NDVI Climatology
Products used: ndvi_climatology_ls
Keywords: data used; ndvi climatology
Background
Climatology refers to conditions averaged over a long period of time, typically greater than 30 years. The Digital Earth Africa NDVI Climatology product represents the long-term average baseline condition of vegetation for every Landsat pixel over the African continent. Both mean and standard deviation NDVI climatologies are available for each calendar month based on calculation over the period 1984-2020. NDVI climatologies may be used for many applications including identifying extremeties (anomalies) in vegetation condition, identifying both long and short-term changes in vegetation condition, and as an input into machine learning processes for land use classification.
Further details on the calculation of the product are available in the NDVI Climatology technical specifications documentation.
Important details:
Datacube product name:
ndvi_climatology_lsMeasurements
mean_<month>: These measurements show the mean NDVI calculated from all available NDVI data from 1984-2020 for the given month.stddev_<month>: These measurements show the standard deviation of NDVI values of all available NDVI data from 1984-2020 for the given month.count_<month>: These measaurements show the number of clear observations that go into creating the mean and standard deviation measurements. Importantly, caution should be used when applying this product to regions where the clear observation count is less than approximately 20-30. This can often be the case over equatorial Africa due to frequent cloud cover and inconsistent coverage of Landsat-5.
Status: Provisional
Date-range: The time dimension represents calendar months aggregated across the period 1984-2020.
Spatial resolution: 30m
Description
In this notebook we will load the NDVI Climatology product using dc.load() to return mean, standard deviation, and clear observation count for each calendar month. A final section explores an example analysis using the product.
Topics covered include:
Inspecting the NDVI Climatology product and measurements available in the datacube.
Using the native
dc.load()function to load in NDVI Climatology.Inspect perennial and annual vegtation using NDVI mean and standard deviation.
Exaple analysis: analyse and plot the climatological (long-term average) phenology of croplands
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
Load packages
[1]:
import datacube
import numpy as np
import xarray as xr
import pandas as pd
import matplotlib.pyplot as plt
from odc.ui import with_ui_cbk
from deafrica_tools.plotting import display_map
Connect to the datacube
[2]:
dc = datacube.Datacube(app='NDVI_clim')
Available measurements
List measurements
The table printed below shows the measurements available in the NDVI Climatology product. The mean NDVI, standard deviation of NDVI, and clear obervations count can be loaded for each calendar month.
[3]:
product_name = 'ndvi_climatology_ls'
dc_measurements = dc.list_measurements()
dc_measurements.loc[product_name].drop('flags_definition', axis=1)
[3]:
| name | dtype | units | nodata | aliases | |
|---|---|---|---|---|---|
| measurement | |||||
| mean_jan | mean_jan | float32 | 1 | NaN | [MEAN_JAN, mean_january] |
| mean_feb | mean_feb | float32 | 1 | NaN | [MEAN_FEB, mean_february] |
| mean_mar | mean_mar | float32 | 1 | NaN | [MEAN_MAR, mean_march] |
| mean_apr | mean_apr | float32 | 1 | NaN | [MEAN_APR, mean_april] |
| mean_may | mean_may | float32 | 1 | NaN | [MEAN_MAY] |
| mean_jun | mean_jun | float32 | 1 | NaN | [MEAN_JUN, mean_june] |
| mean_jul | mean_jul | float32 | 1 | NaN | [MEAN_JUL, mean_july] |
| mean_aug | mean_aug | float32 | 1 | NaN | [MEAN_AUG, mean_august] |
| mean_sep | mean_sep | float32 | 1 | NaN | [MEAN_SEP, mean_september] |
| mean_oct | mean_oct | float32 | 1 | NaN | [MEAN_OCT, mean_october] |
| mean_nov | mean_nov | float32 | 1 | NaN | [MEAN_NOV, mean_november] |
| mean_dec | mean_dec | float32 | 1 | NaN | [MEAN_DEC, mean_december] |
| stddev_jan | stddev_jan | float32 | 1 | NaN | [STDDEV_JAN, stddev_january] |
| stddev_feb | stddev_feb | float32 | 1 | NaN | [STDDEV_FEB, stddev_feburary] |
| stddev_mar | stddev_mar | float32 | 1 | NaN | [STDDEV_MAR, stddev_march] |
| stddev_apr | stddev_apr | float32 | 1 | NaN | [STDDEV_APR, stddev_april] |
| stddev_may | stddev_may | float32 | 1 | NaN | [STDDEV_MAY] |
| stddev_jun | stddev_jun | float32 | 1 | NaN | [STDDEV_JUN, stddev_june] |
| stddev_jul | stddev_jul | float32 | 1 | NaN | [STDDEV_JUL, stddev_july] |
| stddev_aug | stddev_aug | float32 | 1 | NaN | [STDDEV_AUG, stddev_august] |
| stddev_sep | stddev_sep | float32 | 1 | NaN | [STDDEV_SEP, stddev_september] |
| stddev_oct | stddev_oct | float32 | 1 | NaN | [STDDEV_OCT, stddev_october] |
| stddev_nov | stddev_nov | float32 | 1 | NaN | [STDDEV_NOV, stddev_november] |
| stddev_dec | stddev_dec | float32 | 1 | NaN | [STDDEV_DEC, stddev_december] |
| count_jan | count_jan | int16 | 1 | -999.0 | [COUNT_JAN, count_january] |
| count_feb | count_feb | int16 | 1 | -999.0 | [COUNT_FEB, count_february] |
| count_mar | count_mar | int16 | 1 | -999.0 | [COUNT_MAR, count_march] |
| count_apr | count_apr | int16 | 1 | -999.0 | [COUNT_APR, count_april] |
| count_may | count_may | int16 | 1 | -999.0 | [COUNT_MAY] |
| count_jun | count_jun | int16 | 1 | -999.0 | [COUNT_JUN, count_june] |
| count_jul | count_jul | int16 | 1 | -999.0 | [COUNT_JUL, count_july] |
| count_aug | count_aug | int16 | 1 | -999.0 | [COUNT_AUG, count_august] |
| count_sep | count_sep | int16 | 1 | -999.0 | [COUNT_SEP, count_september] |
| count_oct | count_oct | int16 | 1 | -999.0 | [COUNT_OCT, count_october] |
| count_nov | count_nov | int16 | 1 | -999.0 | [COUNT_NOV, count_november] |
| count_dec | count_dec | int16 | 1 | -999.0 | [COUNT_DEC, count_december] |
Analysis parameters
This section defines the analysis parameters, including:
lat, lon, buffer: center lat/lon and analysis window size for the area of interestresolution: the pixel resolution to use for loading thendvi_climatology_ls. The native resolution of the product is 30 metres i.e.(-30,30)as the product is Landsat derived.
The default location is an cropping region in Western Cape, South Africa where an irrigation scheme along a river is surrounded by rain-fed cropping.
[4]:
lat, lon = -34.0602, 20.2800 # capetown
buffer = 0.08
resolution=(-30, 30)
#join lat, lon, buffer to get bounding box
lon_range = (lon - buffer, lon + buffer)
lat_range = (lat + buffer, lat - buffer)
View the selected location
The next cell will display the selected area on an interactive map. Feel free to zoom in and out to get a better understanding of the area you’ll be analysing. Clicking on any point of the map will reveal the latitude and longitude coordinates of that point.
[5]:
display_map(lon_range, lat_range)
[5]:
Load data
Below we use the dc.load function to load all the measurements over the region specified above.
[6]:
# load data
ndvi_clim = dc.load(
product="ndvi_climatology_ls",
resolution=resolution,
x=lon_range,
y=lat_range,
progress_cbk=with_ui_cbk(),
)
print(ndvi_clim)
<xarray.Dataset>
Dimensions: (time: 1, y: 567, x: 515)
Coordinates:
* time (time) datetime64[ns] 2002-07-02T11:59:59.999999
* y (y) float64 -4.091e+06 -4.091e+06 ... -4.108e+06 -4.108e+06
* x (x) float64 1.949e+06 1.949e+06 ... 1.964e+06 1.964e+06
spatial_ref int32 6933
Data variables: (12/36)
mean_jan (time, y, x) float32 0.4916 0.4292 0.4075 ... 0.1989 0.2001
mean_feb (time, y, x) float32 0.5281 0.4745 0.4531 ... 0.222 0.2238
mean_mar (time, y, x) float32 0.4731 0.416 0.3949 ... 0.2116 0.2121
mean_apr (time, y, x) float32 0.5536 0.5103 0.5034 ... 0.2504 0.2526
mean_may (time, y, x) float32 0.6418 0.6385 0.6137 ... 0.4022 0.3982
mean_jun (time, y, x) float32 0.6343 0.6148 0.6111 ... 0.5 0.5278 0.5339
... ...
count_jul (time, y, x) int16 30 30 30 30 30 31 33 ... 31 31 31 31 31 31
count_aug (time, y, x) int16 29 29 29 29 29 29 30 ... 23 23 23 23 23 23
count_sep (time, y, x) int16 33 33 33 33 33 33 33 ... 32 32 32 32 31 31
count_oct (time, y, x) int16 32 32 32 33 33 33 32 ... 30 30 30 31 31 31
count_nov (time, y, x) int16 36 36 36 36 37 37 37 ... 30 30 31 31 31 31
count_dec (time, y, x) int16 37 38 38 38 38 38 37 ... 35 35 35 34 35 35
Attributes:
crs: epsg:6933
grid_mapping: spatial_ref
Plotting NDVI Climatology
Store measurements
As this dataset has a lot of measurements, it is easier to store them in a list and access them as we need when plotting etc., rather than typing out each measurement
[7]:
measurements = [i for i in ndvi_clim.data_vars]
mean_bands = measurements[0:12]
std_bands = measurements[12:24]
count_bands = measurements[24:36]
Add a time dimension to the climatologies
Adding a time dimension to the dataset by concatenating the months together allows us to quickly make plots or calculate ket statistics without looping through separate datasets.
Important note: The date ‘2002’ is meaningless, its simply the middle point between 1984 and 2020 - the range over which the climatologies were calculated.
[8]:
months = ['01','02','03','04','05','06','07','08','09','10','11','12']
arrs_mean = []
arrs_std = []
arrs_count = []
for m,s,c,i in zip(mean_bands, std_bands, count_bands, months):
#index out the different types of measurements
xx_mean=ndvi_clim[m]
xx_std=ndvi_clim[s]
xx_count=ndvi_clim[c]
#add a time dimension corresponding to the right month
time = pd.date_range(np.datetime64('2002-'+i+'-15'), periods=1)
xx_mean['time'] = time
xx_std['time'] = time
xx_count['time'] = time
#append to lists
arrs_count.append(xx_count)
arrs_mean.append(xx_mean)
arrs_std.append(xx_std)
#concatenate into 3D data array along time dimension
ndvi_mean = xr.concat(arrs_mean, dim='time').rename('NDVI_Climatology_Mean')
ndvi_std = xr.concat(arrs_std, dim='time').rename('NDVI_Climatology_Std')
ndvi_count = xr.concat(arrs_count, dim='time').rename('NDVI_Climatology_Count')
Facet plot the mean NDVI climatology
The plots below show that, on average, the irrigated fields around the river, and the riparian vegetetation are more persistently green throughout the year, while the rainfed cropping regions are green through the winter months of June, July, August, and September.
[9]:
ndvi_mean.plot.imshow(col='time', col_wrap=6, cmap="RdYlGn");
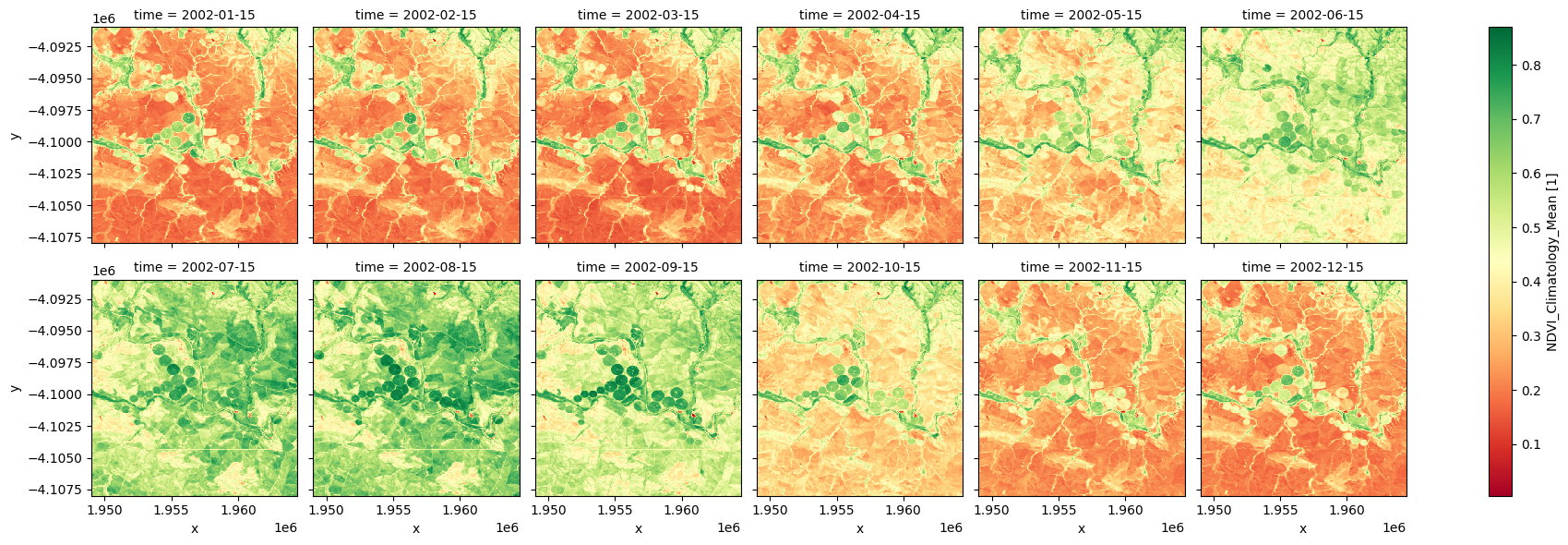
Facet plot the standard deviation NDVI climatology
Note the irrigated regions tend to show greater variability than the other pixels. By enabling distinction between classes of agricultural land and other vegetation, this might be a good input to land use classification methods such as thresholding or more complex machine learning approaches.
[10]:
ndvi_std.plot.imshow(col='time', col_wrap=6, cmap="magma", vmax=0.25);
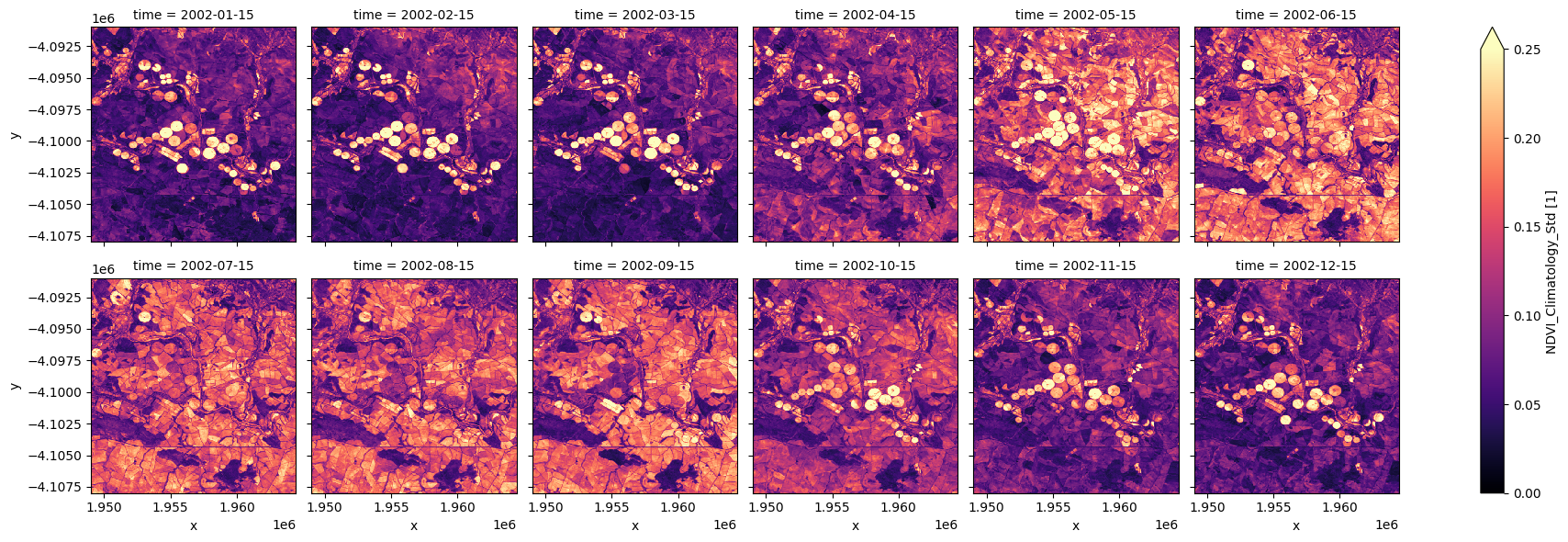
Facet plot the clear count
We can use these plots to understand how many observations are going into the climatology calculations. Below (in the default example) we can that in the drier months there are ~25-35 observations (over the 37 year period of the climatology), while in the winter months there are ~20. In this case, because the observation count is relatvely low for the winter months, we should be careful when using the climatology in those months. In this specific example the mean and standard deviation measurements plotted above look okay, probably because the region is at a higher latitude and therefore not so affected by cloud. If this region was in the tropics then the dataset may be of a poorer quality.
[11]:
ndvi_count.plot.imshow(col='time', col_wrap=6, cmap="viridis");
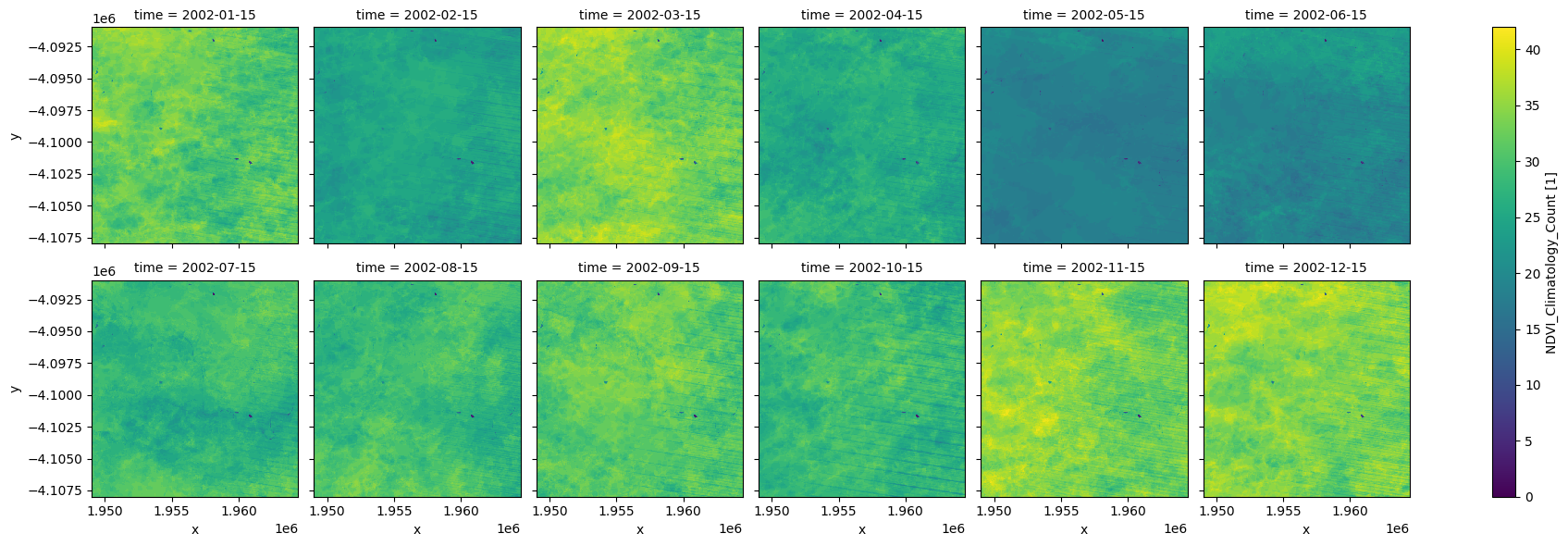
Example Analysis: Cropland Climatological Phenology
We can use the NDVI climatology product to generate long-term average phenological patterns for specific regions, landscapes, or vegetation types. Limiting our analysis of the area above to a crop mask enables us to investigate the long-term average phenology of cropland.
[12]:
#import deafrica's phenology function
from deafrica_tools.temporal import xr_phenology
Load the cropmask dataset for the region
[13]:
cm = dc.load(product="crop_mask",
measurements='filtered',
resampling='nearest',
like=ndvi_clim.geobox).filtered.squeeze()
cm.plot.imshow();
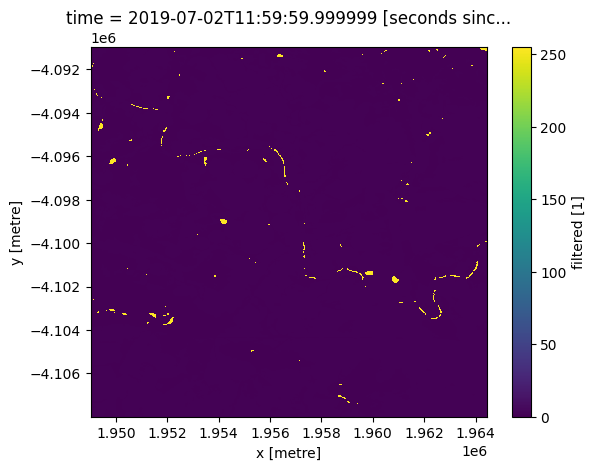
Mask the datasets with the crop mask
[14]:
ndvi_mean_crop = ndvi_mean.where(cm)
ndvi_std_crop = ndvi_std.where(cm)
Plot phenology curve
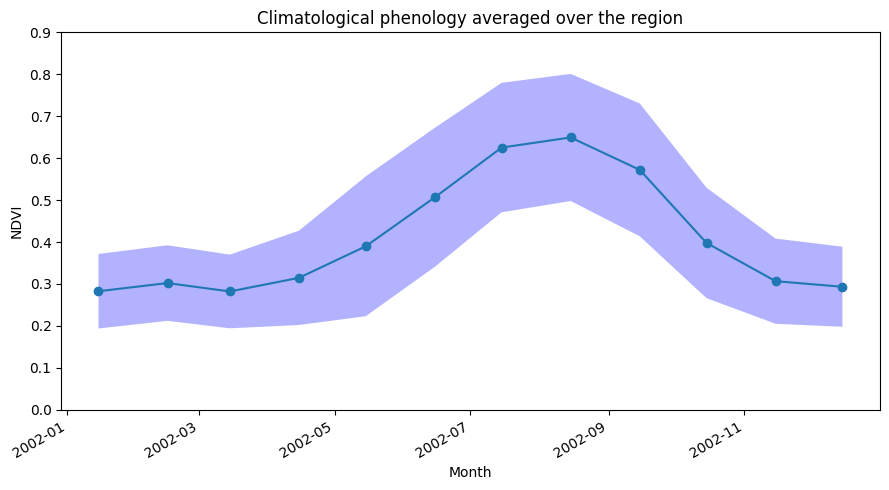
Below we summarise the datasets spatially by taking the mean across the x and y dimensions, this will leave us with the average trend through time for the region we’ve loaded.
When we plot the phenology curve below, we will add +- 1 standard deviation around the mean curve to indicate, on average, how much the trends vary around the long-term mean.
From the phenology plot, we can conclude that crop growth generally commences around May and continues until harvest around October.
[15]:
ndvi_mean_crop_line = ndvi_mean_crop.mean(['x','y'])
ndvi_std_crop_line = ndvi_std_crop.mean(['x','y'])
#upper and lower boundaries
ndvi_std_upper = ndvi_mean_crop_line+ndvi_std_crop_line
ndvi_std_lower = ndvi_mean_crop_line-ndvi_std_crop_line
Plot the mean phenology curve, with +-1 standard deviation envelope
[16]:
ndvi_mean_crop_line.plot(figsize=(9,5), marker='o')
plt.fill_between(
ndvi_mean_crop_line.time.values,
ndvi_std_upper.values,
ndvi_std_lower.values,
facecolor="blue",
alpha=0.3,
)
plt.ylim(0,0.9)
plt.title('Climatological phenology averaged over the region')
plt.xlabel('Month')
plt.ylabel('NDVI')
plt.tight_layout()
Per pixel climatological phenology
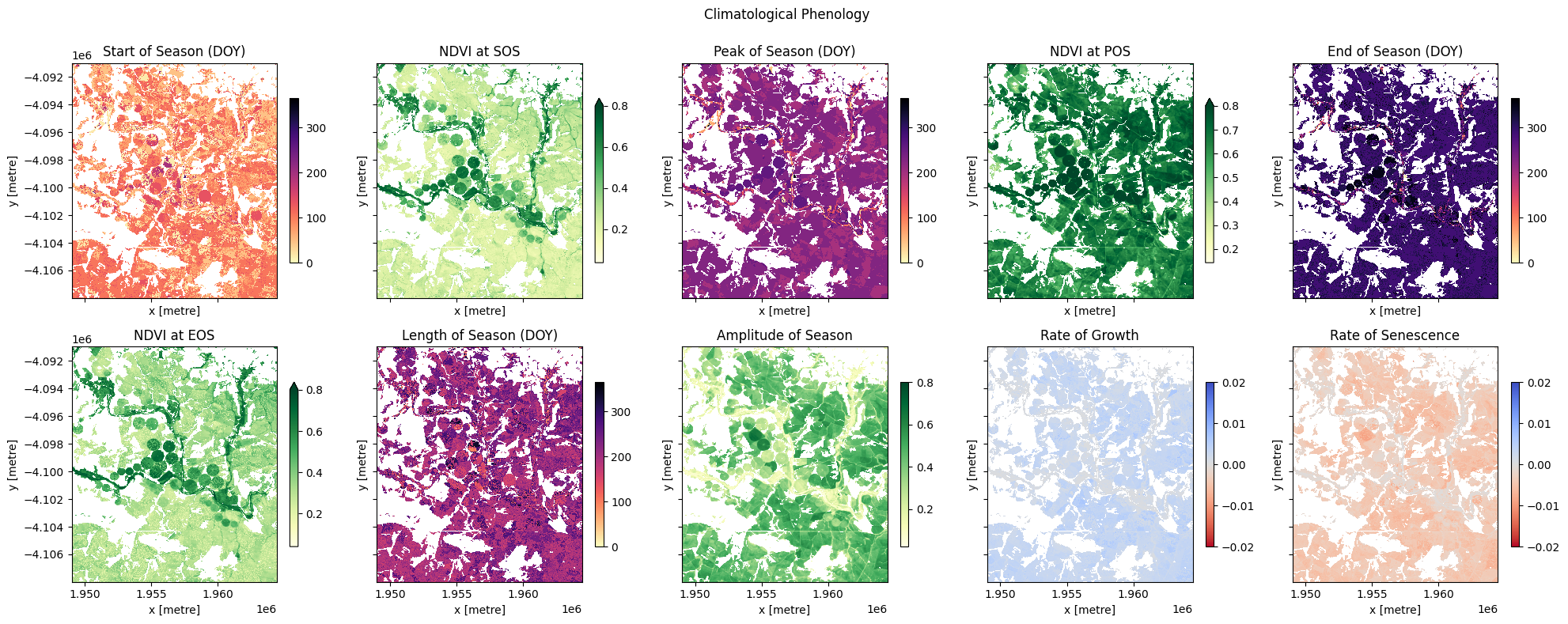
Having plotted in the spatially averaged climatological phenology, we can now use the DE Africa function xr_phenology to calculate the typical phenology of every pixel in the dataset.
This function computes key phenological statistics expressed as the day-of-the-year (DOY) at:
Start of Season (SOS),
Peak of Season (POS),
End of Season (EOS).
It also gives NDVI values (v) for the times above (e.g. vSOS for the NDVI value at the start of season), and other variables including:
Trough: minimum NDVI value of season,
LOS: Length of season,
AOS: Amplitude of season (difference between the base and maximum NDVI values),
ROG: Rate of greening,
ROS: Rate of senescence.
Important note: Remember that this product is monthly (not daily) so the DOY is simply the middle of the month when the NDVI peaks, for example (we set the time dimension to be the 15th of each month in the “adding time dimension” section above).
[17]:
#calculate per-pixel phenology
phen = xr_phenology(ndvi_mean_crop, method_eos='median', method_sos='median', verbose=False)
#mask again with crop-mask
phen = phen.where(cm)
print(phen)
<xarray.Dataset>
Dimensions: (y: 567, x: 515)
Coordinates:
* y (y) float64 -4.091e+06 -4.091e+06 ... -4.108e+06 -4.108e+06
* x (x) float64 1.949e+06 1.949e+06 ... 1.964e+06 1.964e+06
spatial_ref int32 6933
time datetime64[ns] 2019-07-02T11:59:59.999999
Data variables:
SOS (y, x) datetime64[ns] NaT NaT NaT ... 2002-02-15 2002-02-15
POS (y, x) datetime64[ns] NaT NaT NaT ... 2002-08-15 2002-08-15
EOS (y, x) datetime64[ns] NaT NaT NaT ... 2002-10-15 2002-11-15
Trough (y, x) float32 nan nan nan nan ... 0.1941 0.1952 0.1989 0.2001
vSOS (y, x) float32 nan nan nan nan ... 0.2217 0.221 0.222 0.2238
vPOS (y, x) float32 nan nan nan nan ... 0.7151 0.7131 0.7291 0.7375
vEOS (y, x) float32 nan nan nan nan ... 0.3536 0.3585 0.3682 0.2471
LOS (y, x) float32 nan nan nan nan ... 242.0 242.0 242.0 273.0
AOS (y, x) float32 nan nan nan nan ... 0.5209 0.518 0.5302 0.5374
ROG (y, x) float32 nan nan nan nan ... 0.002719 0.002801 0.002838
ROS (y, x) float32 nan nan nan ... -0.005813 -0.005916 -0.005331
Attributes:
grid_mapping: spatial_ref
Plot per pixel phenology
[18]:
# set up figure
fig, ax = plt.subplots(nrows=2,
ncols=5,
figsize=(20, 8),
sharex=True,
sharey=True)
# set colorbar size
cbar_size = 0.7
# set aspect ratios
for a in fig.axes:
a.set_aspect('equal')
# start of season
phen.SOS.dt.dayofyear.plot.imshow(ax=ax[0, 0],
cmap='magma_r',
vmax=365,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 0].set_title('Start of Season (DOY)')
phen.vSOS.plot.imshow(ax=ax[0, 1],
cmap='YlGn',
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 1].set_title('NDVI at SOS')
# peak of season
phen.POS.dt.dayofyear.plot.imshow(ax=ax[0, 2],
cmap='magma_r',
vmax=365,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 2].set_title('Peak of Season (DOY)')
phen.vPOS.plot.imshow(ax=ax[0, 3],
cmap='YlGn',
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 3].set_title('NDVI at POS')
# end of season
phen.EOS.dt.dayofyear.plot.imshow(ax=ax[0, 4],
cmap='magma_r',
vmax=365,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[0, 4].set_title('End of Season (DOY)')
phen.vEOS.plot.imshow(ax=ax[1, 0],
cmap='YlGn',
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 0].set_title('NDVI at EOS')
# Length of Season
phen.LOS.plot.imshow(ax=ax[1, 1],
cmap='magma_r',
vmax=365,
vmin=0,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 1].set_title('Length of Season (DOY)')
# Amplitude
phen.AOS.plot.imshow(ax=ax[1, 2],
cmap='YlGn',
vmax=0.8,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 2].set_title('Amplitude of Season')
# rate of growth
phen.ROG.plot.imshow(ax=ax[1, 3],
cmap='coolwarm_r',
vmin=-0.02,
vmax=0.02,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 3].set_title('Rate of Growth')
# rate of Sensescence
phen.ROS.plot.imshow(ax=ax[1, 4],
cmap='coolwarm_r',
vmin=-0.02,
vmax=0.02,
cbar_kwargs=dict(shrink=cbar_size, label=None))
ax[1, 4].set_title('Rate of Senescence')
plt.suptitle('Climatological Phenology')
plt.tight_layout();
Additional information
License: The code in this notebook is licensed under the Apache License, Version 2.0. Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact: If you need assistance, please post a question on the Open Data Cube Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here). If you would like to report an issue with this notebook, you can file one on
Github.
Compatible datacube version:
[19]:
print(datacube.__version__)
1.8.15
Last Tested:
[20]:
from datetime import datetime
datetime.today().strftime('%Y-%m-%d')
[20]:
'2024-03-18'