des calculs que vous exécutez. Il existe deux façons d’afficher le tableau de bord :
Cliquez sur le lien, qui ouvrira un nouvel onglet dans votre navigateur
Configurer le tableau de bord au sein de l’environnement DE Africa.
Nous allons maintenant voir comment réaliser la deuxième option.
Tableau de bord Dask en Afrique de l’Est
Dans la barre de menu de gauche, cliquez sur l’icône Dask, comme indiqué ci-dessous :
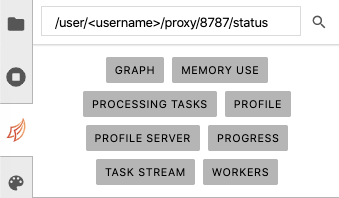
Copiez et collez le lien Tableau de bord de l’impression client dans la zone de texte URL du TABLEAU DE BORD DASK :
Si l’URL est valide, les boutons devraient passer du gris à l’orange. Cliquez sur le bouton orange PROGRESS sur le panneau de contrôle, ce qui ouvrira un nouvel onglet dans l’environnement DE Africa.
Pour afficher la fenêtre Dask et votre bloc-notes actif en même temps, faites glisser le nouvel onglet Progression de Dask vers le bas de l’écran.
Désormais, lorsque vous effectuez des calculs avec Dask, vous verrez la progression des calculs dans cette nouvelle fenêtre Dask.
Chargement paresseux
Lors de l’utilisation de Dask, la fonction « dc.load() » passe du chargement immédiat des données au « chargement différé » des données. Cela signifie que les données ne sont chargées que lorsqu’elles doivent être utilisées pour un calcul, ce qui permet potentiellement d’économiser du temps et de la mémoire.
Le chargement différé modifie la structure de données renvoyée par la commande « dc.load() » : le « xarray.Dataset » renvoyé sera composé d’objets « dask.array ».
Pour demander des données chargées de manière différée, ajoutez un paramètre « dask_chunks » à votre appel « dc.load() » :
[5]:
lazy_data = dc.load(product='gm_s2_annual',
measurements=['red', 'green', 'blue'],
x=(24, 25.5),
y=(-21.5, -20),
time=("2018-01-01", "2018-12-31"),
dask_chunks={'time': 1, 'x': 3000, 'y': 3000})
lazy_data
[5]:
<xarray.Dataset>
Dimensions: (time: 1, y: 17925, x: 14473)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
green (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
blue (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
Attributes:
crs: epsg:6933
grid_mapping: spatial_refLa fonction devrait revenir beaucoup plus rapidement, car elle ne lit aucune donnée du disque.
Morceaux de Dask
Après avoir ajouté le paramètre « dask_chunks » à « dc.load() », les données chargées en différé contiennent des objets « dask.array » avec la taille « chunksize » répertoriée. La taille « chunksize » doit correspondre au paramètre « dask_chunks » initialement transmis à « dc.load() ».
Dask fonctionne en divisant les grands ensembles de données en blocs, qui peuvent être lus individuellement. Vous pouvez spécifier le nombre de pixels de chaque bloc pour chaque dimension de l’ensemble de données.
Par exemple, nous avons passé la définition de bloc suivante à « dc.load() » :
dask_chunks = {'time': 1, 'x': 3000, 'y': 3000}
Cette définition indique à Dask de découper les données en blocs contenant 3000 pixels dans les dimensions « x » et « y » et une mesure dans la dimension « time ». Pour DE Africa, nous définissons toujours « time » : 1 » dans la définition « dask_chunk », car les fichiers de données ne couvrent qu’une seule période.
Si aucune taille de bloc n’est fournie pour une dimension donnée, ou si elle est définie sur -1, le bloc sera défini sur la taille du tableau de cette dimension. Cela signifie que toutes les données de cette dimension seront chargées en même temps, plutôt que d’être divisées en blocs plus petits.
Affichage des fragments Dask
Pour obtenir une intuition visuelle de la manière dont les données ont été divisées en morceaux, nous pouvons utiliser l’attribut « .data » fourni par « xarray ». Cet attribut peut être utilisé sur des mesures individuelles à partir des données chargées en différé. Lorsqu’il est utilisé dans un bloc-notes Jupyter, il fournit un tableau résumant la taille des morceaux individuels et le nombre de morceaux nécessaires.
Un exemple est présenté ci-dessous, utilisant la mesure « rouge » à partir des données chargées de manière différée :
[6]:
lazy_data.red.data
[6]:
|
||||||||||||||||
Dans la colonne Chunk du tableau, nous pouvons voir que les données ont été divisées en 4 morceaux, chaque morceau ayant la forme « (1 fois, 3 000 pixels, 3 000 pixels) » et occupant 18,00 Mo de mémoire. En comparant cela avec la colonne Array, l’utilisation de Dask signifie que nous pouvons charger 4 lots de 18,00 Mo plutôt qu’un lot de 57,67 Mo.
Cela est utile lorsqu’il s’agit de travailler sur de grandes zones ou sur de grandes périodes, car l’ensemble du tableau ne rentre pas toujours dans la mémoire disponible. Le fait de diviser de grands ensembles de données en morceaux et de charger les morceaux un par un signifie que vous pouvez effectuer des calculs sur de grandes zones sans faire planter l’environnement DE Africa.
Chargement des données paresseuses
Lorsque vous travaillez avec des données chargées de manière différée, vous devez demander spécifiquement à Dask de lire et de charger les données lorsque vous souhaitez les utiliser. Tant que vous ne faites pas cela, l’ensemble de données chargé de manière différée ne sait que l’emplacement des données, pas leurs valeurs.
Pour charger les données depuis le disque, appelez .load() sur le DataArray ou le Dataset. Si vous avez ouvert la fenêtre de progression de Dask, vous devriez voir le calcul se poursuivre à cet endroit.
[7]:
loaded_data = lazy_data.load()
[8]:
loaded_data
[8]:
<xarray.Dataset>
Dimensions: (time: 1, y: 17925, x: 14473)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 1083 1139 1208 1219 ... 1585 1687 1641 1596
green (time, y, x) uint16 900 934 992 1001 ... 1102 1176 1154 1131
blue (time, y, x) uint16 668 701 753 761 774 ... 686 727 766 759 726
Attributes:
crs: epsg:6933
grid_mapping: spatial_refLes tableaux Dask construits par le lazy load
red (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
ont maintenant été remplacés par des nombres réels :
red (time, y, x) uint16 10967 11105 10773 10660 ... 12431 12410 12313
Après avoir appliqué la commande « .load() », les données chargées différément sont les mêmes que les données chargées à partir de la première requête.
Opérations paresseuses
En plus de diviser les données en morceaux plus petits qui tiennent dans la mémoire, Dask présente un autre avantage : il peut suivre la manière dont vous souhaitez travailler avec les données, puis effectuer uniquement les opérations nécessaires ultérieurement.
Nous allons maintenant voir comment procéder en calculant l’indice de végétation par différence normalisé (NDVI) pour nos données. Pour ce faire, nous allons à nouveau effectuer l’opération de chargement différé, en ajoutant cette fois la bande proche infrarouge (nir) à la commande dc.load() :
[9]:
lazy_data = dc.load(product='gm_s2_annual',
measurements=['red', 'green', 'blue', 'nir'],
x=(24, 25.5),
y=(-21.5, -20),
time=("2018-01-01", "2018-12-31"),
dask_chunks={'time': 1, 'x': 3000, 'y': 3000})
lazy_data
[9]:
<xarray.Dataset>
Dimensions: (time: 1, y: 17925, x: 14473)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
green (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
blue (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
nir (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
Attributes:
crs: epsg:6933
grid_mapping: spatial_refGraphiques de tâches
Lors de l’utilisation du chargement différé, Dask décompose l’opération de chargement en une série d’étapes. Un moyen utile de visualiser les étapes est le graphique des tâches, auquel on peut accéder en ajoutant la méthode .visualize() à un appel .data :
[10]:
lazy_data.red.data.visualize()
[10]:

Le graphique des tâches se lit de bas en haut.
Les quatre rectangles en bas du graphique sont les entrées de la base de données représentant les fichiers qui doivent être lus pour charger les données.
Au-dessus des rectangles se trouvent des commandes de chargement individuelles (dans les cercles) qui effectueront la lecture. Il y en a une pour chaque bloc. Les flèches décrivent les fichiers qui doivent être lus pour chaque opération : le bloc de gauche a besoin des données des quatre entrées de la base de données, tandis que le bloc de droite n’a besoin des données que d’une seule.
Tout en haut se trouvent les index des morceaux qui constitueront le tableau final.
Ajout de tâches supplémentaires
La puissance de cette méthode réside dans le fait d’enchaîner les tâches avant de charger les données. En effet, Dask chargera uniquement les données requises par l’opération finale de la chaîne.
Nous pouvons le démontrer en demandant seulement une petite partie de la bande rouge. Si nous faisons cela pour les données chargées en différé, nous pouvons visualiser le nouveau graphique de tâches :
[11]:
extract_from_red = lazy_data.red[:, 100:200, 100:200]
extract_from_red.data.visualize()
[11]:

Notez que la nouvelle tâche « getitem » a été ajoutée et qu’elle s’applique uniquement au segment le plus à gauche. Si nous appelons « .load() » sur le tableau Dask « extract_from_red », Dask trace l’opération à travers le graphique pour trouver uniquement les données pertinentes. Cela peut économiser à la fois de la mémoire et du temps.
Nous pouvons établir que l’opération ci-dessus donne le même résultat que le chargement des données sans Dask et leur sous-ensemble en exécutant la commande ci-dessous :
[12]:
lazy_red_subset = extract_from_red.load()
data_red_subset = data.red[:, 100:200, 100:200]
print(f"The loaded arrays match: {lazy_red_subset.equals(data_red_subset)}")
The loaded arrays match: True
Étant donné que les tableaux sont les mêmes, il est utile d’utiliser le chargement différé pour enchaîner les opérations, puis d’appeler .load() lorsque vous êtes prêt à obtenir la réponse. Cela permet d’économiser du temps et de la mémoire, car Dask ne chargera que les données d’entrée nécessaires pour obtenir la sortie finale. Dans cet exemple, le chargement différé n’avait besoin de charger qu’une petite section de la bande « rouge », tandis que le chargement d’origine pour obtenir les « données » devait charger les bandes « rouge », « verte » et « bleue », puis sous-ensemble la bande « rouge », ce qui signifie que du temps a été consacré au chargement de données qui n’ont pas été utilisées.
Tâches multiples
L’avantage de l’utilisation du chargement différé dans Dask est que vous pouvez continuer à enchaîner les opérations jusqu’à ce que vous soyez prêt à obtenir la réponse.
Ici, nous enchaînons plusieurs étapes pour calculer une nouvelle bande pour notre réseau. Plus précisément, nous utilisons les bandes « red » et « nir » pour calculer l’indice de végétation par différence normalisée :
[13]:
band_diff = lazy_data.nir - lazy_data.red
band_sum = lazy_data.nir + lazy_data.red
lazy_data['ndvi'] = band_diff / band_sum
Cela ajoute le nouveau tableau Dask « ndvi » à l’ensemble de données « lazy_data » :
[14]:
lazy_data
[14]:
<xarray.Dataset>
Dimensions: (time: 1, y: 17925, x: 14473)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
green (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
blue (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
nir (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
ndvi (time, y, x) float64 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
Attributes:
crs: epsg:6933
grid_mapping: spatial_refMaintenant que l’opération est définie, nous pouvons visualiser son graphique de tâches :
[15]:
lazy_data.ndvi.data.visualize()
[15]:

En lisant le graphique de bas en haut, on peut voir l’équation se dérouler. Les opérations « add » et « sub » sont effectuées sur chaque bande avant d’être divisées.
Nous pouvons voir comment chaque segment de sortie est indépendant des autres. Cela signifie que nous pourrions calculer chaque segment sans jamais avoir à charger toutes les bandes en mémoire en même temps.
Enfin, nous pouvons calculer les valeurs NDVI en appelant la commande .load(). Nous allons stocker le résultat dans la variable ndvi_load :
[16]:
ndvi_load = lazy_data.ndvi.load()
ndvi_load
/usr/local/lib/python3.10/dist-packages/dask/core.py:119: RuntimeWarning: invalid value encountered in divide
return func(*(_execute_task(a, cache) for a in args))
[16]:
<xarray.DataArray 'ndvi' (time: 1, y: 17925, x: 14473)>
array([[[0.34023759, 0.33039389, 0.32077593, ..., 0.37083061,
0.38180611, 0.37719008],
[0.33235381, 0.33006912, 0.32352124, ..., 0.36498708,
0.36280884, 0.38525155],
[0.31681217, 0.3295325 , 0.32962448, ..., 0.36790286,
0.35850274, 0.36588629],
...,
[0.19612476, 0.1977664 , 0.20513408, ..., 0.23719165,
0.26922088, 0.2815534 ],
[0.19981128, 0.20527046, 0.20905764, ..., 0.2352666 ,
0.25160983, 0.2643065 ],
[0.20236407, 0.20495443, 0.20352341, ..., 0.23283311,
0.25068493, 0.25750174]]])
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933Notez que l’exécution de la commande « .load() » modifie également l’entrée « ndvi » dans l’ensemble de données « lazy_load » :
[17]:
lazy_data
[17]:
<xarray.Dataset>
Dimensions: (time: 1, y: 17925, x: 14473)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
green (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
blue (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
nir (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
ndvi (time, y, x) float64 0.3402 0.3304 0.3208 ... 0.2507 0.2575
Attributes:
crs: epsg:6933
grid_mapping: spatial_refVous pouvez voir que « ndvi » est un nombre, alors que toutes les autres variables sont des tableaux Dask.
Conserver les variables sous forme de tableaux Dask
Si vous souhaitez calculer les valeurs NDVI, mais laisser « ndvi » comme un tableau dask dans « lazy_load », vous pouvez utiliser la commande « .compute() » à la place.
Pour démontrer cela, nous redéfinissons d’abord la variable « ndvi » afin qu’elle redevienne un tableau Dask
[18]:
lazy_data['ndvi'] = band_diff / band_sum
lazy_data
[18]:
<xarray.Dataset>
Dimensions: (time: 1, y: 17925, x: 14473)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
green (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
blue (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
nir (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
ndvi (time, y, x) float64 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
Attributes:
crs: epsg:6933
grid_mapping: spatial_refMaintenant, nous effectuons les mêmes étapes que précédemment pour calculer le NDVI, mais utilisons .compute() au lieu de .load():
[19]:
ndvi_compute = lazy_data.ndvi.compute()
ndvi_compute
[19]:
<xarray.DataArray 'ndvi' (time: 1, y: 17925, x: 14473)>
array([[[0.34023759, 0.33039389, 0.32077593, ..., 0.37083061,
0.38180611, 0.37719008],
[0.33235381, 0.33006912, 0.32352124, ..., 0.36498708,
0.36280884, 0.38525155],
[0.31681217, 0.3295325 , 0.32962448, ..., 0.36790286,
0.35850274, 0.36588629],
...,
[0.19612476, 0.1977664 , 0.20513408, ..., 0.23719165,
0.26922088, 0.2815534 ],
[0.19981128, 0.20527046, 0.20905764, ..., 0.2352666 ,
0.25160983, 0.2643065 ],
[0.20236407, 0.20495443, 0.20352341, ..., 0.23283311,
0.25068493, 0.25750174]]])
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933Vous pouvez voir que les valeurs ont été calculées, mais comme indiqué ci-dessous, la variable « ndvi » est conservée sous forme de tableau Dask.
[20]:
lazy_data
[20]:
<xarray.Dataset>
Dimensions: (time: 1, y: 17925, x: 14473)
Coordinates:
* time (time) datetime64[ns] 2018-07-02T11:59:59.999999
* y (y) float64 -2.501e+06 -2.501e+06 ... -2.681e+06 -2.681e+06
* x (x) float64 2.316e+06 2.316e+06 2.316e+06 ... 2.46e+06 2.46e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
green (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
blue (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
nir (time, y, x) uint16 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
ndvi (time, y, x) float64 dask.array<chunksize=(1, 3000, 3000), meta=np.ndarray>
Attributes:
crs: epsg:6933
grid_mapping: spatial_refL’utilisation de .compute() peut vous permettre de calculer entre les étapes et de stocker les résultats, sans modifier le jeu de données ou le tableau Dask d’origine. Cependant, soyez prudent lorsque vous utilisez .compute(), car cela peut entraîner une confusion sur ce que vous avez modifié et ce que vous n’avez pas modifié, ainsi que plusieurs calculs de la même quantité.
Ressources supplémentaires
Pour en savoir plus sur le fonctionnement de Dask et sur la manière dont il est utilisé par xarray, consultez ces ressources :
Autres cahiers
Il s’agit du dernier cahier du guide du débutant ; si quelque chose n’était pas clair, nous vous recommandons de réviser le cahier concerné :
Traitement parallèle avec Dask (ce notebook)
Une fois que vous avez terminé les huit didacticiels ci-dessus, rejoignez les utilisateurs avancés pour explorer :
Le répertoire « Datasets » du référentiel, où vous pouvez explorer en profondeur les produits DE Africa.
Le répertoire « Code fréquemment utilisé », qui contient un livre de recettes de techniques et méthodes courantes pour l’analyse des données DE Africa.
Le répertoire « Exemples du monde réel », qui fournit des flux de travail plus complexes et des études de cas d’analyse.
Informations Complémentaires
Licence : Le code de ce carnet est sous licence Apache, version 2.0 <https://www.apache.org/licenses/LICENSE-2.0>. Les données de Digital Earth Africa sont sous licence Creative Commons par attribution 4.0 <https://creativecommons.org/licenses/by/4.0/>.
Contact : Si vous avez besoin d’aide, veuillez poster une question sur le canal Slack Open Data Cube <http://slack.opendatacube.org/>`__ ou sur le GIS Stack Exchange en utilisant la balise open-data-cube (vous pouvez consulter les questions posées précédemment ici). Si vous souhaitez signaler un problème avec ce bloc-notes, vous pouvez en déposer un sur Github.
Version de Datacube compatible :
[21]:
print(datacube.__version__)
1.8.15
Dernier test :
[22]:
from datetime import date
print(date.today())
2023-08-11