Performing a basic analysis
Products used: s2_l2a
Prerequisites: Users of this notebook should have a basic understanding of:
How to run a Jupyter notebook
Inspecting available DE Africa products and measurements
How to load data from DE Africa
How to plot loaded data
Keywords: beginner’s guide; analysis, analysis; beginner’s guide, data used; landsat 8, band index; NDVI, data methods; exporting
Background
To understand the world around us, it’s important to combine the key steps of loading, visualising, analysing, and interpreting satellite data. To perform an analysis, we begin with a question and use these steps to reach an answer.
Description
This notebook demonstrates how to conduct a basic analysis with DE Africa data and the Open Data Cube. It will combine many of the steps that have been covered in the other beginner’s notebooks.
In this notebook, the analysis question is “How is the health of vegetation changing over time in a given area?”
This could be related to a number of broader questions:
What is the effect of a new land use practice on a field of crops?
How has a patch of forest changed after a fire?
How does proximity to water affect vegetation throughout the year?
For this notebook, the analysis question will be kept simple, without much real-world context. For more examples of notebooks that demonstrate how to use DE Africa to answer specific analysis questions, see the notebooks in the “Real world examples” folder.
Topics covered in this notebook include:
Choosing a study area.
Loading data for the study area.
Plotting the chosen data and exploring how it changes with time.
Calculating a measure of vegetation health from the loaded data.
Exporting the data for further analysis.
Getting started
To run this introduction to performing basic analysis with DE Africa data and the datacube, run all the cells in the notebook starting with the “Load packages” cell. For help with running notebook cells, refer back to the Jupyter Notebooks notebook.
Load packages
The cell below imports Python packages that are used for the analysis. The first command is %matplotlib inline, which ensures figures plot correctly in the Jupyter notebook. The following commands import various functionality:
deafrica_toolscontains helpful support functions, including those in thedeafrica_plottingmodule which we are using in this notebook.datacubeprovides the ability to query and load data.matplotlibprovides the ability to format and manipulate plots.
[1]:
%matplotlib inline
import datacube
import odc.algo
import matplotlib.pyplot as plt
from datacube.utils.cog import write_cog
from deafrica_tools.plotting import display_map, rgb
Connect to the datacube
The next step is to connect to the datacube database. The resulting dc datacube object can then be used to load data. The app parameter is a unique name used to identify the notebook that does not have any effect on the analysis.
[2]:
dc = datacube.Datacube(app="05_Basic_analysis")
Step 1: Choose a study area
When working with the Open Data Cube, it’s important to load only as much data as needed. This helps keep an analysis running quickly and avoids the notebook crashing due to insufficient memory.
One way to set the study area is to set a central latitude and longitude coordinate pair, (central_lat, central_lon), then specify how many degrees to include either side of the central latitude and longitude, known as the buffer. Together, these parameters specify a square study area, as shown below:
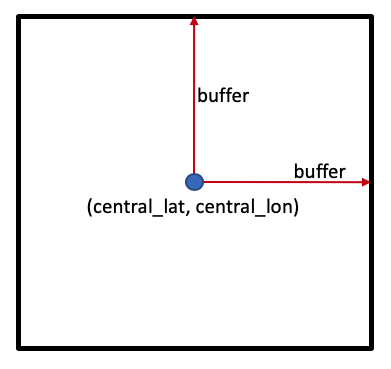
Location
Below, we have set the study area covering an agricultural area in South Africa. To load a different area, you can provide your own central_lat and central_lon values. One way to source these is to Google a location, or click directly on the map in Google
Maps. Other options are:
Mount Kenya, Kenya
central_lat = -0.243
central_lon = 37.459
Bobiri Forest Reserve, Ghana
central_lat = 6.688
central_lon = -1.303
Note: If you change the study area latitude and longitude, you’ll need to re-run all of the cells after to apply that change to the whole analysis.
Buffer
Feel free to experiment with the buffer value to load different sized areas. We recommend that you keep the buffer relatively small, no higher than buffer=0.1 degrees. This will help keep the loading times reasonable and prevent the notebook from crashing.
Extension: Can you modify the code to use a different
buffervalue for latitude and longitude?
Hint: You may want two variables,
buffer_latandbuffer_lonthat you can set independently. You’ll then need to update the definitions ofstudy_area_latandstudy_area_lonwith their corresponding buffer value.
[3]:
# Set the central latitude and longitude
central_lat = -31.5393
central_lon = 18.2682
# Set the buffer to load around the central coordinates
buffer = 0.03
# Compute the bounding box for the study area
study_area_lat = (central_lat - buffer, central_lat + buffer)
study_area_lon = (central_lon - buffer, central_lon + buffer)
After choosing the study area, it can be useful to visualise it on an interactive map. This provides a sense of scale. > Note: The interactive map also returns latitude and longitude values when clicked. You can use this to generate new latitude and longitude values to try without leaving the notebook.
[4]:
display_map(x=study_area_lon, y=study_area_lat)
[4]:
Step 2: Loading data
When asking analysis questions about vegetation, it’s useful to work with optical imagery, such as Sentinel-2 or Landsat. The Sentinel-2 satellites have 10 metre resolution and go back to 2017.
The code below sets up the required information to load the data.
[5]:
# Set the data source - s2a corresponds to Sentinel-2A
set_product = "s2_l2a"
# Set the date range to load data over
set_time = ("2018-01-01", "2018-02-01")
# Set the measurements/bands to load
# For this analysis, we'll load the red, green, blue and near-infrared bands
set_measurements = [
"red",
"blue",
"green",
"nir"
]
# Set the coordinate reference system and output resolution
set_crs = 'EPSG:6933'
set_resolution = (-10, 10)
After setting all of the necessary parameters, the dc.load() command is used to load the data:
[6]:
dataset = dc.load(
product=set_product,
x=study_area_lon,
y=study_area_lat,
time=set_time,
measurements=set_measurements,
output_crs=set_crs,
resolution=set_resolution,
group_by='solar_day'
)
Following the load step, printing the dataset object will give you insight into all of the data that was loaded. Do this by running the next cell.
There’s a lot of information to unpack, which is represented by the following aspects of the data:
Dimensions: the names of data dimensions, frequentlytime,xandy, and number of entries in eachCoordinates: the coordinate values for each point in the data cubeData variables: the observations loaded, frequently different spectral bands from a satelliteAttributes: any useful information for the data, such as thecrs(coordinate reference system)
[7]:
dataset.red.attrs
[7]:
{'units': '1', 'nodata': 0, 'crs': 'EPSG:6933', 'grid_mapping': 'spatial_ref'}
[8]:
print(dataset)
<xarray.Dataset>
Dimensions: (time: 6, y: 655, x: 580)
Coordinates:
* time (time) datetime64[ns] 2018-01-04T08:57:02 ... 2018-01-29T08:...
* y (y) float64 -3.825e+06 -3.825e+06 ... -3.831e+06 -3.831e+06
* x (x) float64 1.76e+06 1.76e+06 1.76e+06 ... 1.766e+06 1.766e+06
spatial_ref int32 6933
Data variables:
red (time, y, x) uint16 2502 2600 2754 2754 ... 1786 1348 880 1292
blue (time, y, x) uint16 955 949 1015 1011 954 ... 932 654 586 796
green (time, y, x) uint16 1580 1630 1718 1700 ... 1328 969 857 1090
nir (time, y, x) uint16 3200 3366 3442 3504 ... 2612 2624 2072 1742
Attributes:
crs: EPSG:6933
grid_mapping: spatial_ref
Step 3: Plotting data
After loading the data, it is useful to view it to understand the resolution, which observations are impacted by cloud cover, and whether there are any obvious differences between time steps.
We use the rgb() function to plot the data loaded in the previous step. The rgb() function maps three data variables/measurements from the loaded dataset to the red, green and blue channels that are used to make a three-colour image. There are several parameters you can experiment with:
time_step=nThis sets the time step you want to view.ncan be any number from0to one fewer than the number of time steps you loaded. The number of time steps loaded is given in the print-out of the data, under theDimensionsheading. As an example, if underDimensions:you seetime: 6, then there are 6 time steps, andtime_stepcan be any number between0and5.bands=[red_channel, green_channel, blue_channel]This sets the measurements that you want to use to make the image. Any measurements can be mapped to the three channels, and different combinations highlight different features. Two common combinations aretrue colour:
bands = ["red", "green", "blue"]false colour:
bands = ["nir", "red", "green"]
For more detail about customising plots, see the Introduction to plotting notebook.
Extension: If
time_stepis set to an array of values, e.g.time_step=[time_1, time_2], it will plot all provided time steps. See if you can modify the code to plot the first and last images. If you do, what changes do you notice?
Hint: To get the last image, you can use a time step value of
-1
[9]:
# Set the time step to view
time_step = 1
[10]:
# Set the band combination to plot
bands = ["red", "green", "blue"]
# Generate the image by running the rgb function
rgb(dataset, bands=bands, index=time_step, size=8)
# Format the time stamp for use as the plot title
time_string = str(dataset.time.isel(time=time_step).values).split('.')[0]
# Set the title and axis labels
ax = plt.gca()
ax.set_title(f"Timestep {time_string}", fontweight='bold', fontsize=16)
ax.set_xlabel('Easting (m)', fontweight='bold')
ax.set_ylabel('Northing (m)', fontweight='bold')
# Display the plot
plt.show()

Step 4: Calculate vegetation health
While it’s possible to identify vegetation in the RGB image, it can be helpful to have a quantitative index to describe the health of vegetation directly.
In this case, the Normalised Difference Vegetation Index (NDVI) can help identify areas of healthy vegetation. For remote sensing data such as satellite imagery, it is defined as
where \(\text{NIR}\) is the near-infrared band of the data, and \(\text{Red}\) is the red band. NDVI can take on values from -1 to 1; high values indicate healthy vegetation and negative values indicate non-vegetation (such as water).
The following code calculates the top and bottom of the fraction separately, then computes the NDVI value directly from these components. The calculated NDVI values are stored as their own data array.
Note: Before we calculate NDVI, we need to convert the data type to
float32, this will convert the nodata values in the originaluint16dataset toNaN, and therefore ignore those values in the NDVI calculation.
[11]:
# convert dataset to float32 datatype so no-data values are set to NaN
dataset = odc.algo.to_f32(dataset)
[12]:
# Calculate the components that make up the NDVI calculation
band_diff = dataset.nir - dataset.red
band_sum = dataset.nir + dataset.red
# Calculate NDVI and store it as a measurement in the original dataset
ndvi = band_diff / band_sum
After calculating the NDVI values, it is possible to plot them by adding the .plot() method to ndvi (the variable that the values are stored in). The code below will plot a single image, based on the time selected with the ndvi_time_step variable. Try changing this value to plot the NDVI map at different time steps. Do you notice any differences?
Extension 1: Sometimes, it is valuable to change the colour scale to something that helps with intuitively understanding the image. For example, the “viridis” colour map shows high values in greens/yellows (mapping to vegetation), and low values in blue (mapping to water). Try modifying the
.plot(cmap="RdYlGn")command below to usecmap="viridis"instead.
[13]:
# Set the NDVI time step to view
ndvi_time_step = 0
# This is the simple way to plot
# Note that high values are likely to be vegetation.
plt.figure(figsize=(8, 8))
ndvi.isel(time=ndvi_time_step).plot(cmap="RdYlGn", vmin=0, vmax=1)
plt.show()
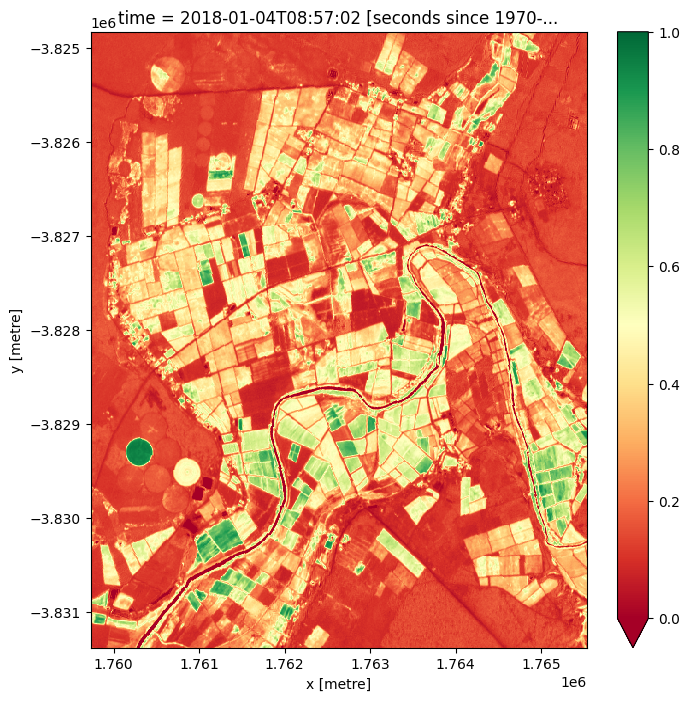
Extension 2: For the cell above, a single time step was selected using the
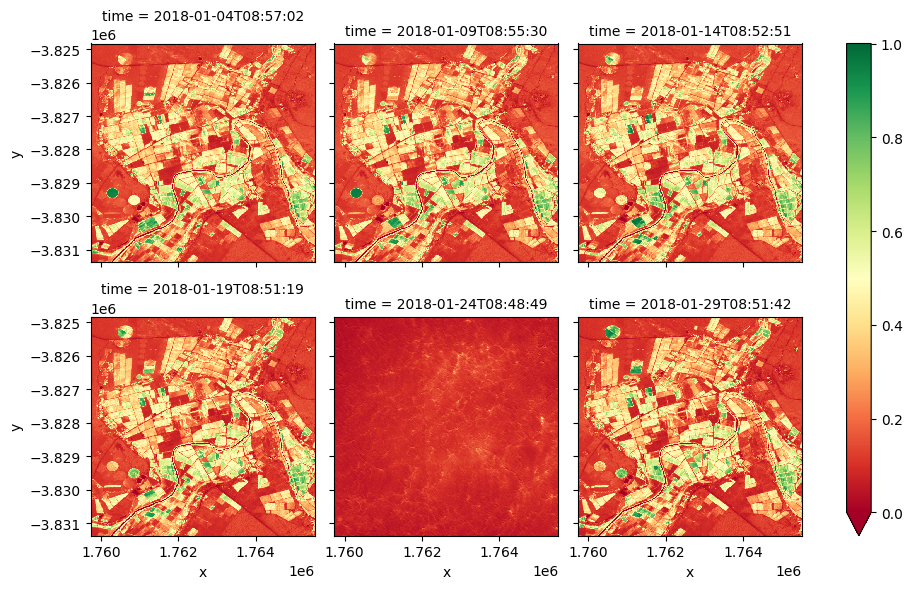
.isel()method. It is possible to plot all time steps by removing the.isel()method, and modifying the.plot()method to be.plot(col='time', col_wrap=3)wheretimeis the timesteps for the images. Plotting all of the time steps at once may make it easier to notice differences in vegetation over time.
[14]:
plt.figure(figsize=(8, 8))
ndvi.plot(col='time', cmap="RdYlGn", vmin=0, vmax=1, col_wrap=3)
plt.show()
<Figure size 800x800 with 0 Axes>
Step 5: Exporting data
Sometimes, you will want to analyse satellite imagery in a GIS program, such as QGIS. The write_cog() command from the Open Data Cube library allows loaded data to be exported to GeoTIFF, a commonly used file format for geospatial data. This example export an image based on the time_step provided. for more information on exporting multiple images check Exporting GeoTIFFS notebook > Note: the saved file will appear in the same
directory as this notebook, and it can be downloaded from here for later use.
[15]:
# You can change the name from example,tiff to your prefered name, if you like.
filename = "example.tif"
write_cog(geo_im=dataset.isel(time=time_step).to_array(), fname=filename, overwrite=True)
[15]:
PosixPath('example.tif')
Recommended next steps
For this notebook
Many of the variables used in this analysis are configurable. We recommend returning to the beginning of the notebook and re-running the analysis with a different location, dates, measurements, and so on. This will help give you more understanding for running your own analysis. If you didn’t try the extension activities the first time, try and work on these when you run through the notebook again.
For other notebooks
This is the fifth notebook in the beginner’s guide; if anything was unclear, we recommend revising the relevant notebook:
Performing a basic analysis (this notebook)
Once you have completed the above tutorials, join advanced users in exploring:
The “Datasets” directory in the repository, where you can explore DE Africa products in depth.
The “Frequently used code” directory, which contains a recipe book of common techniques and methods for analysing DE Africa data.
The “Real-world examples” directory, which provides more complex workflows and analysis case studies.
Additional information
License: The code in this notebook is licensed under the Apache License, Version 2.0. Digital Earth Africa data is licensed under the Creative Commons by Attribution 4.0 license.
Contact: If you need assistance, please post a question on the Open Data Cube Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here). If you would like to report an issue with this notebook, you can file one on
Github.
Compatible datacube version:
[16]:
print(datacube.__version__)
1.8.15
Last Tested:
[17]:
from datetime import date
print(date.today())
2023-08-11